本文介绍基于Unet+++实现脊柱MRI定位的项目。因手动选择锥体截面耗时易错,项目将3D数据映射为2D,用深度学习定位L3水平中间轴向切片。处理数据集为PNG格式,定义网络、数据读取类,经训练和验证,测试集平均定位误差为4.0。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

目前AIstudio已经有许多基于Unet的分割项目,本项目主要介绍分割网络的另外的应用场景,希望对大家的研究有所启发。
在医学领域,经常需要分析患某种疾病后身体脂肪含量的变化,一般通过选择某个锥体的截面来估计全身的脂肪含量。 常规的方法是通过手动从几百张影像中选择需要的切片(一般为L3),这种方法即耗时又枯燥,稍不注意还容易出错。
在选择到目标切片后,随后进行手动分割,然后使用相关公式估计全身的脂肪含量。
切片选择相关的研究大部分都是在3D数据上对所有的锥体进行标注,但是这个任务中不需要其他的锥体的具体位置,而且3D数据对设备的要求更高。
因此,目前的一个解决方案是通过将三维数据映射使用MLP映射到二维,然后使用深度学习进行定位。
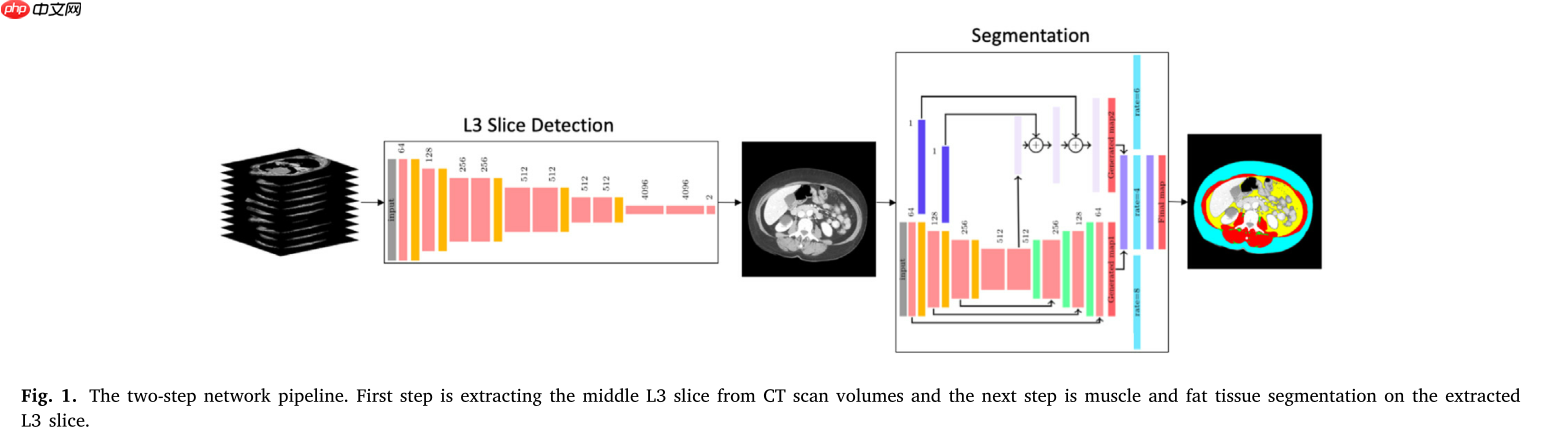
计算机断层扫描(CT)成像广泛用于研究身体成分,即肌肉和脂肪组织的比例,应用于营养或化疗剂量设计等领域。
特别是,来自固定位置的轴向CT切片通常用于身体成分分析。然而,如果手动进行,从数百张切片中手动选择是非常繁琐的操作。
本项目的目的是从全身或部分身体扫描体积中自动找到L3水平的中间轴向切片。
使用公开数据集---磁共振图像脊柱结构多类别三维自动分割数据集,该数据集是一个分割数据集,数据格式是nii.gz。分割磁共振T2腰椎矢状位,加背景一共20类。
椎体有S、L5、L4、L3、L2、L1、T12、T11、T10、T9,椎间盘有L5/S, L4/L5, L3/L4, L2/L3, L1/L2, T12/L1, T11/T12, T10/T11, T9/T10
我们对该数据集进行二次处理,包括MLP,剪裁等,建立自己的实验数据集。

# 数据集解压#!unzip -o data/data81211/train.zip -d /home/aistudio/work/In [ ]
#安装 nii处理工具 SimpleITK 和分割工具paddleSeg!pip install SimpleITK !pip install paddleseg !pip install nibabelIn [ ]
#导入常用库import osimport randomimport numpy as npimport matplotlib.pyplot as pltfrom random import shuffleimport cv2import paddlefrom PIL import Imageimport shutilimport reimport globimport reimport SimpleITK as sitk
使用分割的思路来解决定位问题,多次实验将目标位置宽度设置为7个像素效果最佳。
slices的选择与窗宽窗位需要自己根据数据调整
from PIL import Imagedef read_intensity(path):
sitkImage = sitk.ReadImage(path)
intensityWindowingFilter = sitk.IntensityWindowingImageFilter() #转换成0到255之间
intensityWindowingFilter.SetOutputMaximum(255)
intensityWindowingFilter.SetOutputMinimum(0) if 'mask' not in path: #调窗宽窗位
intensityWindowingFilter.SetWindowMaximum(1900)
intensityWindowingFilter.SetWindowMinimum(-300)
sitkImage = intensityWindowingFilter.Execute(sitkImage) return sitkImage
filename = r'data//Data_L3Location//'if not os.path.exists(filename):
os.mkdir(filename)
path_ ='work/train/MR/*.nii.gz'dcm_list_ = glob.glob(path_)
s_s = 4 # 开始slices位置s_e = 6 # 结束slices位置idx = 0for i,_ in enumerate(dcm_list_):
item = dcm_list_[i]
NUM = re.findall("\d+",item)[0] print(i,idx)
path_mri ='work/train/MR/Case' + str(NUM) + '.nii.gz'
path_mask ='work/train/Mask/mask_case' + str(NUM) + '.nii.gz'
mri = read_intensity(path_mri)
mask = read_intensity(path_mask)
npdata = sitk.GetArrayFromImage(mri)
npmask = sitk.GetArrayFromImage(mask)
npdata = cv2.flip(np.transpose(npdata[:,:,:],(1,2,0)),0)
npmask = cv2.flip(np.transpose(npmask[:,:,:],(1,2,0)),0)
h,w = np.max(npdata[:,:,s_s:s_e],2).shape if h<768 or w<696: continue
else:
scale = 0.3
npdata[:,:int(scale*npdata.shape[1]),:] = 0
npdata[:,int((1-scale)*npdata.shape[1]):,:] = 0
npdata_max = np.max(npdata[:,:,s_s:s_e],2) # 最大值压缩
npdata_mean = np.mean(npdata[:,:,s_s:s_e],2) # 均值压缩
npdata_mix = 0.5*(npdata_max+npdata_mean) # 混合压缩
npmask_ = np.max(npmask[:,:,s_s:s_e],2)
npmask_13 = npmask_.copy()
npmask_14 = npmask_.copy() # 13 / 14 L3
npmask_13[npmask_ != 13] = 0
npmask_14[npmask_ != 14] = 0
npmask_13[npmask_13 == 13] = 255
npmask_14[npmask_14 == 14] = 255
mid_13 = np.where(np.max(npmask_13,1) == 255)[0].mean() # 获取13的中间行索引
mid_14 = np.where(np.max(npmask_14,1) == 255)[0].mean() # 获取14的中间行索引
mid_index = int((mid_13+mid_14)*0.5) # 获取 L3锥体的中间行索引
# 对数据进行截断
npdata_max = npdata_max[:768,184:696] # 880/2 = 440 - 256 = 184 目的是取中间的512列
npdata_mix = npdata_mix[:768,184:696] # 880/2 = 440 - 256 = 184 目的是取中间的512列
npdata_mean = npdata_mean[:768,184:696] # 880/2 = 440 - 256 = 184 目的是取中间的512列
mask = np.zeros_like(npdata_max)
mask[mid_index-3:mid_index+3,int(scale*mask.shape[1]):int((1-scale)*mask.shape[1])] = 255 # 标注 L3锥体的中间位置
# 对数据两侧进行切除处理
img_ma = Image.fromarray(np.uint8(npdata_max))
img_mi = Image.fromarray(np.uint8(npdata_mix))
img_me = Image.fromarray(np.uint8(npdata_mean))
img_la = Image.fromarray(np.uint8(mask))
img_ma.s*e(filename+'max_'+str(idx) +'.png')
img_mi.s*e(filename+'mix_'+str(idx) +'.png')
img_me.s*e(filename+'mean_'+str(idx) +'.png')
img_la.s*e(filename+'label_'+str(idx) +'.png')
idx = idx+1
import paddlefrom paddle.io import Datasetimport paddleseg.transforms as Timport matplotlib.image as mpimg # mpimg 用于读取图片import numpy as np# 重写数据读取类class MRILocationDataset(Dataset):
def __init__(self,mode = 'train',transform =None):
label_path_ ='data/Data_L3Location/label_*.png'
self.png_list_ = glob.glob(label_path_)
self.transforms = transform
self.mode = mode # 选择前80%训练,后20%测试
if self.mode == 'train':
self.png_list_ = self.png_list_[:int(0.8*len(self.png_list_))] else:
self.png_list_ = self.png_list_[int(0.8*len(self.png_list_)):] def __getitem__(self, index):
item = self.png_list_[index]
mask = mpimg.imread(item) # 读取和代码处于同一目录下的 lena.png
mix_ = mpimg.imread(item.replace('label','mix'))
max_ = mpimg.imread(item.replace('label','max'))
mean_ = mpimg.imread(item.replace('label','mean'))
mask = np.expand_dims(mask, axis=0)
mix_ = np.expand_dims(mix_, axis=0)
max_ = np.expand_dims(max_, axis=0)
mean_ = np.expand_dims(mean_, axis=0)
data = np.concatenate((mix_,max_,mean_),axis=0) if self.transforms:
data ,mask= self.transforms(data,mask)
return data ,mask def __len__(self):
return len(self.png_list_)
In [ ]
# 预览数据dataset = MRILocationDataset(mode='train')print('=============train dataset=============')
imga, imgb = dataset[4]print(imga.shape,imgb.shape)
imga = imga[0]*255imga = Image.fromarray(imga)#当要保存的图片为灰度图像时,灰度图像的 numpy 尺度是 [1, h, w]。需要将 [1, h, w] 改变为 [h, w]imgb = np.squeeze(imgb)
plt.figure(figsize=(12, 6))
plt.subplot(1,2,1),plt.xticks([]),plt.yticks([]),plt.imshow(imga)
plt.subplot(1,2,2),plt.xticks([]),plt.yticks([]),plt.imshow(imgb)
plt.show()
=============train dataset============= (3, 768, 512) (1, 768, 512)
<Figure size 864x432 with 2 Axes>
UNet的发展
2006年Hinton大神提出了一种encoder-decoder结构,当时这个encoder-decoder结构提出的主要作用并不是分割,而是压缩图像和去噪声。输入是一幅图,经过下采样的编码,得到一串比原先图像更小的特征,相当于压缩,然后再经过一个解码,理想状况就是能还原到原来的图像。而在2015,基于此拓扑结构的FCN和UNet相继提出,其中UNet的对称结构简单易懂,效果还好,就成为了许多网络改进的范本之一。
 简小派
简小派
简小派是一款AI原生求职工具,通过简历优化、岗位匹配、项目生成、模拟面试与智能投递,全链路提升求职成功率,帮助普通人更快拿到更好的 offer。
 123
查看详情
123
查看详情

来源
ICASSP 2025 paper 《UNet 3+: A full-scale connected unet for medical image segmentation》
设计特点
全尺度连接:
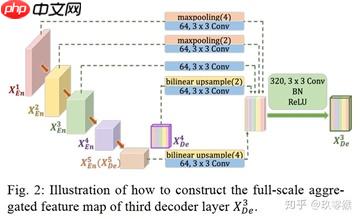
为了弥补UNet和UNet++不能精确分割图像中器官的位置和边界,UNet3+中每一个解码器都结合了全部编码器的特征,这些不同尺度的特征能够获取细粒度的细节和粗粒度的语义。UNet 3+中的每一个解码器层都融合了来自编码器中的小尺度和同尺度的特征图,以及来自解码器的da尺度的特征图,这些特征图捕获了全尺度下的细粒度语义和粗粒度语义。下图表明了第三层解码器的特征图如何构造
全尺度监督:
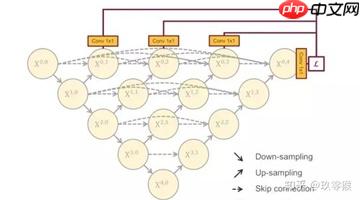
在UNet++中,已经实现了深度监督。它对生成的全分辨率特征图进行操作,即 X0,1 、X0,2、 X0,3 、X0,4后面加一个1x1的卷积核,相当于监督每个分支的UNet的输出。与UNet++对每个嵌套的子网络进行监督不同的是,在UNet3+中每一个解码器模块都有一个输出,与ground truth进行比较计算loss,从而实现全尺度的监督
分类引导模块:
为了防止非器官图像的过度分割,和提高模型的分割精度,作者通过添加一个额外的分类任务来预测输入图像是否有器官,从而实现更精准的分割。具体就是利用最丰富的语义信息,分类结果可以进一步指导每一个切分侧边输出两个步骤。首先,在argmax函数的帮助下,将二维张量转化为{0,1}的单个输出,表示有/没有目标。随后将单个分类输出与侧分割输出相乘。由于二值分类任务的简单性,该模块通过优化二值交叉熵损失函数,轻松获得准确的分类结果,实现了对非目标图像过分割的指导。
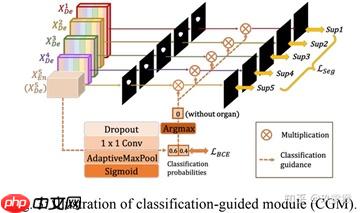
(图源知乎:玖零猴,侵删)
网络结构
与UNet和UNet++相比,UNet3+结合了多尺度特征,重新设计了跳跃连接,并利用多尺度的深度监督,UNet3+提供更少的参数,但可以产生更准确的位置感知和边界增强的分割图
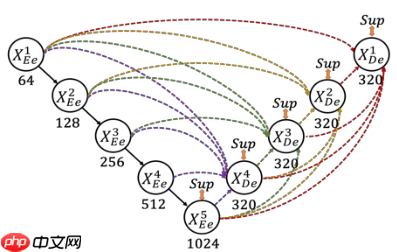
说明
pytorch版本中有UNet3+、用到了深度监督的UNet3+以及分类指导模块的UNet3+,都以在unet.py中转为paddle的版本。具体介绍还是请移步知乎:UNet3+(UNet+++)论文解读
import paddleimport paddle.nn as nnimport paddle.nn.functional as Ffrom paddle.nn import initializerdef init_weights(init_type='kaiming'):
if init_type == 'normal': return paddle.framework.ParamAttr(initializer=paddle.nn.initializer.Normal()) elif init_type == 'x*ier': return paddle.framework.ParamAttr(initializer=paddle.nn.initializer.X*ierNormal()) elif init_type == 'kaiming': return paddle.framework.ParamAttr(initializer=paddle.nn.initializer.KaimingNormal) else: raise NotImplementedError('initialization method [%s] is not implemented' % init_type)class unetConv2(nn.Layer):
def __init__(self, in_size, out_size, is_batchnorm, n=2, ks=3, stride=1, padding=1):
super(unetConv2, self).__init__()
self.n = n
self.ks = ks
self.stride = stride
self.padding = padding
s = stride
p = padding if is_batchnorm: for i in range(1, n + 1):
conv = nn.Sequential(nn.Conv2D(in_size, out_size, ks, s, p),
nn.BatchNorm(out_size),
nn.ReLU(), ) setattr(self, 'conv%d' % i, conv)
in_size = out_size else: for i in range(1, n + 1):
conv = nn.Sequential(nn.Conv2D(in_size, out_size, ks, s, p),
nn.ReLU(), ) setattr(self, 'conv%d' % i, conv)
in_size = out_size # initialise the blocks
for m in self.children():
m.weight_attr=init_weights(init_type='kaiming')
m.bias_attr=init_weights(init_type='kaiming') def forward(self, inputs):
x = inputs for i in range(1, self.n + 1):
conv = getattr(self, 'conv%d' % i)
x = conv(x) return x'''
UNet 3+
'''class UNet_3Plus(nn.Layer):
def __init__(self, in_channels=3, n_classes=1, is_deconv=True, is_batchnorm=True, end_sigmoid=True):
super(UNet_3Plus, self).__init__()
self.is_deconv = is_deconv
self.in_channels = in_channels
self.is_batchnorm = is_batchnorm
self.end_sigmoid = end_sigmoid
filters = [16, 32, 64, 128, 256] ## -------------Encoder--------------
self.conv1 = unetConv2(self.in_channels, filters[0], self.is_batchnorm)
self.maxpool1 = nn.MaxPool2D(kernel_size=2)
self.conv2 = unetConv2(filters[0], filters[1], self.is_batchnorm)
self.maxpool2 = nn.MaxPool2D(kernel_size=2)
self.conv3 = unetConv2(filters[1], filters[2], self.is_batchnorm)
self.maxpool3 = nn.MaxPool2D(kernel_size=2)
self.conv4 = unetConv2(filters[2], filters[3], self.is_batchnorm)
self.maxpool4 = nn.MaxPool2D(kernel_size=2)
self.conv5 = unetConv2(filters[3], filters[4], self.is_batchnorm) ## -------------Decoder--------------
self.CatChannels = filters[0]
self.CatBlocks = 5
self.UpChannels = self.CatChannels * self.CatBlocks '''stage 4d'''
# h2->320*320, hd4->40*40, Pooling 8 times
self.h2_PT_hd4 = nn.MaxPool2D(8, 8, ceil_mode=True)
self.h2_PT_hd4_conv = nn.Conv2D(filters[0], self.CatChannels, 3, padding=1)
self.h2_PT_hd4_bn = nn.BatchNorm(self.CatChannels)
self.h2_PT_hd4_relu = nn.ReLU() # h2->160*160, hd4->40*40, Pooling 4 times
self.h2_PT_hd4 = nn.MaxPool2D(4, 4, ceil_mode=True)
self.h2_PT_hd4_conv = nn.Conv2D(filters[1], self.CatChannels, 3, padding=1)
self.h2_PT_hd4_bn = nn.BatchNorm(self.CatChannels)
self.h2_PT_hd4_relu = nn.ReLU() # h3->80*80, hd4->40*40, Pooling 2 times
self.h3_PT_hd4 = nn.MaxPool2D(2, 2, ceil_mode=True)
self.h3_PT_hd4_conv = nn.Conv2D(filters[2], self.CatChannels, 3, padding=1)
self.h3_PT_hd4_bn = nn.BatchNorm(self.CatChannels)
self.h3_PT_hd4_relu = nn.ReLU() # h4->40*40, hd4->40*40, Concatenation
self.h4_Cat_hd4_conv = nn.Conv2D(filters[3], self.CatChannels, 3, padding=1)
self.h4_Cat_hd4_bn = nn.BatchNorm(self.CatChannels)
self.h4_Cat_hd4_relu = nn.ReLU() # hd5->20*20, hd4->40*40, Upsample 2 times
self.hd5_UT_hd4 = nn.Upsample(scale_factor=2, mode='bilinear') # 14*14
self.hd5_UT_hd4_conv = nn.Conv2D(filters[4], self.CatChannels, 3, padding=1)
self.hd5_UT_hd4_bn = nn.BatchNorm(self.CatChannels)
self.hd5_UT_hd4_relu = nn.ReLU() # fusion(h2_PT_hd4, h2_PT_hd4, h3_PT_hd4, h4_Cat_hd4, hd5_UT_hd4)
self.conv4d_1 = nn.Conv2D(self.UpChannels, self.UpChannels, 3, padding=1) # 16
self.bn4d_1 = nn.BatchNorm(self.UpChannels)
self.relu4d_1 = nn.ReLU() '''stage 3d'''
# h2->320*320, hd3->80*80, Pooling 4 times
self.h2_PT_hd3 = nn.MaxPool2D(4, 4, ceil_mode=True)
self.h2_PT_hd3_conv = nn.Conv2D(filters[0], self.CatChannels, 3, padding=1)
self.h2_PT_hd3_bn = nn.BatchNorm(self.CatChannels)
self.h2_PT_hd3_relu = nn.ReLU() # h2->160*160, hd3->80*80, Pooling 2 times
self.h2_PT_hd3 = nn.MaxPool2D(2, 2, ceil_mode=True)
self.h2_PT_hd3_conv = nn.Conv2D(filters[1], self.CatChannels, 3, padding=1)
self.h2_PT_hd3_bn = nn.BatchNorm(self.CatChannels)
self.h2_PT_hd3_relu = nn.ReLU() # h3->80*80, hd3->80*80, Concatenation
self.h3_Cat_hd3_conv = nn.Conv2D(filters[2], self.CatChannels, 3, padding=1)
self.h3_Cat_hd3_bn = nn.BatchNorm(self.CatChannels)
self.h3_Cat_hd3_relu = nn.ReLU() # hd4->40*40, hd4->80*80, Upsample 2 times
self.hd4_UT_hd3 = nn.Upsample(scale_factor=2, mode='bilinear') # 14*14
self.hd4_UT_hd3_conv = nn.Conv2D(self.UpChannels, self.CatChannels, 3, padding=1)
self.hd4_UT_hd3_bn = nn.BatchNorm(self.CatChannels)
self.hd4_UT_hd3_relu = nn.ReLU() # hd5->20*20, hd4->80*80, Upsample 4 times
self.hd5_UT_hd3 = nn.Upsample(scale_factor=4, mode='bilinear') # 14*14
self.hd5_UT_hd3_conv = nn.Conv2D(filters[4], self.CatChannels, 3, padding=1)
self.hd5_UT_hd3_bn = nn.BatchNorm(self.CatChannels)
self.hd5_UT_hd3_relu = nn.ReLU() # fusion(h2_PT_hd3, h2_PT_hd3, h3_Cat_hd3, hd4_UT_hd3, hd5_UT_hd3)
self.conv3d_1 = nn.Conv2D(self.UpChannels, self.UpChannels, 3, padding=1) # 16
self.bn3d_1 = nn.BatchNorm(self.UpChannels)
self.relu3d_1 = nn.ReLU() '''stage 2d '''
# h2->320*320, hd2->160*160, Pooling 2 times
self.h2_PT_hd2 = nn.MaxPool2D(2, 2, ceil_mode=True)
self.h2_PT_hd2_conv = nn.Conv2D(filters[0], self.CatChannels, 3, padding=1)
self.h2_PT_hd2_bn = nn.BatchNorm(self.CatChannels)
self.h2_PT_hd2_relu = nn.ReLU() # h2->160*160, hd2->160*160, Concatenation
self.h2_Cat_hd2_conv = nn.Conv2D(filters[1], self.CatChannels, 3, padding=1)
self.h2_Cat_hd2_bn = nn.BatchNorm(self.CatChannels)
self.h2_Cat_hd2_relu = nn.ReLU() # hd3->80*80, hd2->160*160, Upsample 2 times
self.hd3_UT_hd2 = nn.Upsample(scale_factor=2, mode='bilinear') # 14*14
self.hd3_UT_hd2_conv = nn.Conv2D(self.UpChannels, self.CatChannels, 3, padding=1)
self.hd3_UT_hd2_bn = nn.BatchNorm(self.CatChannels)
self.hd3_UT_hd2_relu = nn.ReLU() # hd4->40*40, hd2->160*160, Upsample 4 times
self.hd4_UT_hd2 = nn.Upsample(scale_factor=4, mode='bilinear') # 14*14
self.hd4_UT_hd2_conv = nn.Conv2D(self.UpChannels, self.CatChannels, 3, padding=1)
self.hd4_UT_hd2_bn = nn.BatchNorm(self.CatChannels)
self.hd4_UT_hd2_relu = nn.ReLU() # hd5->20*20, hd2->160*160, Upsample 8 times
self.hd5_UT_hd2 = nn.Upsample(scale_factor=8, mode='bilinear') # 14*14
self.hd5_UT_hd2_conv = nn.Conv2D(filters[4], self.CatChannels, 3, padding=1)
self.hd5_UT_hd2_bn = nn.BatchNorm(self.CatChannels)
self.hd5_UT_hd2_relu = nn.ReLU() # fusion(h2_PT_hd2, h2_Cat_hd2, hd3_UT_hd2, hd4_UT_hd2, hd5_UT_hd2)
self.Conv2D_1 = nn.Conv2D(self.UpChannels, self.UpChannels, 3, padding=1) # 16
self.bn2d_1 = nn.BatchNorm(self.UpChannels)
self.relu2d_1 = nn.ReLU() '''stage 1d'''
# h2->320*320, hd1->320*320, Concatenation
self.h2_Cat_hd1_conv = nn.Conv2D(filters[0], self.CatChannels, 3, padding=1)
self.h2_Cat_hd1_bn = nn.BatchNorm(self.CatChannels)
self.h2_Cat_hd1_relu = nn.ReLU() # hd2->160*160, hd1->320*320, Upsample 2 times
self.hd2_UT_hd1 = nn.Upsample(scale_factor=2, mode='bilinear') # 14*14
self.hd2_UT_hd1_conv = nn.Conv2D(self.UpChannels, self.CatChannels, 3, padding=1)
self.hd2_UT_hd1_bn = nn.BatchNorm(self.CatChannels)
self.hd2_UT_hd1_relu = nn.ReLU() # hd3->80*80, hd1->320*320, Upsample 4 times
self.hd3_UT_hd1 = nn.Upsample(scale_factor=4, mode='bilinear') # 14*14
self.hd3_UT_hd1_conv = nn.Conv2D(self.UpChannels, self.CatChannels, 3, padding=1)
self.hd3_UT_hd1_bn = nn.BatchNorm(self.CatChannels)
self.hd3_UT_hd1_relu = nn.ReLU() # hd4->40*40, hd1->320*320, Upsample 8 times
self.hd4_UT_hd1 = nn.Upsample(scale_factor=8, mode='bilinear') # 14*14
self.hd4_UT_hd1_conv = nn.Conv2D(self.UpChannels, self.CatChannels, 3, padding=1)
self.hd4_UT_hd1_bn = nn.BatchNorm(self.CatChannels)
self.hd4_UT_hd1_relu = nn.ReLU() # hd5->20*20, hd1->320*320, Upsample 16 times
 self.hd5_UT_hd1 = nn.Upsample(scale_factor=16, mode='bilinear') # 14*14
self.hd5_UT_hd1_conv = nn.Conv2D(filters[4], self.CatChannels, 3, padding=1)
self.hd5_UT_hd1_bn = nn.BatchNorm(self.CatChannels)
self.hd5_UT_hd1_relu = nn.ReLU() # fusion(h2_Cat_hd1, hd2_UT_hd1, hd3_UT_hd1, hd4_UT_hd1, hd5_UT_hd1)
self.conv1d_1 = nn.Conv2D(self.UpChannels, self.UpChannels, 3, padding=1) # 16
self.bn1d_1 = nn.BatchNorm(self.UpChannels)
self.relu1d_1 = nn.ReLU() # output
self.outconv1 = nn.Conv2D(self.UpChannels, n_classes, 3, padding=1) # initialise weights
for m in self.sublayers (): if isinstance(m, nn.Conv2D):
m.weight_attr = init_weights(init_type='kaiming')
m.bias_attr = init_weights(init_type='kaiming') elif isinstance(m, nn.BatchNorm):
m.param_attr =init_weights(init_type='kaiming')
m.bias_attr = init_weights(init_type='kaiming') def forward(self, inputs):
## -------------Encoder-------------
h2 = self.conv1(inputs) # h2->320*320*64
h2 = self.maxpool1(h2)
h2 = self.conv2(h2) # h2->160*160*128
h3 = self.maxpool2(h2)
h3 = self.conv3(h3) # h3->80*80*256
h4 = self.maxpool3(h3)
h4 = self.conv4(h4) # h4->40*40*512
h5 = self.maxpool4(h4)
hd5 = self.conv5(h5) # h5->20*20*1024
## -------------Decoder-------------
h2_PT_hd4 = self.h2_PT_hd4_relu(self.h2_PT_hd4_bn(self.h2_PT_hd4_conv(self.h2_PT_hd4(h2))))
h2_PT_hd4 = self.h2_PT_hd4_relu(self.h2_PT_hd4_bn(self.h2_PT_hd4_conv(self.h2_PT_hd4(h2))))
h3_PT_hd4 = self.h3_PT_hd4_relu(self.h3_PT_hd4_bn(self.h3_PT_hd4_conv(self.h3_PT_hd4(h3))))
h4_Cat_hd4 = self.h4_Cat_hd4_relu(self.h4_Cat_hd4_bn(self.h4_Cat_hd4_conv(h4)))
hd5_UT_hd4 = self.hd5_UT_hd4_relu(self.hd5_UT_hd4_bn(self.hd5_UT_hd4_conv(self.hd5_UT_hd4(hd5))))
hd4 = self.relu4d_1(self.bn4d_1(self.conv4d_1(
paddle.concat([h2_PT_hd4, h2_PT_hd4, h3_PT_hd4, h4_Cat_hd4, hd5_UT_hd4], 1)))) # hd4->40*40*UpChannels
h2_PT_hd3 = self.h2_PT_hd3_relu(self.h2_PT_hd3_bn(self.h2_PT_hd3_conv(self.h2_PT_hd3(h2))))
h2_PT_hd3 = self.h2_PT_hd3_relu(self.h2_PT_hd3_bn(self.h2_PT_hd3_conv(self.h2_PT_hd3(h2))))
h3_Cat_hd3 = self.h3_Cat_hd3_relu(self.h3_Cat_hd3_bn(self.h3_Cat_hd3_conv(h3)))
hd4_UT_hd3 = self.hd4_UT_hd3_relu(self.hd4_UT_hd3_bn(self.hd4_UT_hd3_conv(self.hd4_UT_hd3(hd4))))
hd5_UT_hd3 = self.hd5_UT_hd3_relu(self.hd5_UT_hd3_bn(self.hd5_UT_hd3_conv(self.hd5_UT_hd3(hd5))))
hd3 = self.relu3d_1(self.bn3d_1(self.conv3d_1(
paddle.concat([h2_PT_hd3, h2_PT_hd3, h3_Cat_hd3, hd4_UT_hd3, hd5_UT_hd3], 1)))) # hd3->80*80*UpChannels
h2_PT_hd2 = self.h2_PT_hd2_relu(self.h2_PT_hd2_bn(self.h2_PT_hd2_conv(self.h2_PT_hd2(h2))))
h2_Cat_hd2 = self.h2_Cat_hd2_relu(self.h2_Cat_hd2_bn(self.h2_Cat_hd2_conv(h2)))
hd3_UT_hd2 = self.hd3_UT_hd2_relu(self.hd3_UT_hd2_bn(self.hd3_UT_hd2_conv(self.hd3_UT_hd2(hd3))))
hd4_UT_hd2 = self.hd4_UT_hd2_relu(self.hd4_UT_hd2_bn(self.hd4_UT_hd2_conv(self.hd4_UT_hd2(hd4))))
hd5_UT_hd2 = self.hd5_UT_hd2_relu(self.hd5_UT_hd2_bn(self.hd5_UT_hd2_conv(self.hd5_UT_hd2(hd5))))
hd2 = self.relu2d_1(self.bn2d_1(self.Conv2D_1(
paddle.concat([h2_PT_hd2, h2_Cat_hd2, hd3_UT_hd2, hd4_UT_hd2, hd5_UT_hd2], 1)))) # hd2->160*160*UpChannels
h2_Cat_hd1 = self.h2_Cat_hd1_relu(self.h2_Cat_hd1_bn(self.h2_Cat_hd1_conv(h2)))
hd2_UT_hd1 = self.hd2_UT_hd1_relu(self.hd2_UT_hd1_bn(self.hd2_UT_hd1_conv(self.hd2_UT_hd1(hd2))))
hd3_UT_hd1 = self.hd3_UT_hd1_relu(self.hd3_UT_hd1_bn(self.hd3_UT_hd1_conv(self.hd3_UT_hd1(hd3))))
hd4_UT_hd1 = self.hd4_UT_hd1_relu(self.hd4_UT_hd1_bn(self.hd4_UT_hd1_conv(self.hd4_UT_hd1(hd4))))
hd5_UT_hd1 = self.hd5_UT_hd1_relu(self.hd5_UT_hd1_bn(self.hd5_UT_hd1_conv(self.hd5_UT_hd1(hd5))))
hd1 = self.relu1d_1(self.bn1d_1(self.conv1d_1(
paddle.concat([h2_Cat_hd1, hd2_UT_hd1, hd3_UT_hd1, hd4_UT_hd1, hd5_UT_hd1], 1)))) # hd1->320*320*UpChannels
d1 = self.outconv1(hd1) # d1->320*320*n_classes
if self.end_sigmoid:
out = F.sigmoid(d1) else:
out = d1 return out
self.hd5_UT_hd1 = nn.Upsample(scale_factor=16, mode='bilinear') # 14*14
self.hd5_UT_hd1_conv = nn.Conv2D(filters[4], self.CatChannels, 3, padding=1)
self.hd5_UT_hd1_bn = nn.BatchNorm(self.CatChannels)
self.hd5_UT_hd1_relu = nn.ReLU() # fusion(h2_Cat_hd1, hd2_UT_hd1, hd3_UT_hd1, hd4_UT_hd1, hd5_UT_hd1)
self.conv1d_1 = nn.Conv2D(self.UpChannels, self.UpChannels, 3, padding=1) # 16
self.bn1d_1 = nn.BatchNorm(self.UpChannels)
self.relu1d_1 = nn.ReLU() # output
self.outconv1 = nn.Conv2D(self.UpChannels, n_classes, 3, padding=1) # initialise weights
for m in self.sublayers (): if isinstance(m, nn.Conv2D):
m.weight_attr = init_weights(init_type='kaiming')
m.bias_attr = init_weights(init_type='kaiming') elif isinstance(m, nn.BatchNorm):
m.param_attr =init_weights(init_type='kaiming')
m.bias_attr = init_weights(init_type='kaiming') def forward(self, inputs):
## -------------Encoder-------------
h2 = self.conv1(inputs) # h2->320*320*64
h2 = self.maxpool1(h2)
h2 = self.conv2(h2) # h2->160*160*128
h3 = self.maxpool2(h2)
h3 = self.conv3(h3) # h3->80*80*256
h4 = self.maxpool3(h3)
h4 = self.conv4(h4) # h4->40*40*512
h5 = self.maxpool4(h4)
hd5 = self.conv5(h5) # h5->20*20*1024
## -------------Decoder-------------
h2_PT_hd4 = self.h2_PT_hd4_relu(self.h2_PT_hd4_bn(self.h2_PT_hd4_conv(self.h2_PT_hd4(h2))))
h2_PT_hd4 = self.h2_PT_hd4_relu(self.h2_PT_hd4_bn(self.h2_PT_hd4_conv(self.h2_PT_hd4(h2))))
h3_PT_hd4 = self.h3_PT_hd4_relu(self.h3_PT_hd4_bn(self.h3_PT_hd4_conv(self.h3_PT_hd4(h3))))
h4_Cat_hd4 = self.h4_Cat_hd4_relu(self.h4_Cat_hd4_bn(self.h4_Cat_hd4_conv(h4)))
hd5_UT_hd4 = self.hd5_UT_hd4_relu(self.hd5_UT_hd4_bn(self.hd5_UT_hd4_conv(self.hd5_UT_hd4(hd5))))
hd4 = self.relu4d_1(self.bn4d_1(self.conv4d_1(
paddle.concat([h2_PT_hd4, h2_PT_hd4, h3_PT_hd4, h4_Cat_hd4, hd5_UT_hd4], 1)))) # hd4->40*40*UpChannels
h2_PT_hd3 = self.h2_PT_hd3_relu(self.h2_PT_hd3_bn(self.h2_PT_hd3_conv(self.h2_PT_hd3(h2))))
h2_PT_hd3 = self.h2_PT_hd3_relu(self.h2_PT_hd3_bn(self.h2_PT_hd3_conv(self.h2_PT_hd3(h2))))
h3_Cat_hd3 = self.h3_Cat_hd3_relu(self.h3_Cat_hd3_bn(self.h3_Cat_hd3_conv(h3)))
hd4_UT_hd3 = self.hd4_UT_hd3_relu(self.hd4_UT_hd3_bn(self.hd4_UT_hd3_conv(self.hd4_UT_hd3(hd4))))
hd5_UT_hd3 = self.hd5_UT_hd3_relu(self.hd5_UT_hd3_bn(self.hd5_UT_hd3_conv(self.hd5_UT_hd3(hd5))))
hd3 = self.relu3d_1(self.bn3d_1(self.conv3d_1(
paddle.concat([h2_PT_hd3, h2_PT_hd3, h3_Cat_hd3, hd4_UT_hd3, hd5_UT_hd3], 1)))) # hd3->80*80*UpChannels
h2_PT_hd2 = self.h2_PT_hd2_relu(self.h2_PT_hd2_bn(self.h2_PT_hd2_conv(self.h2_PT_hd2(h2))))
h2_Cat_hd2 = self.h2_Cat_hd2_relu(self.h2_Cat_hd2_bn(self.h2_Cat_hd2_conv(h2)))
hd3_UT_hd2 = self.hd3_UT_hd2_relu(self.hd3_UT_hd2_bn(self.hd3_UT_hd2_conv(self.hd3_UT_hd2(hd3))))
hd4_UT_hd2 = self.hd4_UT_hd2_relu(self.hd4_UT_hd2_bn(self.hd4_UT_hd2_conv(self.hd4_UT_hd2(hd4))))
hd5_UT_hd2 = self.hd5_UT_hd2_relu(self.hd5_UT_hd2_bn(self.hd5_UT_hd2_conv(self.hd5_UT_hd2(hd5))))
hd2 = self.relu2d_1(self.bn2d_1(self.Conv2D_1(
paddle.concat([h2_PT_hd2, h2_Cat_hd2, hd3_UT_hd2, hd4_UT_hd2, hd5_UT_hd2], 1)))) # hd2->160*160*UpChannels
h2_Cat_hd1 = self.h2_Cat_hd1_relu(self.h2_Cat_hd1_bn(self.h2_Cat_hd1_conv(h2)))
hd2_UT_hd1 = self.hd2_UT_hd1_relu(self.hd2_UT_hd1_bn(self.hd2_UT_hd1_conv(self.hd2_UT_hd1(hd2))))
hd3_UT_hd1 = self.hd3_UT_hd1_relu(self.hd3_UT_hd1_bn(self.hd3_UT_hd1_conv(self.hd3_UT_hd1(hd3))))
hd4_UT_hd1 = self.hd4_UT_hd1_relu(self.hd4_UT_hd1_bn(self.hd4_UT_hd1_conv(self.hd4_UT_hd1(hd4))))
hd5_UT_hd1 = self.hd5_UT_hd1_relu(self.hd5_UT_hd1_bn(self.hd5_UT_hd1_conv(self.hd5_UT_hd1(hd5))))
hd1 = self.relu1d_1(self.bn1d_1(self.conv1d_1(
paddle.concat([h2_Cat_hd1, hd2_UT_hd1, hd3_UT_hd1, hd4_UT_hd1, hd5_UT_hd1], 1)))) # hd1->320*320*UpChannels
d1 = self.outconv1(hd1) # d1->320*320*n_classes
if self.end_sigmoid:
out = F.sigmoid(d1) else:
out = d1 return out
In [ ]
# 模型可视化import numpyimport paddle unet3p = UNet_3Plus(in_channels=3, n_classes=1) model = paddle.Model(unet3p) model.summary((2,3, 768, 512))
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-2 [[2, 3, 768, 512]] [2, 16, 768, 512] 448
BatchNorm-1 [[2, 16, 768, 512]] [2, 16, 768, 512] 64
ReLU-1 [[2, 16, 768, 512]] [2, 16, 768, 512] 0
Conv2D-3 [[2, 16, 768, 512]] [2, 16, 768, 512] 2,320
BatchNorm-2 [[2, 16, 768, 512]] [2, 16, 768, 512] 64
ReLU-2 [[2, 16, 768, 512]] [2, 16, 768, 512] 0
unetConv2-2 [[2, 3, 768, 512]] [2, 16, 768, 512] 0
MaxPool2D-1 [[2, 16, 768, 512]] [2, 16, 384, 256] 0
Conv2D-4 [[2, 16, 384, 256]] [2, 32, 384, 256] 4,640
BatchNorm-3 [[2, 32, 384, 256]] [2, 32, 384, 256] 128
ReLU-3 [[2, 32, 384, 256]] [2, 32, 384, 256] 0
Conv2D-5 [[2, 32, 384, 256]] [2, 32, 384, 256] 9,248
BatchNorm-4 [[2, 32, 384, 256]] [2, 32, 384, 256] 128
ReLU-4 [[2, 32, 384, 256]] [2, 32, 384, 256] 0
unetConv2-3 [[2, 16, 384, 256]] [2, 32, 384, 256] 0
MaxPool2D-2 [[2, 32, 384, 256]] [2, 32, 192, 128] 0
Conv2D-6 [[2, 32, 192, 128]] [2, 64, 192, 128] 18,496
BatchNorm-5 [[2, 64, 192, 128]] [2, 64, 192, 128] 256
ReLU-5 [[2, 64, 192, 128]] [2, 64, 192, 128] 0
Conv2D-7 [[2, 64, 192, 128]] [2, 64, 192, 128] 36,928
BatchNorm-6 [[2, 64, 192, 128]] [2, 64, 192, 128] 256
ReLU-6 [[2, 64, 192, 128]] [2, 64, 192, 128] 0
unetConv2-4 [[2, 32, 192, 128]] [2, 64, 192, 128] 0
MaxPool2D-3 [[2, 64, 192, 128]] [2, 64, 96, 64] 0
Conv2D-8 [[2, 64, 96, 64]] [2, 128, 96, 64] 73,856
BatchNorm-7 [[2, 128, 96, 64]] [2, 128, 96, 64] 512
ReLU-7 [[2, 128, 96, 64]] [2, 128, 96, 64] 0
Conv2D-9 [[2, 128, 96, 64]] [2, 128, 96, 64] 147,584
BatchNorm-8 [[2, 128, 96, 64]] [2, 128, 96, 64] 512
ReLU-8 [[2, 128, 96, 64]] [2, 128, 96, 64] 0
unetConv2-5 [[2, 64, 96, 64]] [2, 128, 96, 64] 0
MaxPool2D-4 [[2, 128, 96, 64]] [2, 128, 48, 32] 0
Conv2D-10 [[2, 128, 48, 32]] [2, 256, 48, 32] 295,168
BatchNorm-9 [[2, 256, 48, 32]] [2, 256, 48, 32] 1,024
ReLU-9 [[2, 256, 48, 32]] [2, 256, 48, 32] 0
Conv2D-11 [[2, 256, 48, 32]] [2, 256, 48, 32] 590,080
BatchNorm-10 [[2, 256, 48, 32]] [2, 256, 48, 32] 1,024
ReLU-10 [[2, 256, 48, 32]] [2, 256, 48, 32] 0
unetConv2-6 [[2, 128, 48, 32]] [2, 256, 48, 32] 0
MaxPool2D-5 [[2, 16, 768, 512]] [2, 16, 96, 64] 0
Conv2D-12 [[2, 16, 96, 64]] [2, 16, 96, 64] 2,320
BatchNorm-11 [[2, 16, 96, 64]] [2, 16, 96, 64] 64
ReLU-11 [[2, 16, 96, 64]] [2, 16, 96, 64] 0
MaxPool2D-6 [[2, 32, 384, 256]] [2, 32, 96, 64] 0
Conv2D-13 [[2, 32, 96, 64]] [2, 16, 96, 64] 4,624
BatchNorm-12 [[2, 16, 96, 64]] [2, 16, 96, 64] 64
ReLU-12 [[2, 16, 96, 64]] [2, 16, 96, 64] 0
MaxPool2D-7 [[2, 64, 192, 128]] [2, 64, 96, 64] 0
Conv2D-14 [[2, 64, 96, 64]] [2, 16, 96, 64] 9,232
BatchNorm-13 [[2, 16, 96, 64]] [2, 16, 96, 64] 64
ReLU-13 [[2, 16, 96, 64]] [2, 16, 96, 64] 0
Conv2D-15 [[2, 128, 96, 64]] [2, 16, 96, 64] 18,448
BatchNorm-14 [[2, 16, 96, 64]] [2, 16, 96, 64] 64
ReLU-14 [[2, 16, 96, 64]] [2, 16, 96, 64] 0
Upsample-1 [[2, 256, 48, 32]] [2, 256, 96, 64] 0
Conv2D-16 [[2, 256, 96, 64]] [2, 16, 96, 64] 36,880
BatchNorm-15 [[2, 16, 96, 64]] [2, 16, 96, 64] 64
ReLU-15 [[2, 16, 96, 64]] [2, 16, 96, 64] 0
Conv2D-17 [[2, 80, 96, 64]] [2, 80, 96, 64] 57,680
BatchNorm-16 [[2, 80, 96, 64]] [2, 80, 96, 64] 320
ReLU-16 [[2, 80, 96, 64]] [2, 80, 96, 64] 0
MaxPool2D-8 [[2, 16, 768, 512]] [2, 16, 192, 128] 0
Conv2D-18 [[2, 16, 192, 128]] [2, 16, 192, 128] 2,320
BatchNorm-17 [[2, 16, 192, 128]] [2, 16, 192, 128] 64
ReLU-17 [[2, 16, 192, 128]] [2, 16, 192, 128] 0
MaxPool2D-9 [[2, 32, 384, 256]] [2, 32, 192, 128] 0
Conv2D-19 [[2, 32, 192, 128]] [2, 16, 192, 128] 4,624
BatchNorm-18 [[2, 16, 192, 128]] [2, 16, 192, 128] 64
ReLU-18 [[2, 16, 192, 128]] [2, 16, 192, 128] 0
Conv2D-20 [[2, 64, 192, 128]] [2, 16, 192, 128] 9,232
BatchNorm-19 [[2, 16, 192, 128]] [2, 16, 192, 128] 64
ReLU-19 [[2, 16, 192, 128]] [2, 16, 192, 128] 0
Upsample-2 [[2, 80, 96, 64]] [2, 80, 192, 128] 0
Conv2D-21 [[2, 80, 192, 128]] [2, 16, 192, 128] 11,536
BatchNorm-20 [[2, 16, 192, 128]] [2, 16, 192, 128] 64
ReLU-20 [[2, 16, 192, 128]] [2, 16, 192, 128] 0
Upsample-3 [[2, 256, 48, 32]] [2, 256, 192, 128] 0
Conv2D-22 [[2, 256, 192, 128]] [2, 16, 192, 128] 36,880
BatchNorm-21 [[2, 16, 192, 128]] [2, 16, 192, 128] 64
ReLU-21 [[2, 16, 192, 128]] [2, 16, 192, 128] 0
Conv2D-23 [[2, 80, 192, 128]] [2, 80, 192, 128] 57,680
BatchNorm-22 [[2, 80, 192, 128]] [2, 80, 192, 128] 320
ReLU-22 [[2, 80, 192, 128]] [2, 80, 192, 128] 0
MaxPool2D-10 [[2, 16, 768, 512]] [2, 16, 384, 256] 0
Conv2D-24 [[2, 16, 384, 256]] [2, 16, 384, 256] 2,320
BatchNorm-23 [[2, 16, 384, 256]] [2, 16, 384, 256] 64
ReLU-23 [[2, 16, 384, 256]] [2, 16, 384, 256] 0
Conv2D-25 [[2, 32, 384, 256]] [2, 16, 384, 256] 4,624
BatchNorm-24 [[2, 16, 384, 256]] [2, 16, 384, 256] 64
ReLU-24 [[2, 16, 384, 256]] [2, 16, 384, 256] 0
Upsample-4 [[2, 80, 192, 128]] [2, 80, 384, 256] 0
Conv2D-26 [[2, 80, 384, 256]] [2, 16, 384, 256] 11,536
BatchNorm-25 [[2, 16, 384, 256]] [2, 16, 384, 256] 64
ReLU-25 [[2, 16, 384, 256]] [2, 16, 384, 256] 0
Upsample-5 [[2, 80, 96, 64]] [2, 80, 384, 256] 0
Conv2D-27 [[2, 80, 384, 256]] [2, 16, 384, 256] 11,536
BatchNorm-26 [[2, 16, 384, 256]] [2, 16, 384, 256] 64
ReLU-26 [[2, 16, 384, 256]] [2, 16, 384, 256] 0
Upsample-6 [[2, 256, 48, 32]] [2, 256, 384, 256] 0
Conv2D-28 [[2, 256, 384, 256]] [2, 16, 384, 256] 36,880
BatchNorm-27 [[2, 16, 384, 256]] [2, 16, 384, 256] 64
ReLU-27 [[2, 16, 384, 256]] [2, 16, 384, 256] 0
Conv2D-29 [[2, 80, 384, 256]] [2, 80, 384, 256] 57,680
BatchNorm-28 [[2, 80, 384, 256]] [2, 80, 384, 256] 320
ReLU-28 [[2, 80, 384, 256]] [2, 80, 384, 256] 0
Conv2D-30 [[2, 16, 768, 512]] [2, 16, 768, 512] 2,320
BatchNorm-29 [[2, 16, 768, 512]] [2, 16, 768, 512] 64
ReLU-29 [[2, 16, 768, 512]] [2, 16, 768, 512] 0
Upsample-7 [[2, 80, 384, 256]] [2, 80, 768, 512] 0
Conv2D-31 [[2, 80, 768, 512]] [2, 16, 768, 512] 11,536
BatchNorm-30 [[2, 16, 768, 512]] [2, 16, 768, 512] 64
ReLU-30 [[2, 16, 768, 512]] [2, 16, 768, 512] 0
Upsample-8 [[2, 80, 192, 128]] [2, 80, 768, 512] 0
Conv2D-32 [[2, 80, 768, 512]] [2, 16, 768, 512] 11,536
BatchNorm-31 [[2, 16, 768, 512]] [2, 16, 768, 512] 64
ReLU-31 [[2, 16, 768, 512]] [2, 16, 768, 512] 0
Upsample-9 [[2, 80, 96, 64]] [2, 80, 768, 512] 0
Conv2D-33 [[2, 80, 768, 512]] [2, 16, 768, 512] 11,536
BatchNorm-32 [[2, 16, 768, 512]] [2, 16, 768, 512] 64
ReLU-32 [[2, 16, 768, 512]] [2, 16, 768, 512] 0
Upsample-10 [[2, 256, 48, 32]] [2, 256, 768, 512] 0
Conv2D-34 [[2, 256, 768, 512]] [2, 16, 768, 512] 36,880
BatchNorm-33 [[2, 16, 768, 512]] [2, 16, 768, 512] 64
ReLU-33 [[2, 16, 768, 512]] [2, 16, 768, 512] 0
Conv2D-35 [[2, 80, 768, 512]] [2, 80, 768, 512] 57,680
BatchNorm-34 [[2, 80, 768, 512]] [2, 80, 768, 512] 320
ReLU-34 [[2, 80, 768, 512]] [2, 80, 768, 512] 0
Conv2D-36 [[2, 80, 768, 512]] [2, 1, 768, 512] 721
===========================================================================
Total params: 1,693,537
Trainable params: 1,687,009
Non-trainable params: 6,528
---------------------------------------------------------------------------
Input size (MB): 9.00
Forward/backward pass size (MB): 8980.50
Params size (MB): 6.46
Estimated Total Size (MB): 8995.96
---------------------------------------------------------------------------
{'total_params': 1693537, 'trainable_params': 1687009}
model = UNet_3Plus(in_channels=3, n_classes=1)#SEUNet(3,1)# 开启模型训练模式model.train()# 定义优化算法,使用随机梯度下降SGD,学习率设置为0.01scheduler = paddle.optimizer.lr.StepDecay(learning_rate=0.01, step_size=30, gamma=0.1, verbose=False)
optimizer = paddle.optimizer.Adam(learning_rate=scheduler, parameters=model.parameters())
EPOCH_NUM = 60 # 设置外层循环次数BATCH_SIZE = 2 # 设置batch大小train_dataset = MRILocationDataset(mode='train')
test_dataset = MRILocationDataset(mode='test')# 使用paddle.io.DataLoader 定义DataLoader对象用于加载Python生成器产生的数据,data_loader = paddle.io.DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=False)
test_data_loader = paddle.io.DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)
loss_BCEloss = paddle.nn.BCELoss()# 定义外层循环for epoch_id in range(EPOCH_NUM): # 定义内层循环
for iter_id, data in enumerate(data_loader()):
x, y = data # x 为数据 ,y 为标签
# 将numpy数据转为飞桨动态图tensor形式
x = paddle.to_tensor(x,dtype='float32')
y = paddle.to_tensor(y,dtype='float32') # 前向计算
predicts = model(x) # 计算损失
loss = loss_BCEloss(predicts, y) # 清除梯度
optimizer.clear_grad() # 反向传播
loss.backward() # 最小化loss,更新参数
optimizer.step()
scheduler.step() print("epoch: {}, iter: {}, loss is: {}".format(epoch_id+1, iter_id+1, loss.numpy()))# 保存模型参数,文件名为Unet_model.pdparamspaddle.s*e(model.state_dict(), 'work/Unet3p_model.pdparams')print("模型保存成功,模型参数保存在Unet3p_model.pdparams中")
import paddle# 模型验证Error = []# 清理缓存print("开始测试")# 用于加载之前的训练过的模型参数para_state_dict = paddle.load('work/Unet3p_model.pdparams')
model = UNet_3Plus(in_channels=3, n_classes=1)#SEUNet(3,1)model.set_dict(para_state_dict)for iter_id, data in enumerate(test_data_loader()):
x, y = data # 将numpy数据转为飞桨动态图tensor形式
x = paddle.to_tensor(x)
y = paddle.to_tensor(y)
predicts = model(x) for i in range(predicts.shape[0]):
predict = predicts[i,:,:,:].cpu().numpy()
label = y[i,:,:,:].cpu().numpy()
inputs = x[i,1,:,:].cpu().numpy()
predict = np.squeeze(predict)
label = np.squeeze(label)
inputs = np.squeeze(inputs) #当要保存的图片为灰度图像时,灰度图像的 numpy 尺度是 [1, h, w]。需要将 [1, h, w] 改变为 [h, w]
plt.figure(figsize=(18, 6))
plt.subplot(1,3,1),plt.xticks([]),plt.yticks([]),plt.imshow(predict)
plt.subplot(1,3,2),plt.xticks([]),plt.yticks([]),plt.imshow(label)
plt.subplot(1,3,3),plt.xticks([]),plt.yticks([]),plt.imshow(inputs)
plt.show()
index_predict= np.argmax(np.max(predict,1))+3
index_label = np.argmax(np.max(label,1)) print('真实位置:',index_label,'预测位置:',index_predict)
Error.append(np.abs(index_label-index_predict)) breakprint("模型测试集平均定位误差为:",np.mean(Error))
开始测试
<Figure size 1296x432 with 3 Axes>
真实位置: 416 预测位置: 420
<Figure size 1296x432 with 3 Axes>
真实位置: 484 预测位置: 480 模型测试集平均定位误差为: 4.0
以上就是『医学影像』基于Unet+++实现脊柱MRI定位(上)的详细内容,更多请关注其它相关文章!
# 工具
# python
# 设置为
# 轴向
# 一言
# 中文网
# type
# fig
# udio
# igs
# red
# 子网
# ai
# 合肥租房网站建设
# 手机壳seo描述
# 丛台区营销推广招聘
# 网站推广工作的心得体会
# 营口信息化网站建设流程
# 辽宁企业关键词排名
# SEO查询征信怎么
# 企业全网营销引流推广
# 梁平的网站建设高端公司
# seo获取更多付费流量
# 是一个
# 的是
# 自己的
# 官网
# 目的是
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
谷歌推出 SAIF 框架,倡导安全环境下探索和发展人工智能
第 66 届格莱美奖规定,AI 作品将无法获得评奖资格
黄仁勋:5年前,我们对AI抱有巨大期望
史玉柱谈AI:国内最缺是计算数学人才,曾给浙大数学系捐五千万
「社交达人」GPT-4!解读表情、揣测心理全都会
日媒关注中国推进鸟类识别 AI 普及,除监测保护外还可预防传染性疾病
央视报道车载人机交互技术!MWC上海魅族表现亮眼,现场热火朝天
AI无法对传统文化符号进行解构和创新
电力人工智能数据集目录首次发布
苹果2万5的AR遭遇砍单95%:不及预期
映宇宙数字人“映映”亮相ChinaJoy,展示AI黑科技实现用户互动
中国最强AI研究院的大模型为何迟到了
Unity 内测 Safe Voice 服务,利用 AI 自动识别玩家不当聊天内容
腾讯自主研发机器狗 Max 升级,可“奔跑跳跃”完成避障动作
售价14.99万起!小米汽车部分信息疑遭AI曝光,内部人士回应:网传图片明显经过处理,不可轻信
特斯拉人形机器人将于 7 月亮相上海 2025 世界人工智能大会
城市在采用人工智能方面进展如何?
探索人工智能在物联网领域的影响与改变
数据显示:人工智能相关专业热度上升最快 考古、美术、生物医学工程等小众专业火了
利亚德加码AI战略,与光年无限图灵机器人全面开展AI研发业务合作
日媒:AI高效解析纳斯卡地画
2025年的网络分区:人工智能和自动化如何改变事物
马斯克发推讽刺人工智能,机器学习本质是统计?
AIGC浪潮下,联想集团再加码计算与人工智能
复盘MWC上海:AI大模型时代到来 通信网络将会怎样改变?
Valve 将拒绝采用 AI 生成未知版权内容的游戏上架 Steam
Stability AI 推出文生图模型 SDXL0.9,GPU要求下探至消费级水平
爱设计 AI 一键生成 PPT 工具上线:输入标题即可生成 PPT
360发布数字安全和人工智能的强大结合:360安全大模型
Win11 的画图应用将包含 Windows Copilot 的 AI 工具整合
人工智能:解决劳动力短缺的关键策略
AI绘画,还需要懂数学?
OPPO三方联合发布AI可持续发展白皮书,坚持发展健康AI生态
当科幻走进现实 脑机接口新技术能为生活带来哪些惊喜?
无人机巡检方案是什么,该如何选择适合的巡检方案
ChatGPT大更新!OpenAI奉上程序员大礼包:API新增杀手级能力还降价,新模型、四倍上下文都来了
WHEE安装教程
对话无界AI创始人长铗:AI的创业机会在应用层丨创新者Innovator
腾讯AI首次模拟拼接三星堆文物,工作取得阶段性的成果
视觉中国宣布推出AI灵感绘图、画面扩展功能
【趋势周报】全球元宇宙产业发展趋势:ChatGPT的出现,将元宇宙实现至少提前了10年
首届亚太网络法实务大会召开 九位大咖探讨元宇宙与人工智能发展
海柔创新携手SAP,以机器人技术助力全球客户升级数智化竞争力
“踩油门,也要会踩刹车” 互联网企业高管谈人工智能发展
小米又拿下国际比赛第一:AI翻译立功
为AI而服务设计:构建以人为本的AI创新方法
印象笔记开放旗下“印象 AI”,可一键生成思维导图、写文章等
智能机器人与话剧的完美结合:宇树四足机器人B1助力《骆驼祥子》重现经典
世界人工智能大会(WAIC 2025)点燃魔都,博尔捷数字科技携前沿技术产品亮相
小米首次曝光 64 亿参数的 MiLM-6B AI 大模型,或将应用于小爱同学
2025-07-21

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。

 self.hd5_UT_hd1 = nn.Upsample(scale_factor=16, mode='bilinear') # 14*14
self.hd5_UT_hd1_conv = nn.Conv2D(filters[4], self.CatChannels, 3, padding=1)
self.hd5_UT_hd1_bn = nn.BatchNorm(self.CatChannels)
self.hd5_UT_hd1_relu = nn.ReLU() # fusion(h2_Cat_hd1, hd2_UT_hd1, hd3_UT_hd1, hd4_UT_hd1, hd5_UT_hd1)
self.conv1d_1 = nn.Conv2D(self.UpChannels, self.UpChannels, 3, padding=1) # 16
self.bn1d_1 = nn.BatchNorm(self.UpChannels)
self.relu1d_1 = nn.ReLU() # output
self.outconv1 = nn.Conv2D(self.UpChannels, n_classes, 3, padding=1) # initialise weights
for m in self.sublayers (): if isinstance(m, nn.Conv2D):
m.weight_attr = init_weights(init_type='kaiming')
m.bias_attr = init_weights(init_type='kaiming') elif isinstance(m, nn.BatchNorm):
m.param_attr =init_weights(init_type='kaiming')
m.bias_attr = init_weights(init_type='kaiming') def forward(self, inputs):
## -------------Encoder-------------
h2 = self.conv1(inputs) # h2->320*320*64
h2 = self.maxpool1(h2)
h2 = self.conv2(h2) # h2->160*160*128
h3 = self.maxpool2(h2)
h3 = self.conv3(h3) # h3->80*80*256
h4 = self.maxpool3(h3)
h4 = self.conv4(h4) # h4->40*40*512
h5 = self.maxpool4(h4)
hd5 = self.conv5(h5) # h5->20*20*1024
## -------------Decoder-------------
h2_PT_hd4 = self.h2_PT_hd4_relu(self.h2_PT_hd4_bn(self.h2_PT_hd4_conv(self.h2_PT_hd4(h2))))
h2_PT_hd4 = self.h2_PT_hd4_relu(self.h2_PT_hd4_bn(self.h2_PT_hd4_conv(self.h2_PT_hd4(h2))))
h3_PT_hd4 = self.h3_PT_hd4_relu(self.h3_PT_hd4_bn(self.h3_PT_hd4_conv(self.h3_PT_hd4(h3))))
h4_Cat_hd4 = self.h4_Cat_hd4_relu(self.h4_Cat_hd4_bn(self.h4_Cat_hd4_conv(h4)))
hd5_UT_hd4 = self.hd5_UT_hd4_relu(self.hd5_UT_hd4_bn(self.hd5_UT_hd4_conv(self.hd5_UT_hd4(hd5))))
hd4 = self.relu4d_1(self.bn4d_1(self.conv4d_1(
paddle.concat([h2_PT_hd4, h2_PT_hd4, h3_PT_hd4, h4_Cat_hd4, hd5_UT_hd4], 1)))) # hd4->40*40*UpChannels
h2_PT_hd3 = self.h2_PT_hd3_relu(self.h2_PT_hd3_bn(self.h2_PT_hd3_conv(self.h2_PT_hd3(h2))))
h2_PT_hd3 = self.h2_PT_hd3_relu(self.h2_PT_hd3_bn(self.h2_PT_hd3_conv(self.h2_PT_hd3(h2))))
h3_Cat_hd3 = self.h3_Cat_hd3_relu(self.h3_Cat_hd3_bn(self.h3_Cat_hd3_conv(h3)))
hd4_UT_hd3 = self.hd4_UT_hd3_relu(self.hd4_UT_hd3_bn(self.hd4_UT_hd3_conv(self.hd4_UT_hd3(hd4))))
hd5_UT_hd3 = self.hd5_UT_hd3_relu(self.hd5_UT_hd3_bn(self.hd5_UT_hd3_conv(self.hd5_UT_hd3(hd5))))
hd3 = self.relu3d_1(self.bn3d_1(self.conv3d_1(
paddle.concat([h2_PT_hd3, h2_PT_hd3, h3_Cat_hd3, hd4_UT_hd3, hd5_UT_hd3], 1)))) # hd3->80*80*UpChannels
h2_PT_hd2 = self.h2_PT_hd2_relu(self.h2_PT_hd2_bn(self.h2_PT_hd2_conv(self.h2_PT_hd2(h2))))
h2_Cat_hd2 = self.h2_Cat_hd2_relu(self.h2_Cat_hd2_bn(self.h2_Cat_hd2_conv(h2)))
hd3_UT_hd2 = self.hd3_UT_hd2_relu(self.hd3_UT_hd2_bn(self.hd3_UT_hd2_conv(self.hd3_UT_hd2(hd3))))
hd4_UT_hd2 = self.hd4_UT_hd2_relu(self.hd4_UT_hd2_bn(self.hd4_UT_hd2_conv(self.hd4_UT_hd2(hd4))))
hd5_UT_hd2 = self.hd5_UT_hd2_relu(self.hd5_UT_hd2_bn(self.hd5_UT_hd2_conv(self.hd5_UT_hd2(hd5))))
hd2 = self.relu2d_1(self.bn2d_1(self.Conv2D_1(
paddle.concat([h2_PT_hd2, h2_Cat_hd2, hd3_UT_hd2, hd4_UT_hd2, hd5_UT_hd2], 1)))) # hd2->160*160*UpChannels
h2_Cat_hd1 = self.h2_Cat_hd1_relu(self.h2_Cat_hd1_bn(self.h2_Cat_hd1_conv(h2)))
hd2_UT_hd1 = self.hd2_UT_hd1_relu(self.hd2_UT_hd1_bn(self.hd2_UT_hd1_conv(self.hd2_UT_hd1(hd2))))
hd3_UT_hd1 = self.hd3_UT_hd1_relu(self.hd3_UT_hd1_bn(self.hd3_UT_hd1_conv(self.hd3_UT_hd1(hd3))))
hd4_UT_hd1 = self.hd4_UT_hd1_relu(self.hd4_UT_hd1_bn(self.hd4_UT_hd1_conv(self.hd4_UT_hd1(hd4))))
hd5_UT_hd1 = self.hd5_UT_hd1_relu(self.hd5_UT_hd1_bn(self.hd5_UT_hd1_conv(self.hd5_UT_hd1(hd5))))
hd1 = self.relu1d_1(self.bn1d_1(self.conv1d_1(
paddle.concat([h2_Cat_hd1, hd2_UT_hd1, hd3_UT_hd1, hd4_UT_hd1, hd5_UT_hd1], 1)))) # hd1->320*320*UpChannels
d1 = self.outconv1(hd1) # d1->320*320*n_classes
if self.end_sigmoid:
out = F.sigmoid(d1) else:
out = d1 return out
self.hd5_UT_hd1 = nn.Upsample(scale_factor=16, mode='bilinear') # 14*14
self.hd5_UT_hd1_conv = nn.Conv2D(filters[4], self.CatChannels, 3, padding=1)
self.hd5_UT_hd1_bn = nn.BatchNorm(self.CatChannels)
self.hd5_UT_hd1_relu = nn.ReLU() # fusion(h2_Cat_hd1, hd2_UT_hd1, hd3_UT_hd1, hd4_UT_hd1, hd5_UT_hd1)
self.conv1d_1 = nn.Conv2D(self.UpChannels, self.UpChannels, 3, padding=1) # 16
self.bn1d_1 = nn.BatchNorm(self.UpChannels)
self.relu1d_1 = nn.ReLU() # output
self.outconv1 = nn.Conv2D(self.UpChannels, n_classes, 3, padding=1) # initialise weights
for m in self.sublayers (): if isinstance(m, nn.Conv2D):
m.weight_attr = init_weights(init_type='kaiming')
m.bias_attr = init_weights(init_type='kaiming') elif isinstance(m, nn.BatchNorm):
m.param_attr =init_weights(init_type='kaiming')
m.bias_attr = init_weights(init_type='kaiming') def forward(self, inputs):
## -------------Encoder-------------
h2 = self.conv1(inputs) # h2->320*320*64
h2 = self.maxpool1(h2)
h2 = self.conv2(h2) # h2->160*160*128
h3 = self.maxpool2(h2)
h3 = self.conv3(h3) # h3->80*80*256
h4 = self.maxpool3(h3)
h4 = self.conv4(h4) # h4->40*40*512
h5 = self.maxpool4(h4)
hd5 = self.conv5(h5) # h5->20*20*1024
## -------------Decoder-------------
h2_PT_hd4 = self.h2_PT_hd4_relu(self.h2_PT_hd4_bn(self.h2_PT_hd4_conv(self.h2_PT_hd4(h2))))
h2_PT_hd4 = self.h2_PT_hd4_relu(self.h2_PT_hd4_bn(self.h2_PT_hd4_conv(self.h2_PT_hd4(h2))))
h3_PT_hd4 = self.h3_PT_hd4_relu(self.h3_PT_hd4_bn(self.h3_PT_hd4_conv(self.h3_PT_hd4(h3))))
h4_Cat_hd4 = self.h4_Cat_hd4_relu(self.h4_Cat_hd4_bn(self.h4_Cat_hd4_conv(h4)))
hd5_UT_hd4 = self.hd5_UT_hd4_relu(self.hd5_UT_hd4_bn(self.hd5_UT_hd4_conv(self.hd5_UT_hd4(hd5))))
hd4 = self.relu4d_1(self.bn4d_1(self.conv4d_1(
paddle.concat([h2_PT_hd4, h2_PT_hd4, h3_PT_hd4, h4_Cat_hd4, hd5_UT_hd4], 1)))) # hd4->40*40*UpChannels
h2_PT_hd3 = self.h2_PT_hd3_relu(self.h2_PT_hd3_bn(self.h2_PT_hd3_conv(self.h2_PT_hd3(h2))))
h2_PT_hd3 = self.h2_PT_hd3_relu(self.h2_PT_hd3_bn(self.h2_PT_hd3_conv(self.h2_PT_hd3(h2))))
h3_Cat_hd3 = self.h3_Cat_hd3_relu(self.h3_Cat_hd3_bn(self.h3_Cat_hd3_conv(h3)))
hd4_UT_hd3 = self.hd4_UT_hd3_relu(self.hd4_UT_hd3_bn(self.hd4_UT_hd3_conv(self.hd4_UT_hd3(hd4))))
hd5_UT_hd3 = self.hd5_UT_hd3_relu(self.hd5_UT_hd3_bn(self.hd5_UT_hd3_conv(self.hd5_UT_hd3(hd5))))
hd3 = self.relu3d_1(self.bn3d_1(self.conv3d_1(
paddle.concat([h2_PT_hd3, h2_PT_hd3, h3_Cat_hd3, hd4_UT_hd3, hd5_UT_hd3], 1)))) # hd3->80*80*UpChannels
h2_PT_hd2 = self.h2_PT_hd2_relu(self.h2_PT_hd2_bn(self.h2_PT_hd2_conv(self.h2_PT_hd2(h2))))
h2_Cat_hd2 = self.h2_Cat_hd2_relu(self.h2_Cat_hd2_bn(self.h2_Cat_hd2_conv(h2)))
hd3_UT_hd2 = self.hd3_UT_hd2_relu(self.hd3_UT_hd2_bn(self.hd3_UT_hd2_conv(self.hd3_UT_hd2(hd3))))
hd4_UT_hd2 = self.hd4_UT_hd2_relu(self.hd4_UT_hd2_bn(self.hd4_UT_hd2_conv(self.hd4_UT_hd2(hd4))))
hd5_UT_hd2 = self.hd5_UT_hd2_relu(self.hd5_UT_hd2_bn(self.hd5_UT_hd2_conv(self.hd5_UT_hd2(hd5))))
hd2 = self.relu2d_1(self.bn2d_1(self.Conv2D_1(
paddle.concat([h2_PT_hd2, h2_Cat_hd2, hd3_UT_hd2, hd4_UT_hd2, hd5_UT_hd2], 1)))) # hd2->160*160*UpChannels
h2_Cat_hd1 = self.h2_Cat_hd1_relu(self.h2_Cat_hd1_bn(self.h2_Cat_hd1_conv(h2)))
hd2_UT_hd1 = self.hd2_UT_hd1_relu(self.hd2_UT_hd1_bn(self.hd2_UT_hd1_conv(self.hd2_UT_hd1(hd2))))
hd3_UT_hd1 = self.hd3_UT_hd1_relu(self.hd3_UT_hd1_bn(self.hd3_UT_hd1_conv(self.hd3_UT_hd1(hd3))))
hd4_UT_hd1 = self.hd4_UT_hd1_relu(self.hd4_UT_hd1_bn(self.hd4_UT_hd1_conv(self.hd4_UT_hd1(hd4))))
hd5_UT_hd1 = self.hd5_UT_hd1_relu(self.hd5_UT_hd1_bn(self.hd5_UT_hd1_conv(self.hd5_UT_hd1(hd5))))
hd1 = self.relu1d_1(self.bn1d_1(self.conv1d_1(
paddle.concat([h2_Cat_hd1, hd2_UT_hd1, hd3_UT_hd1, hd4_UT_hd1, hd5_UT_hd1], 1)))) # hd1->320*320*UpChannels
d1 = self.outconv1(hd1) # d1->320*320*n_classes
if self.end_sigmoid:
out = F.sigmoid(d1) else:
out = d1 return out