本文围绕草莓生长阶段识别展开,采用深度学习方式,将其作为四分类问题(生长期、开花期、结果期、成熟期)。使用讯飞挑战赛数据集,基于ResNet50模型训练,经数据加载、划分、预处理等步骤,10轮训练后准确率达0.9910,能精准识别草莓生长阶段,可用于生成测试集预测结果。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

作物生长期自动识别是精准农业支持技术的核心部分之一,农作物的生长态势,事关农事生产的整个过程,因此通过农作物不同时期图片,对农作物进行合理的农作物生产态势检测,对于农业生产是十分有必要的。通过分析农作物生长情况,最大程度地判断农作物生长态势,合理调配生产资源,为农作物生产管理人员或管理决策者提供及时可靠的长势信息,便于及时采集有效的田间管理措施,对农作物产量进行准确预估,为我国人民的生存条件和粮食安全提供保障。
草莓是一种结果快、繁殖易、周期短、效益高的经济作物。对土壤理化性状要求较严,对养分非常敏感,施肥过多或者不足都会给草莓的生长发育以及产量和品质带来严重的影响。草莓扎根浅,但是根系还是很发达的。在草莓倒栽成活之后,浇水上肥料必须供应到位。尤其是在开花前和壮果这两个阶段,水肥的管理一定要引起足够的重视。
草莓生长阶段大致可以分为以下几个阶段:生长期、开花期、结果期、成熟期。为了实时准确地识别草莓不同的生长期,获取草莓生长信息,采用深度学习方式实现这一过程。整体思路是依据草莓不同生长阶段的差异将其看做为一个图像四分类问题,分别为生长期、开花期、结果期、成熟期,制作不同生长阶段的数据集,搭建神经网络实现对草莓图片的生长分类。
(1) 此次训练的数据集来源讯飞农作物生长情况识别挑战赛,该数据集所选植物全为某品种草莓,数据集不建议商业用途使用。 http://challenge.xfyun.cn/topic/info?type=crop
(2) 数据集目录
data666
├── train
├── test
│ ├── testA
├── train.csv
Resnet是残差网络(Residual Network)的缩写,该系列网络广泛用于目标分类等领域以及作为计算机视觉任务主干经典神经网络的一部分,典型的网络有resnet50, resnet101等。Resnet网络的证明网络能够向更深(包含更多隐藏层)的方向发展。
随着 CNN 的不断发展,为了获取深层次的特征,卷积的层数也越来越多。一开始 Le Net 网络只有 5 层,接着 AlexNet 为 8 层,后来 VggNet 网络包含了 19层,GoogleNet 已经有了 22 层。但通过增加网络层数的方法来增强网络的学习能力的方法并不总是可行的,因为网络层数到达一定的深度之后,再增加网络层数,那么网络就会出现随机梯度消失的问题,也会导致网络的准确率下降。为了解决这一问题,传统的方法是采用数据初始化和正则化的方法,这解决了梯度消失的问题,但是网络准确率的问题并没有改善。而残差网络的出现可以解决梯度问题,而网络层数的增加也使其表达的特征也更好,相应的检测或分类的性能更强,再加上残差中使用了 1×1 的卷积,这样可以减少参数量,也能在一定程度上减少计算量。
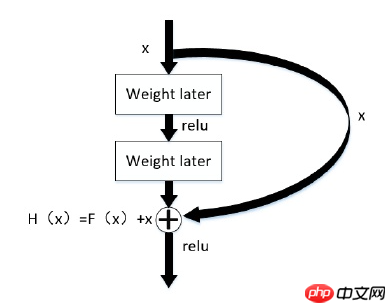
Res Net 网络的关键就在于其结构中的残差单元,如下图所示,在残差网络单元中包含了跨层连接,图中的曲线可以将输入直接跨层传递,进行了同等映射,之后与经过卷积操作的结果相加。假设输入图像为 x,输出为H(x),中间经过卷积之后的输出为F(x)的非线性函数,那最终的输出为H(x)= F(x)+x,这样的输出仍然可以进行非线性变换,残差指的是“差”,也就是F(x),而网络也就转化为求残差函数F(x)=H(x)-x,这样残差函数要比F(x) = H(x)更加容易优化。
原数据集提供了草莓处于营养生长阶段的图片,其中包含有作物图片及生长情况标签。根据训练集进行训练,对测试集数据进行标定,判断所标定的作物处于何种生长情况之下。草莓生长阶段大致可以分为以下几个阶段:生长期、开花期、结果期、成熟期。在标签中用数字表示,如下:
0,草莓生长期
1,草莓开花期
2,草莓结果期
3,草莓成熟期

数据集上传后解压,为避免后续重复运行,解压后注释。
通过 pandas 包计算各类别的数据量并绘制直方图。统计出每个类别的数量,查看训练集的数据分布情况。数据加载同时对标签文件进行打乱操作。根目录文件1.jpg是生成的类别-数目表。
In [1]#!unzip -oq /home/aistudio/data/data104406/data666.zipIn [2]
import osimport pandas as pdimport numpy as npfrom PIL import Image#from sklearn.utils import shuffleimport warnings
warnings.filterwarnings("ignore")
In [3]
df = pd.read_csv('data666/train.csv')
df = df.sample(frac=1).reset_index(drop=True)
df.to_csv('train.csv',header=1,index=0 )
In [4]
d=df['label'].hist().get_figure()
d.s*efig('1.jpg')
训练集 —— 用于模型拟合的数据样本。
验证集 —— 是模型训练过程中单独留出的样本集,它可以用于调整模型的超参数和用于对模型的能力进行初步评估。 通常用来在模型迭代训练时,用以验证当前模型泛化能力(准确率,召回率等),以决定是否停止继续训练。
 简小派
简小派
简小派是一款AI原生求职工具,通过简历优化、岗位匹配、项目生成、模拟面试与智能投递,全链路提升求职成功率,帮助普通人更快拿到更好的 offer。
 123
查看详情
123
查看详情
 In [5]
In [5]
import paddleimport paddle.nn as nnfrom paddle.io import Datasetimport paddle.vision.transforms as Timport paddle.nn.functional as Ffrom paddle.metric import AccuracyIn [6]
# 划分训练集和校验集df = pd.read_csv('train.csv')
all_size = len(df)
train_size = int(all_size * 0.8)
train_image_list = df[:train_size]
val_image_list = df[train_size:]
train_image_path_list = df['image'].values
label_list = df['label'].values
label_list = paddle.to_tensor(label_list, dtype='int64')
train_label_list = paddle.nn.functional.one_hot(label_list, num_classes=4)
val_image_path_list = val_image_list['image'].values
val_label_list = val_image_list['label'].values
val_label_list = paddle.to_tensor(val_label_list, dtype='int64')
val_label_list = paddle.nn.functional.one_hot(val_label_list, num_classes=4)
图片需要进行预处理的原因:
数据增强:对训练样本进行预处理,可以增加数据的多样性。例如通过旋转、镜像、裁切等手段,将图片的空间多样性呈现出来,据此训练出来的模型也将具有更好的鲁棒性;
数据归一化:预处理可以将不同规格的数据转换成相同规格的训练数据,最典型的的例子就是图片的尺寸归一化。
压缩数据体积:预处理还可以减小训练数据的尺寸。
In [7]# 定义数据预处理data_transforms = T.Compose([
T.Resize(size=(224, 224)),
T.RandomHorizontalFlip(224),
T.RandomVerticalFlip(224),
T.Transpose(), # HWC -> CHW
T.Normalize(
mean=[0, 0, 0], # 归一化
std=[255, 255, 255],
to_rgb=True)
])
Dataset 类是paddle中图像数据中最为重要的一个类,也是所有数据集加载类中应该继承的父类。其中,Dataset类中私有成员函数必须被重载,否则将触发错误提示。
def __init__(self): 主要是数据获取,如:某文件中获取; def __len__(self): 整个数据集的长度; def __getitem__(self,index): 编写支持数据集索引的函数;
DataLoader 是用来处理模型输入数据的一个工具,并在数据集上提供单线程或多线程(num_workers)的可迭代对象。
https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/io/Dataset_cn.html#dataset https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/io/DataLoader_cn.htmlIn [8]
# 构建Datasetclass MyDataset(paddle.io.Dataset):
"""
步骤一:继承paddle.io.Dataset类
"""
def __init__(self, train_img_list, val_img_list,train_label_list,val_label_list, mode='train'):
"""
步骤二:实现构造函数,定义数据读取方式,划分训练和测试数据集
"""
super(MyDataset, self).__init__()
self.img = []
self.label = [] # 借助pandas读csv的库
self.train_images = train_img_list
self.test_images = val_img_list
self.train_label = train_label_list
self.test_label = val_label_list if mode == 'train': # 读train_images的数据
for img,lab in zip(self.train_images, self.train_label):#并行遍历for x,y in zip(list1,list2)
self.img.append('data666/train/'+img)
self.label.append(lab) else: # 读test_images的数据
for img,lab in zip(self.test_images, self.test_label):
self.img.append('data666/train/'+img)
self.label.append(lab) def load_img(self, image_path):
image = Image.open(image_path).convert('RGB') return image def __getitem__(self, index):
"""
步骤三:实现__getitem__方法,定义指定index时如何获取数据,并返回单条数据(训练数据,对应的标签)
"""
image =  self.load_img(self.img[index])
label = self.label[index]
return data_transforms(image), paddle.nn.functional.label_smooth(label) def __len__(self):
"""
步骤四:实现__len__方法,返回数据集总数目
"""
return len(self.img)
self.load_img(self.img[index])
label = self.label[index]
return data_transforms(image), paddle.nn.functional.label_smooth(label) def __len__(self):
"""
步骤四:实现__len__方法,返回数据集总数目
"""
return len(self.img)
In [9]
#train_loadertrain_dataset = MyDataset(train_img_list=train_image_path_list, val_img_list=val_image_path_list, train_label_list=train_label_list, val_label_list=val_label_list, mode='train')
train_loader = paddle.io.DataLoader(train_dataset, places=paddle.CPUPlace(), batch_size=32, shuffle=True, num_workers=0)#val_loaderval_dataset = MyDataset(train_img_list=train_image_path_list, val_img_list=val_image_path_list, train_label_list=train_label_list, val_label_list=val_label_list, mode='test')
val_loader = paddle.io.DataLoader(train_dataset, places=paddle.CPUPlace(), batch_size=32, shuffle=True, num_workers=0)# paddle.io.DataLoader()
# dataset: 加载数据,此参数必须是 paddle.io.Dataset
# places: 数据需要放置到的Place列表。在静态图和动态图模式中,此参数均必须设置。在动态图模式中,此参数列表长度必须是1。默认值为None
# CPUPlace 是一个设备描述符,指定 CPUPlace 则 Tensor 将被自动分配在该设备上,并且模型将会运行在该设备上。
# batch_size: 每mini-batch中样本个数
# shuffle: 生成mini-batch索引列表时是否对索引打乱顺序
# num_workers: 用于加载数据的子进程个数,若为0即为不开启子进程,在主进程中进行数据加载。默认值为0
https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/vision/models/resnet50_cn.html#resnet50
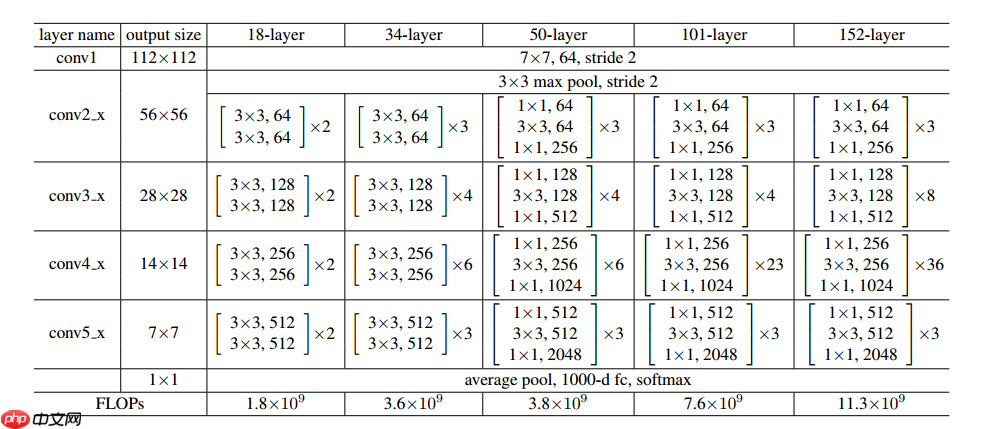
ResNet在2015年被提出,在ImageNet比赛classification任务上获得第一名,因为它“简单与实用”并存,之后很多方法都建立在ResNet50或者ResNet101的基础上完成的,检测,分割,识别等领域里得到广泛的应用。它使用了一种连接方式叫做“shortcut connection”,顾名思义,shortcut就是“抄近道”的意思。首先,ResNet的官方代码中一共有5种不同深度的结构,深度分别为18、34、50、101、152(各种网络的深度指的是“需要通过训练更新参数”的层数,如卷积层,全连接层等)。图是论文里给出每种ResNet的具体结构:
from paddle.vision.models import resnet50 model_resnet50 = paddle.vision.models.resnet50(pretrained=False, num_classes=4) model = paddle.Model(model_resnet50)#model.summary((1,3,224,224))#打印
在组建好网络结构后,一般会想去对网络结构进行一下可视化,逐层的去对齐一下网络结构参数,看看是否符合预期。这里可以通过Model.summary接口进行可视化展示。另外,summary接口有两种使用方式,Model.summary这种配套paddle.Model封装使用的接口外,还有一套配合没有经过paddle.Model封装的方式来使用。可以直接将实例化好的Layer子类放到paddle.summary接口中进行可视化呈现。为保持ResNet50网络结构复杂,输出太长,这里注释掉,取消注释可以看到如下图的网络结构。
model.summary()部分截图

optimizer优化器:机器学习的任务就是优化参数使之达到最合适的值,同时也就是时损失函数达到最小。损失函数即目标函数的值与真实值的差值函数,实际上就是欲优化参数的函数。而优化器的任务就是在每一个epoch中计算损失函数的梯度,进而更新参数。最常用的是Adam优化器,有着收敛速度快、调参容易等优点。
Loss: CrossEntropyLoss():交叉熵损失函数,交叉熵描述了两个概率分布之间的距离,当交叉熵越小说明二者之间越接近。
Acc:准确率
In [11]optim = paddle.optimizer.Adam(learning_rate=0.0003, parameters=model.parameters())
model.prepare(
optim,
paddle.nn.CrossEntropyLoss(soft_label=True),
Accuracy()
)
model.fit(train_loader,
val_loader,
epochs=10,
batch_size=32,
verbose=1,
)
The loss value printed in the log is the current step, and the metric is the *erage value of previous steps. Epoch 1/10
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:77: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working return (isinstance(seq, collections.Sequence) and
step 18/18 [==============================] - loss: 0.7781 - acc: 0.5081 - 364ms/step Eval begin... step 18/18 [==============================] - loss: 0.9258 - acc: 0.5117 - 343ms/step Eval samples: 557 Epoch 2/10 step 18/18 [==============================] - loss: 0.5960 - acc: 0.7594 - 341ms/step Eval begin... step 18/18 [==============================] - loss: 1.0874 - acc: 0.6338 - 329ms/step Eval samples: 557 Epoch 3/10 step 18/18 [==============================] - loss: 0.7425 - acc: 0.8025 - 340ms/step Eval begin... step 18/18 [==============================] - loss: 0.9822 - acc: 0.7576 - 333ms/step Eval samples: 557 Epoch 4/10 step 18/18 [==============================] - loss: 0.6438 - acc: 0.8456 - 334ms/step Eval begin... step 18/18 [==============================] - loss: 0.9294 - acc: 0.7433 - 331ms/step Eval samples: 557 Epoch 5/10 step 18/18 [==============================] - loss: 0.7404 - acc: 0.8941 - 337ms/step Eval begin... step 18/18 [==============================] - loss: 1.2472 - acc: 0.9084 - 336ms/step Eval samples: 557 Epoch 6/10 step 18/18 [==============================] - loss: 1.0283 - acc: 0.8941 - 340ms/step Eval begin... step 18/18 [==============================] - loss: 0.6345 - acc: 0.8707 - 333ms/step Eval samples: 557 Epoch 7/10 step 18/18 [==============================] - loss: 0.4836 - acc: 0.8977 - 332ms/step Eval begin... step 18/18 [==============================] - loss: 0.6376 - acc: 0.9174 - 325ms/step Eval samples: 557 Epoch 8/10 step 18/18 [==============================] - loss: 0.4775 - acc: 0.9425 - 346ms/step Eval begin... step 18/18 [==============================] - loss: 0.4299 - acc: 0.9641 - 343ms/step Eval samples: 557 Epoch 9/10 step 18/18 [==============================] - loss: 0.7872 - acc: 0.9731 - 334ms/step Eval begin... step 18/18 [==============================] - loss: 0.4603 - acc: 0.9874 - 326ms/step Eval samples: 557 Epoch 10/10 step 18/18 [==============================] - loss: 0.4340 - acc: 0.9838 - 333ms/step Eval begin... step 18/18 [==============================] - loss: 0.4039 - acc: 0.9910 - 341ms/step Eval samples: 557
每个batch32张,经过epochs=10的运算后结果 loss: 0.4039, acc: 0.9910。注:代码多次运行,acc最高1.0000,最低的一次也有0.9854。
In [12]model.s*e('Res', False) # s*e for inference
In [13]
model.prepare()
因为采用的数据集很小,为比赛用的数据。train文件夹有557张图片共4个类别,由于数据量太小按照4:1划分训练集和校验集。testA文件夹为4分类无标签注释的230张图片,用于模型预测生成csv文件提交比赛结果使用。因此在此次预测使用上传的sample.zip文件,里面包含着4张不同类别图片,用于本次模型预测使用。
In [14]#上传样本图片并解压#!unzip -oq /home/aistudio/sample.zipIn [15]
def load_image(file):
# 打开图片
im = Image.open(file) # 将图片调整为跟训练数据一样的大小 224*224
im = im.resize((224, 224), Image.ANTIALIAS) # 建立图片矩阵 类型为float32
im = np.array(im).astype(np.float32) # 矩阵转置
im = im.transpose((2, 0, 1))
# 将像素值从[0-255]转换为[0-1]
im = im /255.0
im = np.expand_dims(im, axis=0) # 保持和之前输入image维度一致
print('im_shape的维度:',im.shape) return im
In [16]
import matplotlib.pyplot as plt# 定义标签,列表形式label_list = [ "草莓生长期", "草莓开花期", "草莓结果期", "草莓成熟期"]## 读入测试图infer_path='/home/aistudio/sample/test_7.jpg'img = Image.open(infer_path)
plt.imshow(img)
plt.show()
# 载入预测图infer_img = load_image(infer_path)# 图片转数组infer_img=np.array(infer_img).astype('float32')
infer_img = np.expand_dims(infer_img, axis=0)#增加维度,否则报错# 预测result = model.predict(infer_img)# 输出结果print('results',result)print("infer results: %s" % label_list[np.argmax(result[0][0])])
<Figure size 432x288 with 1 Axes>
im_shape的维度: (1, 3, 224, 224) Predict begin... step 1/1 [==============================] - 38ms/step
Predict samples: 1
results [(array([[-1.4515489 , 2.497146 , -0.80620635, 1.2606131 ]],
dtype=float32),)]
infer results: 草莓开花期
由上可以看到样图为开花时期图,输出结果如下,符合预测结果。
Predict samples: 1
results [(array([[-2.7469335, 3.0794125, -0.8493489, -1.1421994]], dtype=float32),)]
infer results: 草莓开花期
def load_image(img_path):
'''
预测图片预处理
'''
img = Image.open(img_path).convert('RGB')
#resize
img = img.resize((224, 224), Image.BILINEAR) #双线性插值
img = np.array(img).astype('float32') # HWC to CHW
img = img.transpose((2, 0, 1))
#Normalize
img = img / 255 #像素归一
return imgdef infer_img(path, model_file_path, use_gpu):
'''
模型预测
'''
paddle.set_device('gpu:0') if use_gpu else paddle.set_device('cpu')
model = paddle.jit.load(model_file_path)
model.eval()
#对预测图片进行预处理
infer_imgs = []
infer_imgs.append(load_image(path))
infer_imgs = np.array(infer_imgs)
label_list = ['0:生长', '1:开花', '2:结果', '3:成熟']
label_pre = [] for i in range(len(infer_imgs)):
data = infer_imgs[i]
dy_x_data = np.array(data).astype('float32')
dy_x_data = dy_x_data[np.newaxis,:, : ,:]#增加维度
img = paddle.to_tensor(dy_x_data)
out = model(img)
lab = np.argmax(out.numpy()) #argmax():返回最大数的索引
label_pre.append(lab)
return label_pre
In [18]
img_list = os.listdir('/home/aistudio/data666/test/testA')
img_list.sort(key=lambda x: int(x[5:-4])) #将‘.jpg’左边的字符转换成整数型进行排序
In [19]
pre_list = []for i in range(len(img_list)):
pre_list.append(infer_img(path='data666/test/testA/' + img_list[i], use_gpu=True, model_file_path="Res")[0])
In [20]
img = pd.DataFrame(img_list)
img = img.rename(columns = {0:"image"})
img['label'] = pre_list
img.to_csv('submit_Res.csv', index=False)
对testA的230张图进行预测并输出结果csv,可以看到如下图的输出结果
以上就是【AI达人训练营】基于飞桨高层 API 实现草莓生长阶段识别的详细内容,更多请关注其它相关文章!
# 层数
# 公寓营销推广语怎么写的
# 网上营销推广技术
# 浦东seo优化公司
# 网站放有淘宝链接seo
# 北京网站建设网站优化
# seo优化专业术语
# 张家口营销推广加盟
# 关键词排名服务哪家好
# 郑州关键词排名2021
# 建设人才网站官网
# 迭代
# 可以看到
# 子类
# 一言
# python
# 加载
# 成熟期
# 训练营
# 达人
# 中文网
# type
# fig
# udio
# red
# 可迭代对象
# csv文件
# ai
# 工具
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
2025智源大会AI安全话题备受关注,《人机对齐》新书首发
聚焦人工智能大模型、AIGC 徐汇十余场重磅论坛等你来
如何获得元宇宙的第一个属于自己的空间
掌阅科技申请阅爱聊商标 掌阅科技申请AI相关商标
业内领先 四川大学华西第四医院甲状腺乳腺外科成功进入手术机器人时代
彬州市第三届青少年机器人创新大赛成功举办
Meta 发布 Voicebox AI 模型:可生成音频信息,用于 NPC 对话等
AYANEO 安卓掌机 Pocket AIR 配置公布:天玑 1200 + 5.5 英寸屏
当一个网站的内容被 AI 完全接管
“风乌”气象大模型科学家团队:用AI预报极端天气未来不是梦!
苹果头显降临,AI虚拟人的救星还是流星?
BLIP-2、InstructBLIP稳居前三!十二大模型,十六份榜单,全面测评「多模态大语言模型」
微软在 Build 大会上宣布的新 Microsoft Store AI Hub 现已开始推出
【趋势周报】全球人工智能产业发展趋势:OpenAI向美国专利局提交“GPT-5”商标申请
MiracleVision视觉大模型
GPT-4最全攻略来袭!OpenAI官方发布,六个月攒下来的使用经验都在里面了
加强高质量数据供应能力,促进通用人工智能大模型领域的创新
13 个提高生产力的 AI 工具
跑不动的元宇宙,虚拟世界比现实更冷酷
马斯克发推讽刺人工智能:机器学习的本质就是统计
测试框架-安全和自动驾驶
上海发布“元宇宙关键技术攻关行动方案”,加快 AIGC 等突破
AI和ML推动联网设备的增长
微软和谷歌面临的人工智能困境:需要投入大量资金才能获得盈利
美图影像节演讲实录:191次提及AI,发布7款影像生产力工具
马斯克WAIC2025演讲全文:AI将对人类文明产生深远影响
华为云发布华为云盘古模型3.0和升腾AI云服务,亮点亮相2025华为开发者大会
独家视角:首次展示有人与无人协同打击的7000米高空察打一体无人机
助力人工智能产业高质量发展 龙岗区算法训练基地正式启用
能抓取玻璃碎片、水下透明物,清华提出通用型透明物体抓取框架,成功率极高
智能机器人与话剧的完美结合:宇树四足机器人B1助力《骆驼祥子》重现经典
网易加速行业AI大模型应用,将覆盖100多个应用场景
世界人工智能大会|“AI领航,共筑未来”高端保险论坛成功举办
人工智能和神经网络有什么联系与区别?
中国移动副总经理高同庆:打造人工智能时代的智能服务运营新范式
埃森哲俞毅:AI时代我们需要新的“摩尔定律”
OpenAI CEO 阿尔特曼到访日本,对全球 AI 协调合作表示乐观
AI新视野,增长新势能,伙伴云受邀出席笔记侠创业讲真话AI峰会
商业智能决策技术助力降本增效,世界人工智能大会举办商业AI高峰论坛
日入400万,第一批AI骗子已上岗
微软向美国政府提供GPT的大模型,安全性如何保证?
《上古卷轴5》AI高清材质包优化游戏中所有怪物
AI证件照生成器:实际测试中AI软件展现了绝无仅有的强大效能
再度重仓 AI 赛道,SaaS 巨头 Salesforce 扩大 AIGC 风投基金规模
两小时就能超过人类!DeepMind最新AI速通26款雅达利游戏
大疆 Air 3 无人机售价和实物照片曝光
iPhone两秒出图,目前已知的最快移动端Stable Diffusion模型来了
热点资讯:家乐福推出聊天机器人;米哈游2025年营收273.4亿元…
云米Smart 2E AI立式空调开启预售:新三级能效,到手价3899元
生成式AI与云结合,机遇与挑战并存
2025-07-29

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。

 self.load_img(self.img[index])
label = self.label[index]
return data_transforms(image), paddle.nn.functional.label_smooth(label) def __len__(self):
"""
步骤四:实现__len__方法,返回数据集总数目
"""
return len(self.img)
self.load_img(self.img[index])
label = self.label[index]
return data_transforms(image), paddle.nn.functional.label_smooth(label) def __len__(self):
"""
步骤四:实现__len__方法,返回数据集总数目
"""
return len(self.img)