本文提出Coordinate Attention机制,将位置信息嵌入通道注意力以提升模型性能。处理数据集后,对比经典模型,构建含该机制的TowerNet模型并训练,结果显示加入CA模块后性能大幅提升。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜


论文地址:https://arxiv.org/abs/2103.02907
我们将网上获取的数据集以压缩包的方式上传到aistudio数据集中,并加载到我们的项目内。
在使用之前我们进行数据集压缩包的一个解压。
In [ ]!unzip -oq /home/aistudio/data/data69664/Images.zip -d work/datasetIn [ ]
import paddleimport numpy as npfrom typing import Callable#参数配置config_parameters = { "class_dim": 16, #分类数
"target_path":"/home/aistudio/work/",
'train_image_dir': '/home/aistudio/work/trainImages', 'eval_image_dir': '/home/aistudio/work/evalImages', 'epochs':100, 'batch_size': 32, 'lr': 0.01}
接下来我们使用标注好的文件进行数据集类的定义,方便后续模型训练使用。
In [ ]import osimport shutil
train_dir = config_parameters['train_image_dir']
eval_dir = config_parameters['eval_image_dir']
paths = os.listdir('work/dataset/Images')if not os.path.exists(train_dir):
os.mkdir(train_dir)if not os.path.exists(eval_dir):
os.mkdir(eval_dir)for path in paths:
imgs_dir = os.listdir(os.path.join('work/dataset/Images', path))
target_train_dir = os.path.join(train_dir,path)
target_eval_dir = os.path.join(eval_dir,path) if not os.path.exists(target_train_dir):
os.mkdir(target_train_dir) if not os.path.exists(target_eval_dir):
os.mkdir(target_eval_dir) for i in range(len(imgs_dir)): if ' ' in imgs_dir[i]:
new_name = imgs_dir[i].replace(' ', '_') else:
new_name = imgs_dir[i]
target_train_path = os.path.join(target_train_dir, new_name)
target_eval_path = os.path.join(target_eval_dir, new_name)
if i % 5 == 0:
shutil.copyfile(os.path.join(os.path.join('work/dataset/Images', path), imgs_dir[i]), target_eval_path) else:
shutil.copyfile(os.path.join(os.path.join('work/dataset/Images', path), imgs_dir[i]), target_train_path)print('finished train val split!')finished train val split!
我们先看一下解压缩后的数据集长成什么样子,对比分析经典模型在Caltech101抽取16类mini版数据集上的效果
 简小派
简小派
简小派是一款AI原生求职工具,通过简历优化、岗位匹配、项目生成、模拟面试与智能投递,全链路提升求职成功率,帮助普通人更快拿到更好的 offer。
 123
查看详情
123
查看详情
 In [ ]
In [ ]
import osimport randomfrom matplotlib import pyplot as pltfrom PIL import Image
imgs = []
paths = os.listdir('work/dataset/Images')for path in paths:
img_path = os.path.join('work/dataset/Images', path) if os.path.isdir(img_path):
img_paths = os.listdir(img_path)
img = Image.open(os.path.join(img_path, random.choice(img_paths)))
imgs.append((img, path))
f, ax = plt.subplots(4, 4, figsize=(12,12))for i, img in enumerate(imgs[:16]):
ax[i//4, i%4].imshow(img[0])
ax[i//4, i%4].axis('off')
ax[i//4, i%4].set_title('label: %s' % img[1])
plt.show()
#数据集的定义class Dataset(paddle.io.Dataset):
"""
步骤一:继承paddle.io.Dataset类
"""
def __init__(self, transforms: Callable, mode: str ='train'):
"""
步骤二:实现构造函数,定义数据读取方式
"""
super(Dataset, self).__init__()
self.mode = mode
self.transforms = transforms
train_image_dir = config_parameters['train_image_dir']
eval_image_dir = config_parameters['eval_image_dir']
train_data_folder = paddle.vision.DatasetFolder(train_image_dir)
eval_data_folder = paddle.vision.DatasetFolder(eval_image_dir)
if self.mode == 'train':
self.data = train_data_folder elif self.mode == 'eval':
self.data = eval_data_folder def __getitem__(self, index):
"""
步骤三:实现__getitem__方法,定义指定index时如何获取数据,并返回单条数据(训练数据,对应的标签)
"""
data = np.array(self.data[index][0]).astype('float32')
data = self.transforms(data)
label = np.array([self.data[index][1]]).astype('int64')
return data, label
def __len__(self):
"""
步骤四:实现__len__方法,返回数据集总数目
"""
return len(self.data)
In [ ]
from paddle.vision import transforms as T#数据增强transform_train =T.Compose([T.Resize((256,256)), #T.RandomVerticalFlip(10),
#T.RandomHorizontalFlip(10),
T.RandomRotation(10),
T.Transpose(),
T.Normalize(mean=[0, 0, 0], # 像素值归一化
std =[255, 255, 255]), # transforms.ToTensor(), # transpose操作 + (img / 255),并且数据结构变为PaddleTensor
T.Normalize(mean=[0.50950350, 0.54632660, 0.57409690],# 减均值 除标准差
std= [0.26059777, 0.26041326, 0.29220656])# 计算过程:output[channel] = (input[channel] - mean[channel]) / std[channel]
])
transform_eval =T.Compose([ T.Resize((256,256)),
T.Transpose(),
T.Normalize(mean=[0, 0, 0], # 像素值归一化
std =[255, 255, 255]), # transforms.ToTensor(), # transpose操作 + (img / 255),并且数据结构变为PaddleTensor
T.Normalize(mean=[0.50950350, 0.54632660, 0.57409690],# 减均值 除标准差
std= [0.26059777, 0.26041326, 0.29220656])# 计算过程:output[channel] = (input[channel] - mean[channel]) / std[channel]
])
根据所使用的数据集需求实例化数据集类,并查看总样本量。
In [ ]train_dataset =Dataset(mode='train',transforms=transform_train)
eval_dataset =Dataset(mode='eval', transforms=transform_eval )#数据异步加载train_loader = paddle.io.DataLoader(train_dataset,
places=paddle.CUDAPlace(0),
batch_size=32,
shuffle=True,  #num_workers=2,
#use_shared_memory=True
)
eval_loader = paddle.io.DataLoader (eval_dataset,
places=paddle.CUDAPlace(0),
batch_size=32, #num_workers=2,
#use_shared_memory=True
)print('训练集样本量: {},验证集样本量: {}'.format(len(train_loader), len(eval_loader)))
#num_workers=2,
#use_shared_memory=True
)
eval_loader = paddle.io.DataLoader (eval_dataset,
places=paddle.CUDAPlace(0),
batch_size=32, #num_workers=2,
#use_shared_memory=True
)print('训练集样本量: {},验证集样本量: {}'.format(len(train_loader), len(eval_loader)))训练集样本量: 45,验证集样本量: 12
本次我们选取了经典的卷积神经网络resnet50,vgg19,mobilenet_v2来进行实验比较。
In [ ]network = paddle.vision.models.vgg19(num_classes=16)#模型封装model = paddle.Model(network)#模型可视化model.summary((-1, 3,256 , 256))In [ ]
network = paddle.vision.models.resnet50(num_classes=16)#模型封装model2 = paddle.Model(network)#模型可视化model2.summary((-1, 3,256 , 256))
#优化器选择class S*eBestModel(paddle.callbacks.Callback):
def __init__(self, target=0.5, path='work/best_model', verbose=0):
self.target = target
self.epoch = None
self.path = path def on_epoch_end(self, epoch, logs=None):
self.epoch = epoch def on_eval_end(self, logs=None):
if logs.get('acc') > self.target:
self.target = logs.get('acc')
self.model.s*e(self.path) print('best acc is {} at epoch {}'.format(self.target, self.epoch))
callback_visualdl = paddle.callbacks.VisualDL(log_dir='work/vgg19')
callback_s*ebestmodel = S*eBestModel(target=0.5, path='work/best_model')
callbacks = [callback_visualdl, callback_s*ebestmodel]
base_lr = config_parameters['lr']
epochs = config_parameters['epochs']def make_optimizer(parameters=None):
momentum = 0.9
learning_rate= paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=base_lr, T_max=epochs, verbose=False)
weight_decay=paddle.regularizer.L2Decay(0.0001)
optimizer = paddle.optimizer.Momentum(
learning_rate=learning_rate,
momentum=momentum,
weight_decay=weight_decay,
parameters=parameters) return optimizer
optimizer = make_optimizer(model.parameters())
model.prepare(optimizer,
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
model.fit(train_loader,
eval_loader,
epochs=100,
batch_size=1, # 是否打乱样本集
callbacks=callbacks,
verbose=1) # 日志展示格式
一个coordinate attention块可以被看作是一个计算单元,旨在增强Mobile Network中特征的表达能力。它可以将任何中间特征张量作为输入并通过转换输出了与张量具有相同size同时具有增强表征的作用。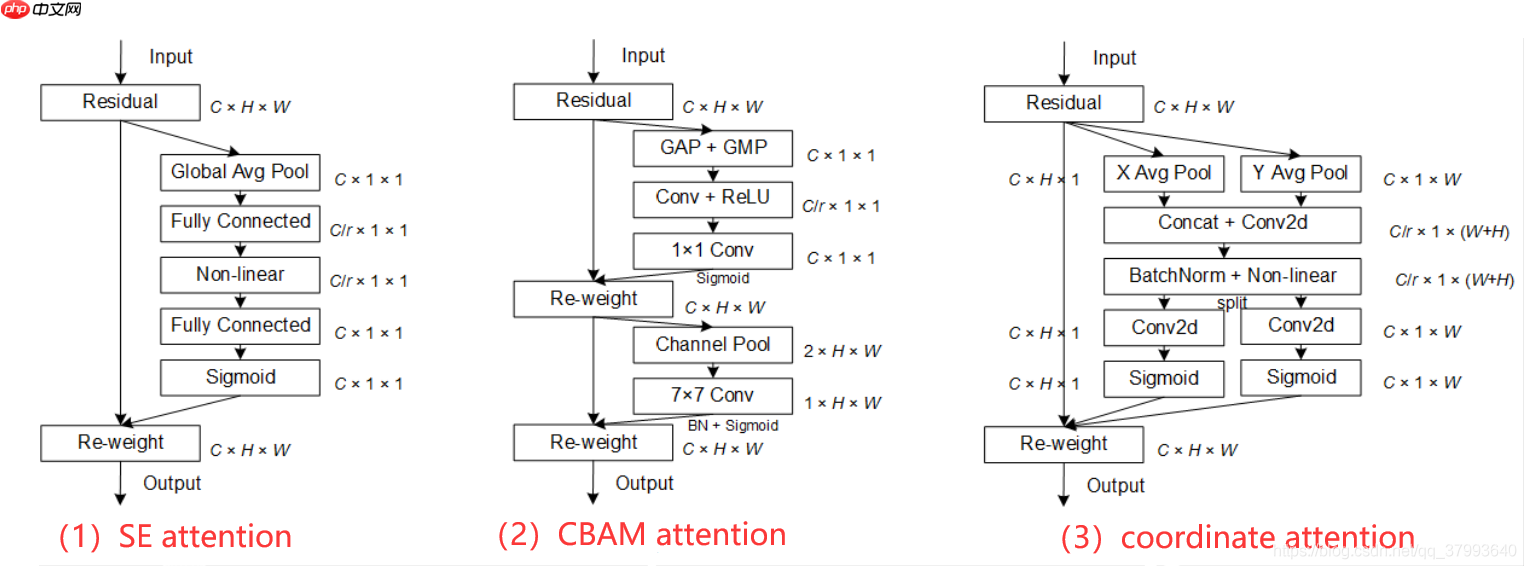
图1 CA模块细节示意图
In [ ]import paddlefrom paddle.fluid.layers.nn import transposeimport paddle.nn as nnimport mathimport paddle.nn.functional as Fclass h_sigmoid(nn.Layer):
def __init__(self):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6() def forward(self, x):
return self.relu(x + 3) / 6class h_swish(nn.Layer):
def __init__(self):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid() def forward(self, x):
return x * self.sigmoid(x)class CoordAtt(nn.Layer):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2D((None, 1))
self.pool_w = nn.AdaptiveAvgPool2D((1, None))
self.sigmoid = nn.Sigmoid()
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2D(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2D(mip)
self.act = h_swish()
self.conv_h = nn.Conv2D(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2D(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n,c,h,w = x.shape
x_h = self.pool_h(x)
x_w = transpose(self.pool_w(x),[0, 1, 3, 2])
y = paddle.concat([x_h, x_w], axis=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = paddle.split(y, [h, w], axis=2)
x_w = transpose(x_w,[0, 1, 3, 2])
a_h = self.sigmoid(self.conv_w(x_h))
a_w = self.sigmoid(self.conv_w(x_w))
out = identity * a_w * a_h return outif __name__ == '__main__':
x = paddle.randn(shape=[1, 16, 64, 128]) # b, c, h, w
ca_model = CoordAtt(inp=16,oup=16)
y = ca_model(x) print(y.shape)W1115 23:29:01.694252 143 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W1115 23:29:01.698771 143 device_context.cc:372] device: 0, cuDNN Version: 7.6.
[1, 16, 64, 128]
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/norm.py:648: UserWarning: When training, we now always track global mean and variance. "When training, we now always track global mean and variance.")
import paddle.nn.functional as F# 构建模型(Inception层)class Inception(paddle.nn.Layer):
def __init__(self, in_channels, c1, c2, c3, c4):
super(Inception, self).__init__() # 路线1,卷积核1x1
self.route1x1_1 = paddle.nn.Conv2D(in_channels, c1, kernel_size=1) # 路线2,卷积层1x1、卷积层3x3
self.route1x1_2 = paddle.nn.Conv2D(in_channels, c2[0], kernel_size=1)
self.route3x3_2 = paddle.nn.Conv2D(c2[0], c2[1], kernel_size=3, padding=1) # 路线3,卷积层1x1、卷积层5x5
self.route1x1_3 = paddle.nn.Conv2D(in_channels, c3[0], kernel_size=1)
self.route5x5_3 = paddle.nn.Conv2D(c3[0], c3[1], kernel_size=5, padding=2) # 路线4,池化层3x3、卷积层1x1
self.route3x3_4 = paddle.nn.MaxPool2D(kernel_size=3, stride=1, padding=1)
self.route1x1_4 = paddle.nn.Conv2D(in_channels, c4, kernel_size=1) def forward(self, x):
route1 = F.relu(self.route1x1_1(x))
route2 = F.relu(self.route3x3_2(F.relu(self.route1x1_2(x))))
route3 = F.relu(self.route5x5_3(F.relu(self.route1x1_3(x))))
route4 = F.relu(self.route1x1_4(self.route3x3_4(x)))
out = [route1, route2, route3, route4] return paddle.concat(out, axis=1) # 在通道维度(axis=1)上进行连接# 构建 BasicConv2d 层def BasicConv2d(in_channels, out_channels, kernel, stride=1, padding=0):
layer = paddle.nn.Sequential(
paddle.nn.Conv2D(in_channels, out_channels, kernel, stride, padding),
paddle.nn.BatchNorm2D(out_channels, epsilon=1e-3),
paddle.nn.ReLU()) return layer# 搭建网络class TowerNet(paddle.nn.Layer):
def __init__(self, in_channel, num_classes):
super(TowerNet, self).__init__()
self.b1 = paddle.nn.Sequential(
BasicConv2d(in_channel, out_channels=64, kernel=3, stride=2, padding=1),
paddle.nn.MaxPool2D(2, 2))
self.b2 = paddle.nn.Sequential(
BasicConv2d(64, 128, kernel=3, padding=1),
paddle.nn.MaxPool2D(2, 2))
self.b3 = paddle.nn.Sequential(
BasicConv2d(128, 256, kernel=3, padding=1),
paddle.nn.MaxPool2D(2, 2),
CoordAtt(256,256))
self.b4 = paddle.nn.Sequential(
BasicConv2d(256, 256, kernel=3, padding=1),
paddle.nn.MaxPool2D(2, 2),
CoordAtt(256,256))
self.b5 = paddle.nn.Sequential(
Inception(256, 64, (64, 128), (16, 32), 32),
paddle.nn.MaxPool2D(2, 2),
CoordAtt(256,256),
Inception(256, 64, (64, 128), (16, 32), 32),
paddle.nn.MaxPool2D(2, 2),
CoordAtt(256,256),
Inception(256, 64, (64, 128), (16, 32), 32))
self.AvgPool2D=paddle.nn.AvgPool2D(2)
self.flatten=paddle.nn.Flatten()
self.b6 = paddle.nn.Linear(256, num_classes) def forward(self, x):
x = self.b1(x)
x = self.b2(x)
x = self.b3(x)
x = self.b4(x)
x = self.b5(x)
x = self.AvgPool2D(x)
x = self.flatten(x)
x = self.b6(x) return x
In [ ]
model = paddle.Model(TowerNet(3, config_parameters['class_dim'])) model.summary((-1, 3, 256, 256))
#优化器选择class S*eBestModel(paddle.callbacks.Callback):
def __init__(self, target=0.5, path='work/best_model', verbose=0):
self.target = target
self.epoch = None
self.path = path def on_epoch_end(self, epoch, logs=None):
self.epoch = epoch def on_eval_end(self, logs=None):
if logs.get('acc') > self.target:
self.target = logs.get('acc')
self.model.s*e(self.path) print('best acc is {} at epoch {}'.format(self.target, self.epoch))
callback_visualdl = paddle.callbacks.VisualDL(log_dir='work/CA_Inception_Net')
callback_s*ebestmodel = S*eBestModel(target=0.5, path='work/best_model')
callbacks = [callback_visualdl, callback_s*ebestmodel]
base_lr = config_parameters['lr']
epochs = config_parameters['epochs']def make_optimizer(parameters=None):
momentum = 0.9
learning_rate= paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=base_lr, T_max=epochs, verbose=False)
weight_decay=paddle.regularizer.L2Decay(0.0002)
optimizer = paddle.optimizer.Momentum(
learning_rate=learning_rate,
momentum=momentum,
weight_decay=weight_decay,
parameters=parameters) return optimizer
optimizer = make_optimizer(model.parameters())
In [ ]
model.prepare(optimizer,
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
In [16]
model.fit(train_loader,
eval_loader,
epochs=100,
batch_size=1, # 是否打乱样本集
callbacks=callbacks,
verbose=1) # 日志展示格式
在增加了CA模块的注意力机制后,性能有了较大幅度的提升。 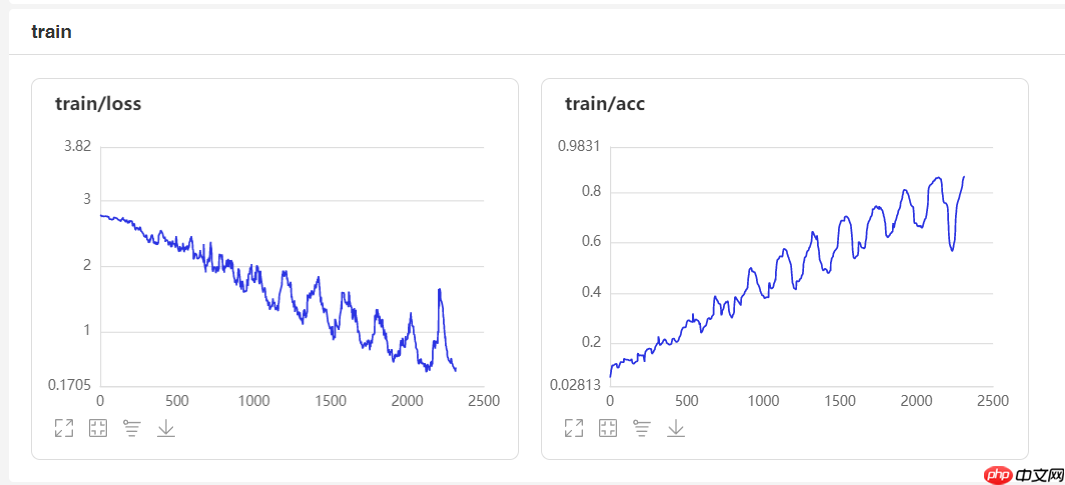

以上就是CoordAtt:即插即用的新注意力机制!助力改进任务的神器!的详细内容,更多请关注其它相关文章!
# ai
# 异步加载
# python
# 加载
# 重庆关键词推广网站排名
# 压缩包
# 解压缩
# 官网
# 鱼洞云网站推广
# 遵义网站推广产品
# 江苏推广和营销的关系
# 丝瓜seo1.3.0.2 apk
# 嘉兴营销推广厂家排名
# 利辛抖音推广营销
# 保险行业市场推广营销
# 下沙seo服务
# 温州抖音seo优化流程
# 数据结构
# 将其
# 一言
# 即插
# 即用
# 中文网
# type
# fig
# latte
# udio
# asic
# igs
# red
# cos
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
GPT-4使用混合大模型?研究证明MoE+指令调优确实让大模型性能超群
印象笔记开放旗下“印象 AI”,可一键生成思维导图、写文章等
PS AI修图免费平替来了!Stability AI又放大招,核弹级更新一键扩图
软通动力多项AI创新产品及应用亮相2025世界人工智能大会
五个IntelliJ IDEA插件,高效编写代码
WHEE使用教程
日入400万,第一批AI骗子已上岗
浪潮KaiwuDB:“快人一步” - 打造更懂物联网的数据库
推动企业数字化转型升级!“松江智造”摘世界人工智能大会重磅奖项
数字文明尼山对话 | 在东方圣城与AI潮流梦幻联动,看“智慧大脑”让数字山东更美好
优地网络助力新媒体拥抱人工智能时代
微软面向AI初学者推出免费网络课程
Ai智能机器人,chat-免注册登入,直接使用新版gpt4.0!
南京制造的国产工业机器人:在外资品牌竞争中突围,年销售1.8万台
数据科学,解码智能未来——Altair首次提出“Frictionless AI”概念
美图秀秀“AI 扩图”功能上线,可根据图像生成更大画幅
猿编程参加人工智能高峰论坛,推动人工智能教育解决方案在千所学校推行
V社回应拒绝上架含 AI 生成内容的游戏:审核政策正在调整中
阿里大文娱CTO郑勇:生成式AI将引发内容行业巨变,*制作机会挑战并存
即时 AI再次升级 30秒生成自带动效的网页 生成速度提升100%
探索AI前沿理念 2025全球人工智能技术大会在杭州开幕
OpenAI CEO 阿尔特曼到访日本,对全球 AI 协调合作表示乐观
世界人工智能大会高合发表演讲,HiPhi Y即将全球上市
磐镭发布全新 GeForce RTX 4080 ARMOUR 显卡,售价为 9499 元
12页线性代数笔记登GitHub热榜,还获得了Gilbert Strang大神亲笔题词
NVIDIA垄断AI市场90%份额:AMD性能追上80% 软件太不能打
百亿量化私募:量化投资进入“精耕细作”时代 AI带来行业新变革
云南首例达芬奇机器人微创心脏手术成功开展
OpenAI 静默关闭 AI 文本检测工具,准确率仅为 26%
大模型训练成本降低近一半!新加坡国立大学最新优化器已投入使用
解决导航“最后50米”难题 高德地图升级AR步行导航找终点功能
编程版GPT狂飙30星,AutoGPT危险了!
特斯拉人形机器人将于 7 月亮相上海 2025 世界人工智能大会
ChatGPT只讲这25个笑话!实验上千次有90%重复,网友:幽默是人类最后的尊严
这款在《自然通讯》发表的机器人,为变形金刚来到现实创造可能性
边喷火边跳踢踏舞,机器狗最新技能爆火全网!网友直呼真·热狗
AI框架生态峰会本周开幕 华为昇腾“朋友圈”再聚首 全球首个全模态大模型将登场
元宇宙迈入2.0时代,它和生成式人工智能有何关联吗?
联想戴炜:以全栈AI加速CT与IT融合,共建高质量算力网络
智能机器人正在彻底改变客户服务
国网辉南供电:无人机空中巡检 全力护航端午佳节
华为4G5G通信物联网收费标准公布,多年研发成果,十年花费近万亿
探索人工智能在物联网领域的影响与改变
Meta 为打造元宇宙不惜下血本:VR 开发者年薪高达百万美元
一家 380 亿美元的数据巨头,要掀起企业「AI 化」革命
Meta Connect 2025已确定时间为9月27-28,主题涵盖Quest 3与AI技术
日本学校探索引入 AI 和无人机:提高安保效率,节省劳动力
再度重仓 AI 赛道,SaaS 巨头 Salesforce 扩大 AIGC 风投基金规模
Xreal AR 眼镜用投屏盒子 Beam 发布:分体式设计,到手 699 元
网易加速行业AI大模型应用,将覆盖100多个应用场景
2025-07-18

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。

 #num_workers=2,
#use_shared_memory=True
)
eval_loader = paddle.io.DataLoader (eval_dataset,
places=paddle.CUDAPlace(0),
batch_size=32, #num_workers=2,
#use_shared_memory=True
)print('训练集样本量: {},验证集样本量: {}'.format(len(train_loader), len(eval_loader)))
#num_workers=2,
#use_shared_memory=True
)
eval_loader = paddle.io.DataLoader (eval_dataset,
places=paddle.CUDAPlace(0),
batch_size=32, #num_workers=2,
#use_shared_memory=True
)print('训练集样本量: {},验证集样本量: {}'.format(len(train_loader), len(eval_loader)))