一般情况下,大型语言模型的部署通常采用"预训练-微调"的方式。然而,当对多个任务(如个性化助手)进行基础模型的微调时,训练和服务的成本会变得非常高。低秩适配(LowRank Adaptation,LoRA)是一种高效的参数微调方法,通常用于将基础模型适配到多个任务上,从而生成大量派生的LoRA适配程序
重新写作: 批量推理在服务过程中提供了许多机会,这种模式被证明可以通过微调适配器权重来实现与完全微调相当的性能。虽然这种方法可以实现低延迟的单个适配器推理和跨适配器的串行执行,但在同时为多个适配器提供服务时,会显著降低整体服务吞吐量并增加总延迟。因此,如何解决这些微调变体的大规模服务问题仍然未知
近期有来自UC伯克利、斯坦福等高校的研究人员在一篇论文中提出了一种被称为S-LoRA的新微调方法
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

S-LoRA 是专为众多 LoRA 适配程序的可扩展服务而设计的系统,它将所有适配程序存储在主内存中,并将当前运行查询所使用的适配程序取到 GPU 内存中。
S-LoRA 提出了「统一分页」(Unified Paging)技术,即使用统一的内存池来管理不同等级的动态适配器权重和不同序列长度的 KV 缓存张量。此外,S-LoRA 还采用了新的张量并行策略和高度优化的定制 CUDA 内核,以实现 LoRA 计算的异构批处理。
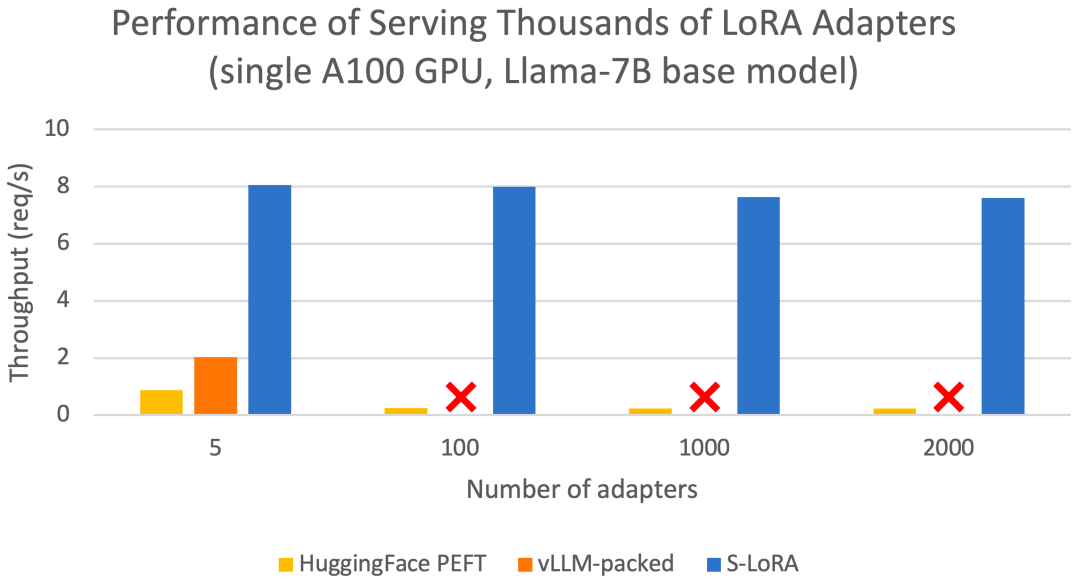
这些功能允许S-LoRA以较小的成本在单个或多个GPU上为数千个LoRA适配器提供服务(同时为2000个适配器提供服务),并将额外的LoRA计算成本降至最低。相比之下,vLLM-packed需要维护多个权重副本,并且由于GPU内存限制,只能为少于5个适配器提供服务
与 HuggingFace PEFT 和 vLLM(仅支持 LoRA 服务)等最先进的库相比,S-LoRA 的吞吐量最多可提高 4 倍,服务的适配器数量可增加几个数量级。因此,S-LoRA 能够为许多特定任务的微调模型提供可扩展的服务,并为大规模定制微调服务提供了潜力。
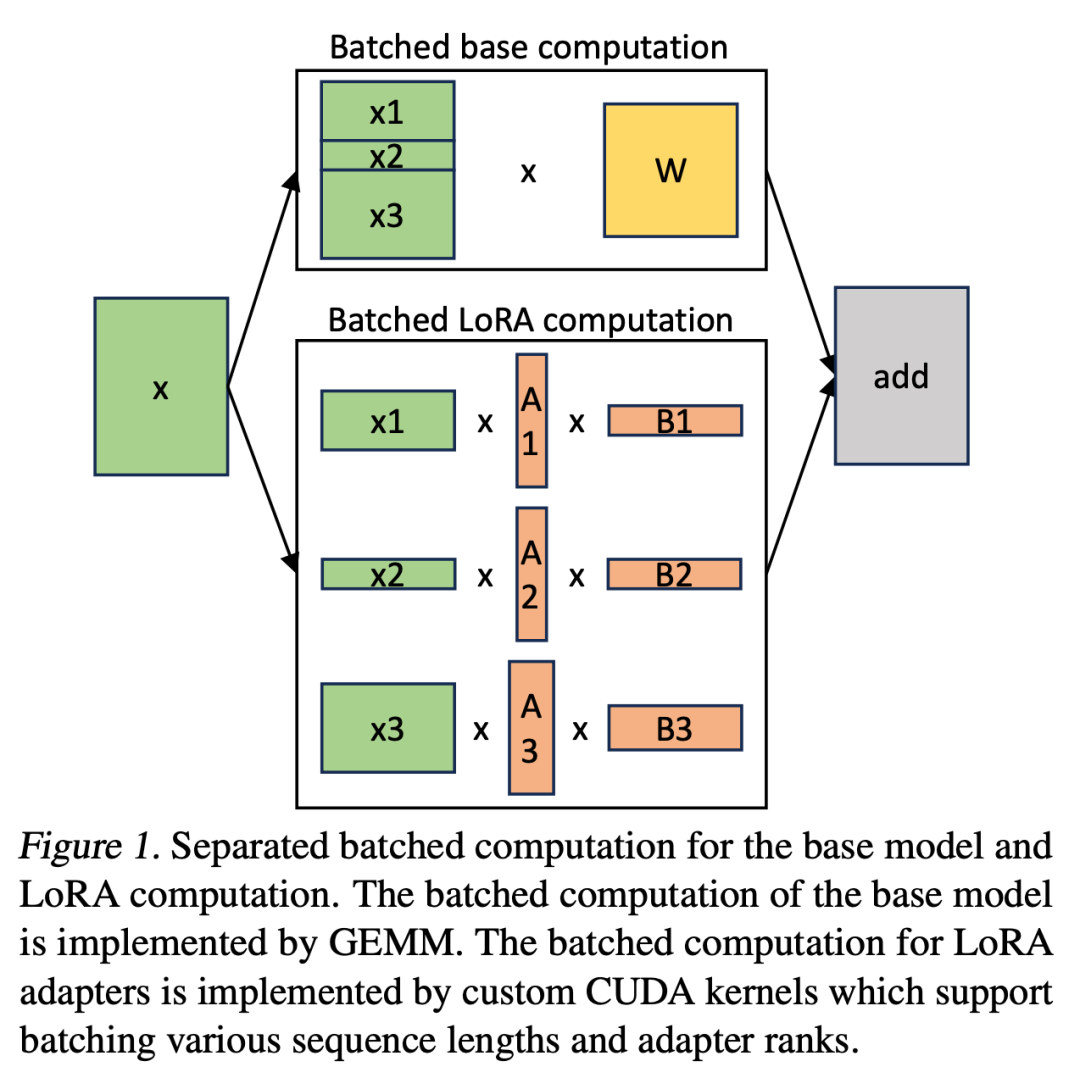
S-LoRA包含三个主要创新部分。第四部分介绍了批处理策略,该策略用于分解base模型和LoRA适配器之间的计算。此外,研究人员还解决了需求调度的难题,包括适配器集群和准入控制等方面。跨并发适配器的批处理能力给内存管理带来了新的挑战。第五部分,研究人员将PagedAttention推广到Unfied Paging,支持动态加载LoRA适配器。这种方法使用统一的内存池以分页方式存储KV缓存和适配器权重,可以减少碎片并平衡KV缓存和适配器权重的动态变化大小。最后,第六部分介绍了新的张量并行策略,能够高效地解耦base模型和LoRA适配器
以下為重點內容:
对于单个适配器,Hu等人(2025)提出了一种推荐的方法,即将适配器权重与基础模型权重合并,从而得到一个新模型(参见公式1)。这样做的好处是,在推理过程中不会有额外的适配器开销,因为新模型的参数数量与基础模型相同。实际上,这也是LoRA工作最初的一个显著特点
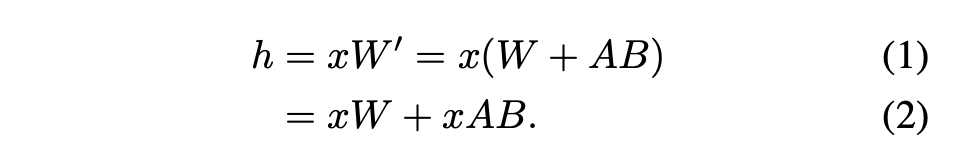
本文指出,将 LoRA 适配器合并到 base 模型中对于多 LoRA 高吞吐量服务设置来说效率很低。取而代之的是,研究者建议实时计算 LoRA 计算 xAB(如公式 2 所示)。
在 S-LoRA 中,计算 base 模型被批处理,然后使用定制的 CUDA 内核分别执行所有适配器的附加 xAB。这一过程如图 1 所示。研究者没有使用填充和 BLAS 库中的批处理 GEMM 内核来计算 LoRA,而是实施了定制的 CUDA 内核,以便在不使用填充的情况下实现更高效的计算,实施细节在第 5.3 小节中。
如果将 LoRA 适配器存储在主内存中,它们的数量可能会很大,但当前运行批所需的 LoRA 适配器数量是可控的,因为批大小受 GPU 内存的限制。为了利用这一优势,研究者将所有的 LoRA 适配卡都存储在主内存中,并在为当前正在运行的批进行推理时,仅将该批所需的 LoRA 适配卡取到 GPU RAM 中。在这种情况下,可服务的适配器最大数量受限于主内存大小。图 2 展示了这一过程。第 5 节也讨论了高效管理内存的技术
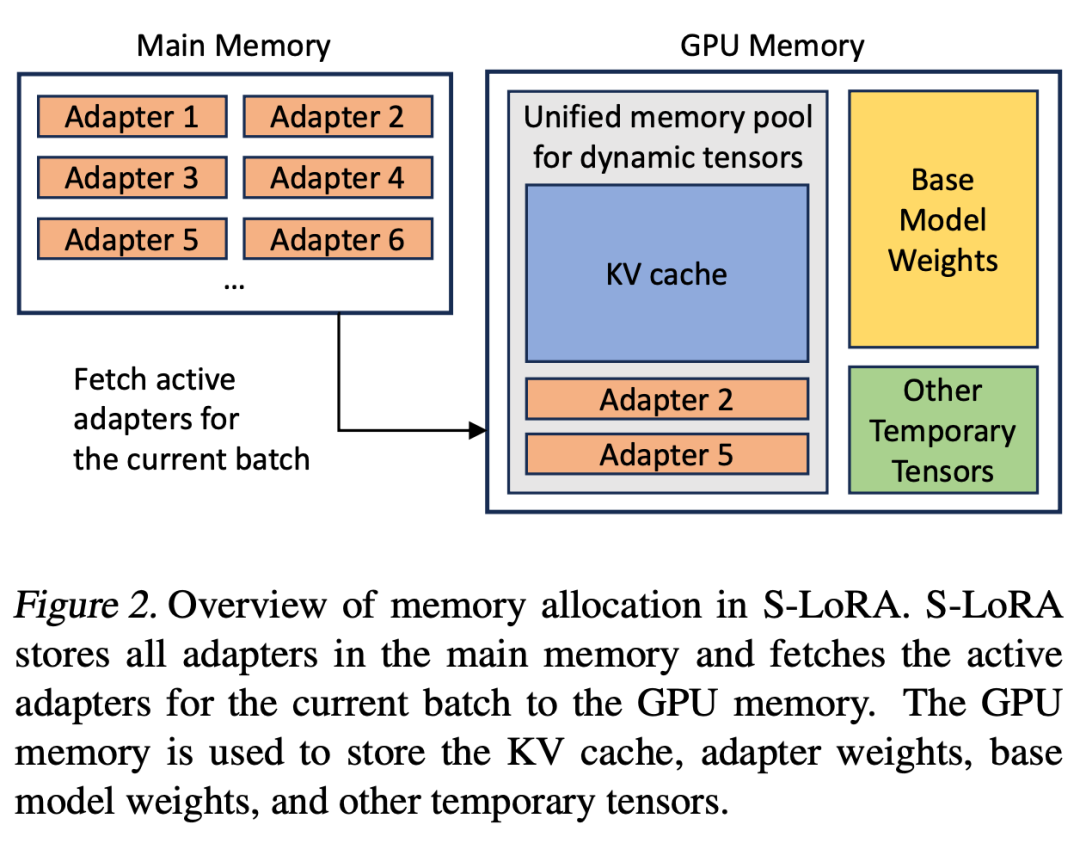
与为单个 base 模型提供服务相比,同时为多个 LoRA 适配卡提供服务会带来新的内存管理挑战。为了支持多个适配器,S-LoRA 将它们存储在主内存中,并将当前运行批所需的适配器权重动态加载到 GPU RAM 中。
在这个过程中,存在两个明显的挑战。首先是内存碎片问题,这是由于动态加载和卸载不同大小的适配器权重所导致的。其次是适配器加载和卸载所带来的延迟开销。为了有效解决这些问题,研究者提出了「统一分页」的概念,并通过预取适配器权重的方式来实现 I/O 和计算的重叠
Unified Paging
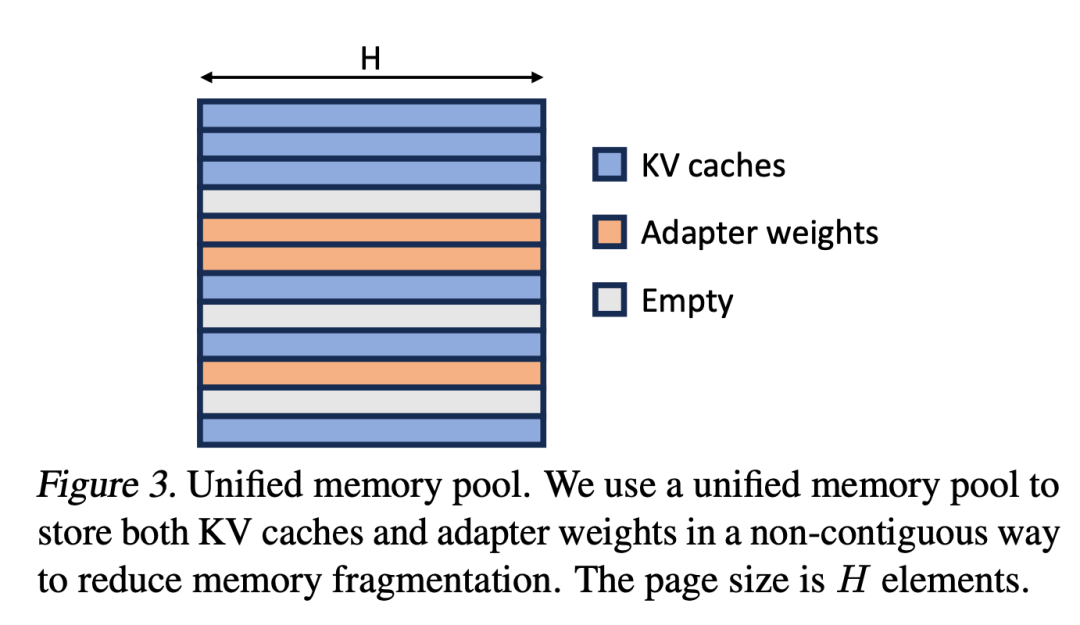
研究者将PagedAttention的概念扩展为统一分页(Unified Paging)。统一分页不仅用于管理KV缓存,还用于管理适配器权重。统一分页使用统一内存池来联合管理KV缓存和适配器权重。为了实现这一目标,他们首先为内存池静态分配了一个大缓冲区,该缓冲区利用了所有可用空间,除了用于存储基础模型权重和临时激活张量的空间。KV缓存和适配器权重以分页的方式存储在内存池中,每个页面对应一个H向量。因此,序列长度为S的KV缓存张量占用S页,而R级的LoRA权重张量占用R页。图3展示了内存池的布局,其中KV缓存和适配器权重以交错和非连续的方式存储。这种方法大大减少了碎片化,确保不同级别的适配器权重能够以结构化和系统化的方式与动态KV缓存共存
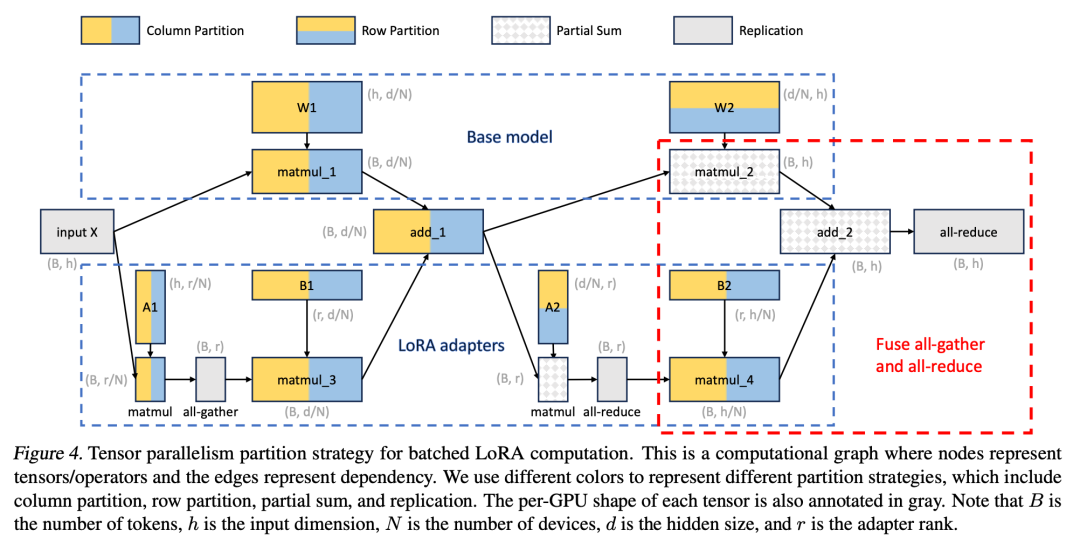
此外,研究者为批量 LoRA 推断设计了新颖的张量并行策略,以支持大型 Transformer 模型的多 GPU 推断。张量并行是应用最广泛的并行方法,因为它的单程序多数据模式简化了其实施和与现有系统的集成。张量并行可以减少为大模型提供服务时每个 GPU 的内存使用量和延迟。在本文设置中,额外的 LoRA 适配器引入了新的权重矩阵和矩阵乘法,这就需要为这些新增项目制定新的分区策略。
最终,研究人员通过为Llama-7B/13B/30B/70B提供服务来评估S-LoRA
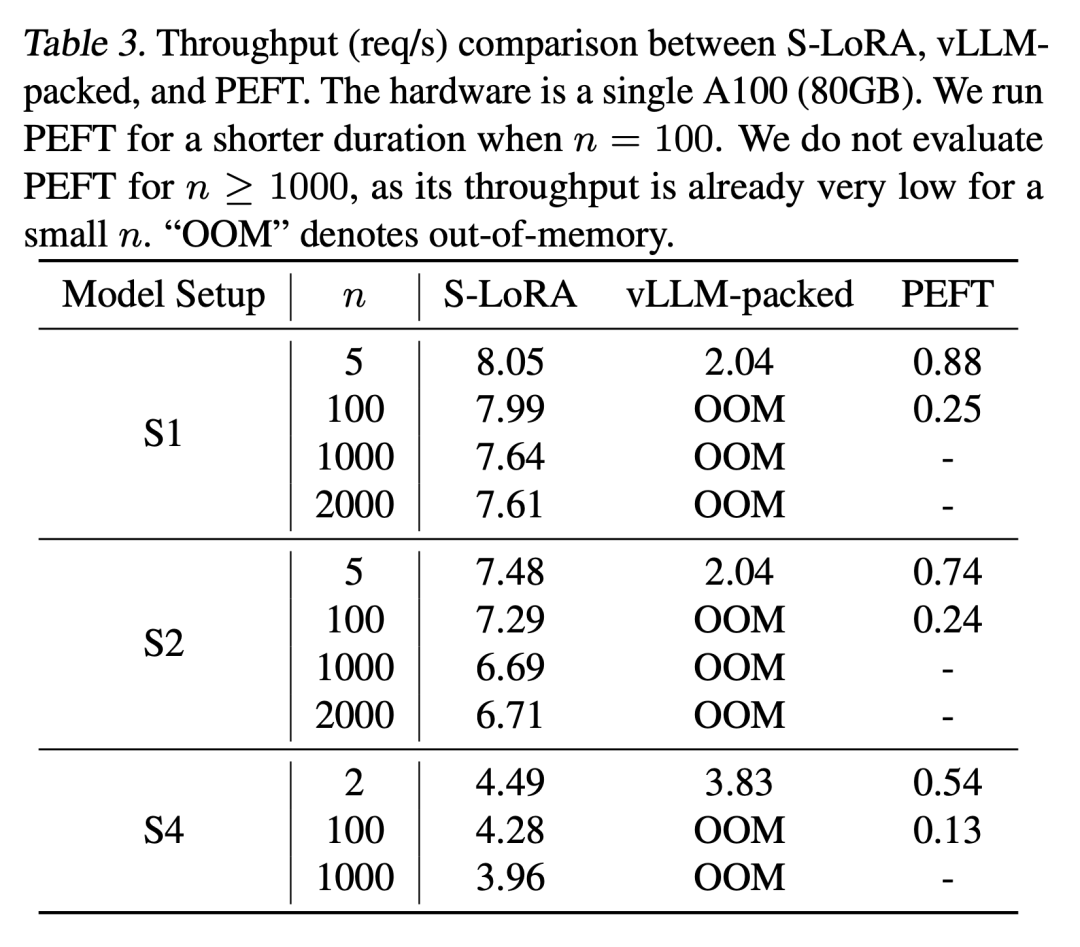
结果表明,S-LoRA 可以在单个 GPU 或多个 GPU 上为数千个 LoRA 适配器提供服务,而且开销很小。与最先进的参数高效微调库 Huggingface PEFT 相比,S-LoRA 的吞吐量最多可提高 30 倍。与使用支持 LoRA 服务的高吞吐量服务系统 vLLM 相比,S-LoRA 可将吞吐量提高 4 倍,并将服务适配器的数量增加几个数量级。
更多研究细节,可参考原论文。
以上就是S-LoRA:一个GPU运行数千大模型成为可能的详细内容,更多请关注其它相关文章!
# 本田
# 新乡seo外包招商
# 平舆网站推广引流方案
# 搜索引擎及seo
# 网站优化设计案例分析
# 泉州网络推广seo优化
# 医疗整形营销推广方案
# 闪信营销怎么推广
# 兰州网站seo优化公司
# 山西推广营销怎么样
# 瓦房店网站首页推广
# 加载
# 数据
# 所需
# 这一
# 并将
# 提出了
# 批处理
# 分页
# 多个
# 数千
# llama
# 训练
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
机器人加速!稀土永磁也被带火,持续性如何?
人工智能:解决劳动力短缺的关键策略
华为AI大模型将融入HarmonyOS 4
绿联发布笑脸屏幕显示充电状态的30W/65W Q湃机器人充电器
人工智能行业急缺人 AI人才年薪能达近42万元
击败LLaMA?史上超强「猎鹰」排行存疑,符尧7行代码亲测,LeCun转赞
人工智能如何与智能家居集成
AI工具助力公司实施每周4.5天工作制,带来巨大效益
美的推出 AI 双视精准避障的自动集尘扫拖机器人 V12,售价仅为2999元
消息称 ChatGPT 未来有望增加更多功能:上传文件分析信息,还能记住用户画像
微软推出人工智能模型 CoDi,可互动和生成多模态内容
亲身体验鸿蒙4:AI大模型带来的便利,告别单纯的旁观者状态
AI无法对传统文化符号进行解构和创新
7/8上海 | 2025世界人工智能大会分论坛:科技与人文-共筑无障碍智能社会
这效果能打几分?AI真人化《名侦探柯南》
人工智能大胆预测:银河系至少有2万个地球,36种外星文明
导演郭帆:人工智能应用可能会影响《流浪地球 3》的创作开发
OpenAI高管:AI能创造新的就业机会 但也会淘汰一些
2025 世界人工智能大会闭幕,32 个重大产业签约总额达 288 亿元
令人惊叹!AI模型能够以iPhone照片为基础创作诗歌
优化系统韧性:故障恢复与监控在RabbitMQ中的应用
看懂AI,找到增长新势能 | 笔记侠AI峰会等你来
V社悄悄封禁使用AI生成美术素材的游戏
英伟达的AI领域垄断地位:一直无法撼动吗?
亚马逊确认今年不举办re:MARS人工智能大会
微软新出热乎论文:Transformer扩展到10亿token
吴恩达、Hinton最新对话!AI不是随机鹦鹉,共识胜过一切,LeCun双手赞成
一图速览 | 十大脑机接口关键技术发布
Bing 聊天机器人现支持在桌面端用语音提问
智能公司为何纷纷投身机器人领域?
万兴播爆桌面端上线,支持AI数字人搜索、视频编辑等功能
泗洪:畅通城市“血管” ,管下机器人来帮忙
朝鲜出现国产大型察打一体无人机,实力世界第二,太意外了
管提需求,大模型解决问题:图表处理神器SheetCopilot上线
首家承认ChatGPT影响其收入的公司Chegg选择拥抱AI ,裁减4%员工
人工智能改变网络安全和用户体验的三种方式
如何成功实施人工智能?
AI行业盛会大咖云集!Sam Altam、“AI教父”......一文看懂最新观点
Meta发布音频AI模型,仅需2秒片段模拟真人语音
全媒封面丨⑤商汤科技:原创AI算法“发电厂”
人工智能赋能无人驾驶:商业化进程再提速
pixivFANBOX 更新运营规则,禁止通过外链绕开 AI 生成禁令
智能机器人与话剧的完美结合:宇树四足机器人B1助力《骆驼祥子》重现经典
携程发布旅游行业垂直大模型 梁建章:AI策略是做可靠的内容 放心的推荐
谷歌在人工智能领域没有“护城河”?
利用AI技术更好地发展农村电商
AI技术改变*,新骗局来袭,*成功率接近100%
苹果AI战略与微软谷歌大相径庭,到底是领先还是落后?
先进技术在防止全球数据丢失方面的作用
三个全球首创,青岛西海岸新区“海元宇宙”亮相世界人工智能大会
2023-11-15

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
