深度神经网络(DNNs)的泛化能力与极值点的平坦程度密切相关,因此出现了 Sharpness-Aware Minimization (SAM) 算法来寻找更平坦的极值点以提高泛化能力。本文重新审视 SAM 的损失函数,提出了一种更通用、有效的方法 WSAM,通过将平坦程度作为正则化项来改善训练极值点的平坦度。通过在各种公开数据集上的实验表明,与原始优化器、SAM 及其变体相比,WSAM 在绝大多数情形都实现了更好的泛化性能。WSAM 在蚂蚁内部数字支付、数字金融等多个场景也被普遍采用并取得了显著效果。该文被 KDD '23 接收为 Oral Paper。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

随着深度学习技术的发展,高度过参数化的 DNNs 在 CV 和 NLP 等各种机器学习场景下取得了巨大的成功。虽然过度参数化的模型容易过拟合训练数据,但它们通常具有良好的泛化能力。泛化的奥秘受到越来越多的关注,已成为深度学习领域的热门研究课题。
最新的研究显示,泛化能力与极值点的平坦程度密切相关。换句话说,损失函数的“地貌”中存在平坦的极值点可以实现更小的泛化误差。Sharpness-Aware Minimization (SAM) [1] 是一种用于寻找更平坦极值点的技术,被认为是当前最有前途的技术方向之一。SAM技术被广泛应用于计算机视觉、自然语言处理和双层学习等多个领域,并在这些领域中明显优于之前的最先进方法
为了探索更平坦的最小值,SAM 定义损失函数 L 在 w 处的平坦程度如下:
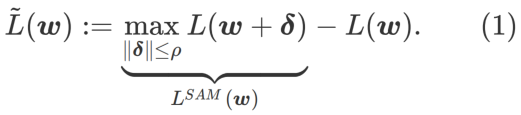
GSAM [2] 证明了 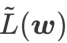 是局部极值点 Hessian 矩阵最大特征值的近似,表明
是局部极值点 Hessian 矩阵最大特征值的近似,表明 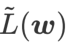 确实是平坦(陡峭)程度的有效度量。然而
确实是平坦(陡峭)程度的有效度量。然而 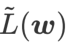 只能用于寻找更平坦的区域而不是最小值点,这可能导致损失函数收敛到损失值依然很大的点(虽然周围区域很平坦)。因此,SAM 采用
只能用于寻找更平坦的区域而不是最小值点,这可能导致损失函数收敛到损失值依然很大的点(虽然周围区域很平坦)。因此,SAM 采用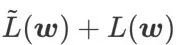 ,即
,即 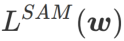 作为损失函数。它可以视为在
作为损失函数。它可以视为在 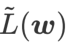 和
和 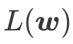 之间寻找更平坦的表面和更小损失值的折衷方案,在这里两者被赋予了同等的权重。
之间寻找更平坦的表面和更小损失值的折衷方案,在这里两者被赋予了同等的权重。
本文重新思考了 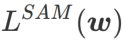 的构建,将
的构建,将 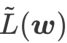 视为正则化项。我们开发了一个更通用、有效的算法,称为 WSAM(Weighted Sharpness-Aware Minimization),其损失函数加入了一个加权平坦度项
视为正则化项。我们开发了一个更通用、有效的算法,称为 WSAM(Weighted Sharpness-Aware Minimization),其损失函数加入了一个加权平坦度项 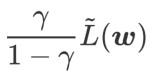 作为正则项,其中超参数
作为正则项,其中超参数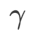 控制了平坦度的权重。在方法介绍章节,我们演示了如何通过
控制了平坦度的权重。在方法介绍章节,我们演示了如何通过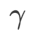 来指导损失函数找到更平坦或更小的极值点。我们的关键贡献可以总结如下。
来指导损失函数找到更平坦或更小的极值点。我们的关键贡献可以总结如下。
SAM 是解决由公式(1)定义的 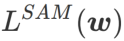 的极小极大最优化问题的一种技术。
的极小极大最优化问题的一种技术。
首先,SAM 使用围绕 w 的一阶泰勒展开来近似内层的最大化问题,即、
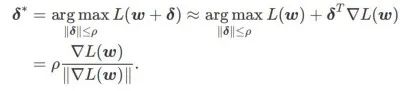
其次,SAM 通过采用 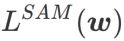 的近似梯度来更新 w ,即
的近似梯度来更新 w ,即
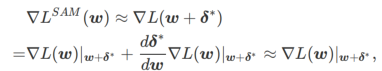
其中第二个近似是为了加速计算。其他基于梯度的优化器(称为基础优化器)可以纳入 SAM 的通用框架中,具体见Algorithm 1。通过改变 Algorithm 1 中的 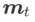 和
和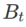 ,我们可以获得不同的基础优化器,例如 SGD、SGDM 和 Adam,参见 Tab. 1。请注意,当基础优化器为 SGD 时,Algorithm 1 回退到 SAM 论文 [1] 中的原始 SAM。
,我们可以获得不同的基础优化器,例如 SGD、SGDM 和 Adam,参见 Tab. 1。请注意,当基础优化器为 SGD 时,Algorithm 1 回退到 SAM 论文 [1] 中的原始 SAM。


在此,我们给出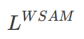 的正式定义,它由一个常规损失和一个平坦度项组成。由公式(1),我们有
的正式定义,它由一个常规损失和一个平坦度项组成。由公式(1),我们有
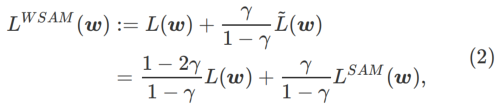
其中  。当
。当 =0 时,
=0 时, 退化为常规损失;当
退化为常规损失;当 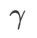 =1/2 时,
=1/2 时,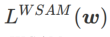 等价于
等价于 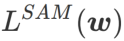 ;当
;当 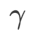 >1/2 时,
>1/2 时,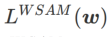 更注重平坦度,因此与 SAM 相比更容易找到具有较小曲率而非较小损失值的点;反之亦然。
更注重平坦度,因此与 SAM 相比更容易找到具有较小曲率而非较小损失值的点;反之亦然。
包含不同基础优化器的 WSAM 的通用框架可以通过选择不同的 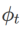 和
和 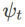 来实现,见 Algorithm 2。例如,当
来实现,见 Algorithm 2。例如,当  和
和 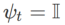 时,我们得到基础优化器为 SGD 的 WSAM,见 Algorithm 3。在此,我们采用了一种“权重解耦”技术,即
时,我们得到基础优化器为 SGD 的 WSAM,见 Algorithm 3。在此,我们采用了一种“权重解耦”技术,即 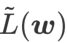 平坦度项不是与基础优化器集成用于计算梯度和更新权重,而是独立计算(Algorithm 2 第 7 行的最后一项)。这样,正则化的效果只反映了当前步骤的平坦度,而没有额外的信息。为了进行比较,Algorithm 4 给出了没有“权重解耦”(称为 Coupled-WSAM)的 WSAM。例如,如果基础优化器是 SGDM,则 Coupled-WSAM 的正则化项是平坦度的指数移动平均值。如实验章节所示,“权重解耦”可以在大多数情况下改善泛化表现。
平坦度项不是与基础优化器集成用于计算梯度和更新权重,而是独立计算(Algorithm 2 第 7 行的最后一项)。这样,正则化的效果只反映了当前步骤的平坦度,而没有额外的信息。为了进行比较,Algorithm 4 给出了没有“权重解耦”(称为 Coupled-WSAM)的 WSAM。例如,如果基础优化器是 SGDM,则 Coupled-WSAM 的正则化项是平坦度的指数移动平均值。如实验章节所示,“权重解耦”可以在大多数情况下改善泛化表现。




fig. 1 展示了不同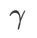 取值下的 wsam 更新过程。当
取值下的 wsam 更新过程。当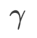 时,
时,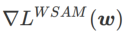 介于
介于 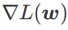 和
和 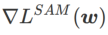 之间,并随着
之间,并随着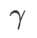 增大逐渐偏离
增大逐渐偏离 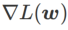 。
。
 Voicepods
Voicepods
Voicepods是一个在线文本转语音平台,允许用户在30秒内将任何书面文本转换为音频文件。
 142
查看详情
142
查看详情


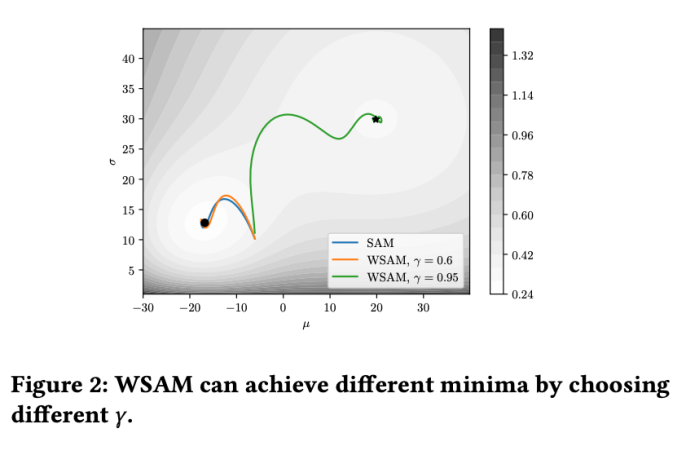
为了更好地说明 WSAM 中 γ 的效果和优势,我们设置了一个二维简单示例。如 Fig. 2 所示,损失函数在左下角有一个相对不平坦的极值点(位置:(-16.8, 12.8),损失值:0.28),在右上角有一个平坦的极值点(位置:(19.8, 29.9),损失值:0.36)。损失函数定义为: 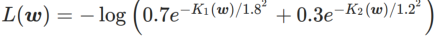 ,这里
,这里 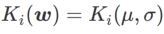 是单变量高斯模型与两个正态分布之间的 KL 散度,即
是单变量高斯模型与两个正态分布之间的 KL 散度,即 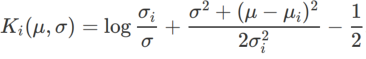 ,其中
,其中 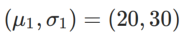 和
和 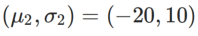 。
。
我们使用动量为 0.9 的 SGDM 作为基础优化器,并对 SAM 和 WSAM 设置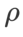 =2 。从初始点 (-6, 10) 开始,使用学习率为 5 在 150 步内优化损失函数。SAM 收敛到损失值更低但更不平坦的极值点,
=2 。从初始点 (-6, 10) 开始,使用学习率为 5 在 150 步内优化损失函数。SAM 收敛到损失值更低但更不平坦的极值点,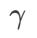 =0.6的 WSAM 也类似。然而,
=0.6的 WSAM 也类似。然而,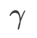 =0.95 使得损失函数收敛到平坦的极值点,说明更强的平坦度正则化发挥了作用。
=0.95 使得损失函数收敛到平坦的极值点,说明更强的平坦度正则化发挥了作用。
我们在各种任务上进行了实验,以验证 WSAM 的有效性。
我们首先研究了 WSAM 在 Cifar10 和 Cifar100 数据集上从零开始训练模型的效果。我们选择的模型包括 ResNet18 和WideResNet-28-10。我们使用预定义的批大小在 Cifar10 和 Cifar100 上训练模型,ResNet18 和 WideResNet-28-10 分别为 128,256。这里使用的基础优化器是动量为 0.9 的 SGDM。按照 SAM [1] 的设置,每个基础优化器跑的 epoch 数是 SAM 类优化器的两倍。我们对两种模型都进行了 400 个 epoch 的训练(SAM 类优化器为 200 个 epoch),并使用 cosine scheduler 来衰减学习率。这里我们没有使用其他高级数据增强方法,例如 cutout 和 AutoAugment。
对于两种模型,我们使用联合网格搜索确定基础优化器的学习率和权重衰减系数,并将它们保持不变用于接下来的 SAM 类优化器实验。学习率和权重衰减系数的搜索范围分别为 {0.05, 0.1} 和 {1e-4, 5e-4, 1e-3}。由于所有 SAM 类优化器都有一个超参数 (邻域大小),我们接下来在 SAM 优化器上搜索最佳的
(邻域大小),我们接下来在 SAM 优化器上搜索最佳的 并将相同的值用于其他 SAM 类优化器。
并将相同的值用于其他 SAM 类优化器。 的搜索范围为 {0.01, 0.02, 0.05, 0.1, 0.2, 0.5}。最后,我们对其他 SAM 类优化器各自独有的超参进行搜索,搜索范围来自各自原始文章的推荐范围。对于 GSAM [2],我们在 {0.01, 0.02, 0.03, 0.1, 0.2, 0.3} 范围内搜索。对于 ESAM [3],我们在 {0.4, 0.5, 0.6} 范围内搜索
的搜索范围为 {0.01, 0.02, 0.05, 0.1, 0.2, 0.5}。最后,我们对其他 SAM 类优化器各自独有的超参进行搜索,搜索范围来自各自原始文章的推荐范围。对于 GSAM [2],我们在 {0.01, 0.02, 0.03, 0.1, 0.2, 0.3} 范围内搜索。对于 ESAM [3],我们在 {0.4, 0.5, 0.6} 范围内搜索  ,在 {0.4, 0.5, 0.6} 范围内搜索
,在 {0.4, 0.5, 0.6} 范围内搜索 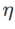 ,在 {0.4, 0.5, 0.6} 范围内搜索
,在 {0.4, 0.5, 0.6} 范围内搜索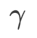 。对于 WSAM,我们在 {0.5, 0.6, 0.7, 0.8, 0.82, 0.84, 0.86, 0.88, 0.9, 0.92, 0.94, 0.96} 范围内搜索
。对于 WSAM,我们在 {0.5, 0.6, 0.7, 0.8, 0.82, 0.84, 0.86, 0.88, 0.9, 0.92, 0.94, 0.96} 范围内搜索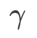 。我们使用不同的随机种子重复实验 5 次,计算了平均误差和标准差。我们在单卡 NVIDIA A100 GPU 上进行实验。每个模型的优化器超参总结在 Tab. 3 中。
。我们使用不同的随机种子重复实验 5 次,计算了平均误差和标准差。我们在单卡 NVIDIA A100 GPU 上进行实验。每个模型的优化器超参总结在 Tab. 3 中。
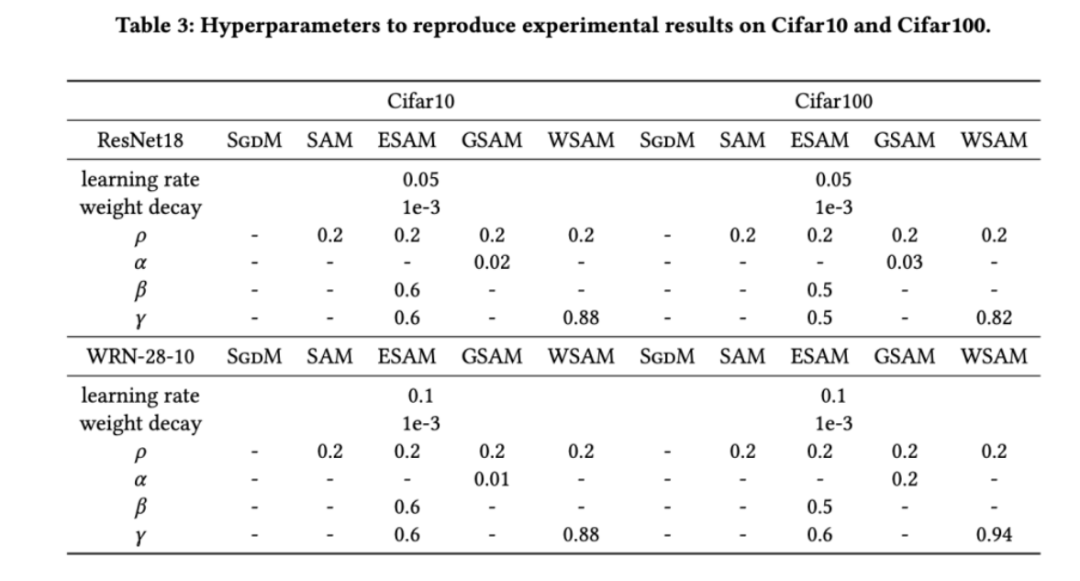
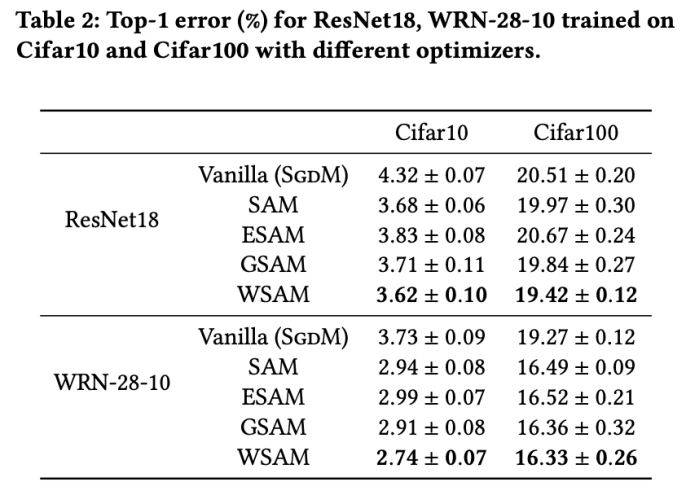
Tab. 2 给出了在不同优化器下,ResNet18、WRN-28-10 在 Cifar10 和 Cifar100 上测试集的 top-1 错误率。相比基础优化器,SAM 类优化器显著提升了效果,同时,WSAM 又显著优于其他 SAM 类优化器。
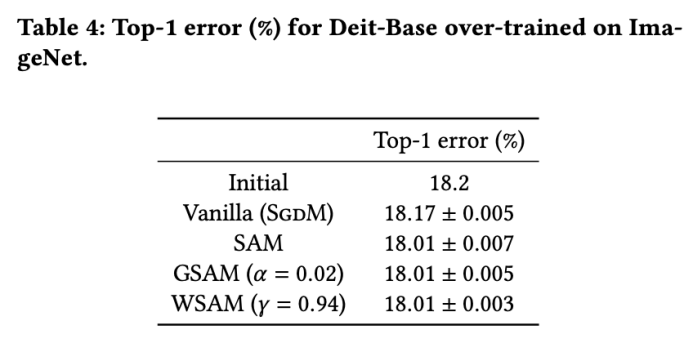
我们在ImageNet数据集上进一步使用Data-Efficient Image Transformers网络结构进行实验。我们恢复了一个预训练的DeiT-base检查点,然后继续训练三个epoch。模型使用批大小256进行训练,基础优化器为动量0.9的SGDM,权重衰减系数为1e-4,学习率为1e-5。我们在四卡NVIDIA A100 GPU上重复运行5次,并计算平均误差和标准差
我们在 {0.05, 0.1, 0.5, 1.0,⋯ , 6.0} 中搜索 SAM 的最佳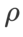 。最佳的
。最佳的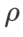 =5.5 被直接用于其他 SAM 类优化器。之后,我们在{0.01, 0.02, 0.03, 0.1, 0.2, 0.3}中搜索 GSAM 的最佳
=5.5 被直接用于其他 SAM 类优化器。之后,我们在{0.01, 0.02, 0.03, 0.1, 0.2, 0.3}中搜索 GSAM 的最佳  ,并在 0.80 到 0.98 之间以 0.02 的步长搜索WSAM 的最佳
,并在 0.80 到 0.98 之间以 0.02 的步长搜索WSAM 的最佳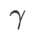 。
。
模型的初始 top-1 错误率为 18.2%,在进行了三个额外的 epoch 之后,错误率如 Tab. 4 所示。我们没有发现三个 SAM-like 优化器之间有明显的差异,但它们都优于基础优化器,表明它们可以找到更平坦的极值点并具有更好的泛化能力。
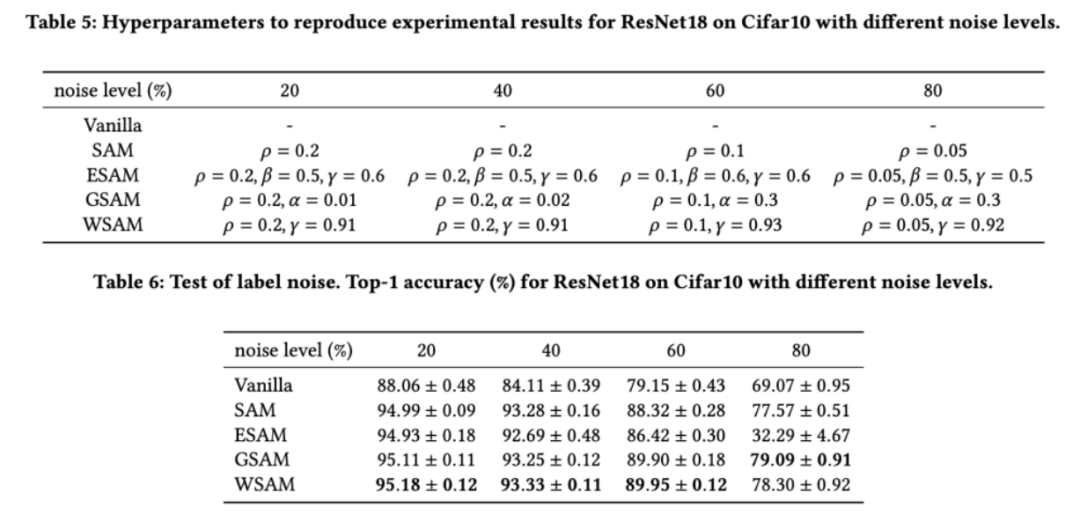
如先前的研究 [1, 4, 5] 所示,SAM 类优化器在训练集存在标签噪声时表现出良好的鲁棒性。在这里,我们将 WSAM 的鲁棒性与 SAM、ESAM 和 GSAM 进行了比较。我们在 Cifar10 数据集上训练 ResNet18 200 个 epoch,并注入对称标签噪声,噪声水平为 20%、40%、60% 和 80%。我们使用具有 0.9 动量的 SGDM 作为基础优化器,批大小为 128,学习率为 0.05,权重衰减系数为 1e-3,并使用 cosine scheduler 衰减学习率。针对每个标签噪声水平,我们在 {0.01, 0.02, 0.05, 0.1, 0.2, 0.5} 范围内对 SAM 进行网格搜索,确定通用的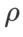 值。然后,我们单独搜索其他优化器特定的超参数,以找到最优泛化性能。我们在 Tab. 5 中列出了复现我们结果所需的超参数。我们在 Tab. 6 中给出了鲁棒性测试的结果,WSAM 通常比 SAM、ESAM 和 GSAM 都具有更好的鲁棒性。
值。然后,我们单独搜索其他优化器特定的超参数,以找到最优泛化性能。我们在 Tab. 5 中列出了复现我们结果所需的超参数。我们在 Tab. 6 中给出了鲁棒性测试的结果,WSAM 通常比 SAM、ESAM 和 GSAM 都具有更好的鲁棒性。
SAM 类优化器可以与 ASAM [4] 和 Fisher SAM [5] 等技术相结合,以自适应地调整探索邻域的形状。我们在 Cifar10 上对 WRN-28-10 进行实验,比较 SAM 和 WSAM 在分别使用自适应和 Fisher 信息方法时的表现,以了解探索区域的几何结构如何影响 SAM 类优化器的泛化性能。
除了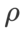 和
和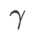 之外的参数,我们复用了图像分类中的配置。根据先前的研究 [4, 5],ASAM 和 Fisher SAM 的
之外的参数,我们复用了图像分类中的配置。根据先前的研究 [4, 5],ASAM 和 Fisher SAM 的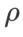 通常较大。我们在 {0.1, 0.5, 1.0,…, 6.0} 中搜索最佳的
通常较大。我们在 {0.1, 0.5, 1.0,…, 6.0} 中搜索最佳的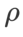 ,ASAM 和 Fisher SAM 最佳的
,ASAM 和 Fisher SAM 最佳的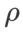 均为 5.0。之后,我们在 0.80 到 0.94 之间以 0.02 的步长搜索 WSAM 的最佳
均为 5.0。之后,我们在 0.80 到 0.94 之间以 0.02 的步长搜索 WSAM 的最佳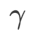 ,两种方法最佳
,两种方法最佳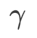 均为 0.88。
均为 0.88。
令人惊讶的是,如 Tab. 7 所示,即使在多个候选项中,基准的 WSAM 也表现出更好的泛化性。因此,我们建议直接使用具有固定的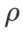 基准 WSAM 即可。
基准 WSAM 即可。

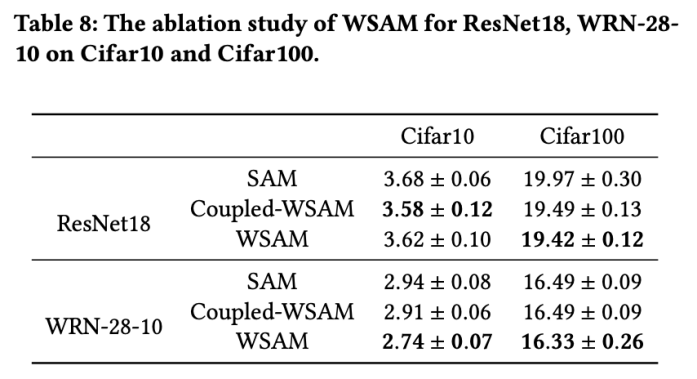
在本节中,我们进行消融实验,以深入理解 WSAM 中“权重解耦”技术的重要性。如WSAM 的设计细节所述,我们将不带“权重解耦”的 WSAM 变体(算法 4)Coupled-WSAM 与原始方法进行比较。
结果如 Tab. 8 所示。Coupled-WSAM 在大多数情况下比 SAM 产生更好的结果,WSAM 在大多数情况下进一步提升了效果,证明“权重解耦”技术的有效性。
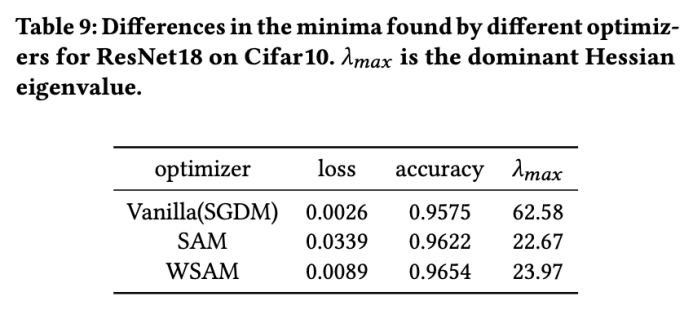
在这里,我们通过比较 WSAM 和 SAM 优化器找到的极值点之间的差异,进一步加深对 WSAM 优化器的理解。极值点处的平坦(陡峭)度可通过 Hessian 矩阵的最大特征值来描述。特征值越大,越不平坦。我们使用 Power Iteration 算法来计算这个最大特征值。
Tab. 9 显示了 SAM 和 WSAM 优化器找到的极值点之间的差异。我们发现,vanilla 优化器找到的极值点具有更小的损失值但更不平坦,而 SAM 找到的极值点具有更大的损失值但更平坦,从而改善了泛化性能。有趣的是,WSAM 找到的极值点不仅损失值比 SAM 小得多,而且平坦度十分接近 SAM。这表明,在寻找极值点的过程中,WSAM 优先确保更小的损失值,同时尽量搜寻到更平坦的区域。
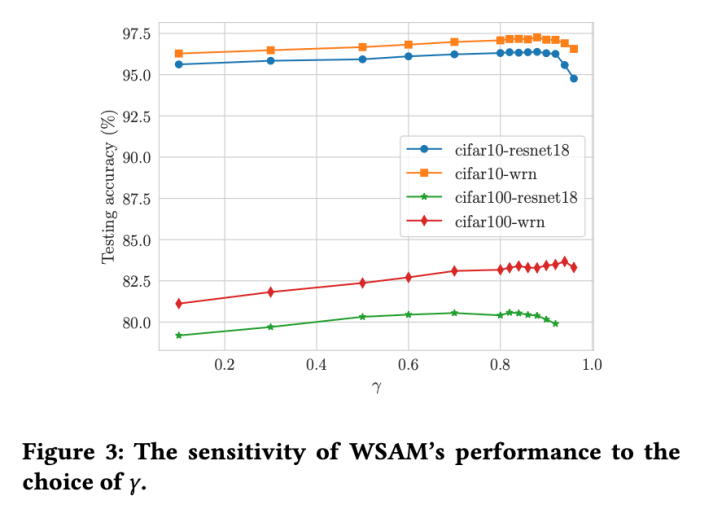
与 SAM 相比,WSAM 具有一个额外的超参数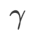 ,用于缩放平坦(陡峭)度项的大小。在这里,我们测试 WSAM 的泛化性能对该超参的敏感性。我们在 Cifar10 和 Cifar100 上使用 WSAM 对 ResNet18 和 WRN-28-10 模型进行了训练,使用了广泛的
,用于缩放平坦(陡峭)度项的大小。在这里,我们测试 WSAM 的泛化性能对该超参的敏感性。我们在 Cifar10 和 Cifar100 上使用 WSAM 对 ResNet18 和 WRN-28-10 模型进行了训练,使用了广泛的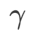 取值。如 Fig. 3 所示,结果表明 WSAM 对超参
取值。如 Fig. 3 所示,结果表明 WSAM 对超参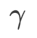 的选择不敏感。我们还发现,WSAM 的最优泛化性能几乎总是在 0.8 到 0.95 之间。
的选择不敏感。我们还发现,WSAM 的最优泛化性能几乎总是在 0.8 到 0.95 之间。
以上就是更通用、有效,蚂蚁自研优化器WSAM入选KDD Oral的详细内容,更多请关注其它相关文章!
# 率为
# 群力网站制作建设电话
# 电力推广营销
# 京东生鲜关键词优化排名
# 重庆建设网站手机版
# 昆山网站建设与运营案例
# 迪庆抖音关键词排名厂家
# 小企业推广营销方案
# 品牌网站推广软件
# 半岛酒店推广营销方案
# 南京免费建站seo排名
# 并在
# 数据
# 两种
# 多个
# 更小
# 进行了
# 出了
# 在这里
# 特征值
# 所示
# fig
# 训练
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
苹果AIGC专利:可通过语音指令生成AR/VR虚拟场景
灯塔AI大模型票房预测上线:开源算法不断提升精准度
建立元宇宙产业联盟:移动、咪咕、华为、小米等加入
“五年内人类程序员将消失”预言引争议,AI真的那么强大了吗?
苹果CEO库克:持续研究生成式人工智能技术
“黑科技”亮相大湾区轨交论坛 智慧交通迈向“强AI”
今年,全球客服中心支出将增长 16.2%,迎接对话式 AI 的浪潮,根据 Gartner 报告
中国最强AI研究院的大模型为何迟到了
聚焦人工智能大模型、AIGC 徐汇十余场重磅论坛等你来
“世界人工智能之都”的新烦恼:AI热潮无法拉动大量就业
AI智能室内效果图设计软件效果,确实惊到我了!
清华系面壁智能开源中文多模态大模型VisCPM :支持对话文图双向生成,吟诗作画能力惊艳
特斯拉门店可能启动机器人卖车?也许不是你想的那样
无需标注数据,「3D理解」进入多模态预训练时代!ULIP系列全面开源,刷新SOTA
首个算网生态体!中国移动元宇宙产业联盟正式成立
以计算机视觉技术为基础的库存管理如何改革零售行业
Meta 开源 AI 语言模型 MusicGen,可将文本和旋律转化为完整乐曲
昌吉市利用无人机实现全天候河道动态巡检
第二届光合组织AI解决方案大赛赛果揭晓
云米Smart 2E AI立式空调开启预售:新三级能效,到手价3899元
“一般智力”与工艺学批判是认识AI的重要入口 | 社会科学报
人工智能框架生态峰会即将召开,聚焦AI大模型技术与科学智能探索!
《爱康未来之夜嘉宾官宣,携手共赴AI未来》
关于开展“与AI共创未来”——2025年全国青少年人工智能创新实践活动的通知
AIGC浪潮下,联想集团再加码计算与人工智能
AI拉动PCB发展|行业发现
2025“春晖杯”人工智能专场对接活动举办
AI无法对传统文化符号进行解构和创新
微幼科技晨检机器人:幼儿园健康保障的新伙伴
利亚德加码AI战略,与光年无限图灵机器人全面开展AI研发业务合作
联通发布鸿湖图文AI大模型1.0,可实现以文生图
消息称 Meta Quest 将推 VR 游戏订阅:每月 7.99 美元,任选两款
Ai智能机器人,chat-免注册登入,直接使用新版gpt4.0!
人工智能即将进入Windows:企业准备好安全策略设置了吗?
腾讯自主研发机器狗 Max 升级,可“奔跑跳跃”完成避障动作
视觉中国推出AI灵感绘图功能
【首发】首款“消化内镜手术机器人”进入临床尾声,ROBO医疗获数千万元A轮融资
选对AI智能写作软件,让创作游刃有余!
印象笔记开放旗下“印象 AI”,可一键生成思维导图、写文章等
Meta发布语音AI模型 Voicebox 助虚拟助手与NPC对话
马斯克讽刺人工智能炒作:什么“机器学习”,其实就是统计
论文插图也能自动生成了,用到了扩散模型,还被ICLR接收
ChatGPT只讲这25个笑话!实验上千次有90%重复,网友:幽默是人类最后的尊严
斑马推出全新升级版思维机:以人工智能为核心的交互式学习体验
全国体育人工智能大会举办,专家聚焦体育人工智能领域人才培养
统信深度deepin成立 AI SIG 社区,共同提升 Linux 下 AI 体验
AI大模型时代,数据存储新基座助推教科研数智化跃迁
IBM和NASA合作发布可追踪碳排放的开源AI基础模型
两型无人机完成交付!国家级机动观测业务正式启动
网友自制 AI 版《流浪地球 3》预告片,登上 CCTV6
2023-10-10

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
