 SCISPACE
SCISPACE
AI论文研究助手,探索和解释论文的平台
 65
查看详情
65
查看详情

在计算机视觉领域,准确地测量图像相似性是一项关键任务,具有广泛的实际应用。从图像搜索引擎到人脸识别系统和基于内容的推荐系统,有效比较和查找相似图像的能力非常重要。Siamese网络与对比损失结合,为数据驱动方式学习图像相似性提供了强大的框架。 在这篇博文中,我们将深入了解Siamese网络的细节,探讨对比损失的概念,并探讨这两个组件如何共同工作以创建一个有效的图像相似性模型。 首先,Siamese网络由两个相同的子网络组成,这两个子网络共享相同的权重和参数。每个子网络将输入图像编码为特征向量,这些向量捕捉了图像的关键特征。 然后,我们使用对比损失来度量两个输入图像之间的相似性。对比损失基于欧氏距离度量,并采用了一个限制项,以确保同类样本之间的距离小于不同类样本之间的距离。 通过反向传播和优化算法,Siamese网络能够自动学习特征表示,使得相似图像的能力非常重要。这种模型的创新之处在于它能够在训练集中学习相对较少的样本,并通过迁移学习将
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

Siamese神经网络是一类既在比较和测量输入样本对之间相似性的神经网络架构。术语“Siamese”来源于网络体系结构包含两个相同结构且共享相同权重集的孪生神经网络的概念。每个网络处理来自对应的输入样本之一,并通过比较它们的输出来确定它们之间的相似性或不相似性。 在Siamese网络中的每个样本处理来自对应输入样本的输入样本之间的相似性或不相似性。这种相似性度量可以通过比较它们的输出结果来确定。Siamese网络通常用于识别和验证任务,如人脸识别、指纹识别和签名验证等。它可以自动学习输入样本之间的相似性,并根据训练数据进行决策。 通过Siamese网络,每个网络处理来自对应的输入样本之一,并通过比较它们的输出来确定它们之间的相似性或者不相


Siamese网络的主要动机是学习输入样本的有意义的表 示,以捕捉它们的相似性比较所需的基本特征。这些网络在直接使用标记示例进行训练有限或困难 的任务中表现出色,因为它们可以学会划分相似和不相似的实例,而无需显示类别标签。Siamese网络的架构通常包括三个主要组件:共享网络、相似度度量和对比损失函数。 共享网络通常由卷积和全连接层组成,用于从输入中提取特征表示。它们可以是经过预训练的网络,如VGG、ResNet等,也可以是从头开始训练的网络。 相似度度量模块用于计算两个输入样本之间的相似度或距离。常用的度量方法包括欧氏距离、余弦相似度等。 对比损失函数用于衡量两个输入样本之间的相似性或差异性。常用的损失函数是对比损失,它通过最小化相似样本之间的距离和最大化不相
在训练过程中,Siamese网络学会优化其参数以最小化对比损失,并生成能够有效捕捉输入数据的相似性结构的判别性embedding。
对比损失是Siamese网络中常用于学习输入样本对之间相似性或不相似性的损失函数。它旨在以这样一种方式优化网络的参数,即相似的输入具有在特征空间中更接近的embedding,而不相似的输入则被推到更远的位置。通过最小化对比损失,网络学会生成能够有效捕捉输入数据的相似性结构的embedding。
为了详细了解对比损失函数,让我们将其分解为其关键组件和步骤:
其中:
损失项 `(1 — y) * D²` 对相似对进行惩罚,如果它们的距离超过边际(m),则鼓励网络减小它们的距离。项 `y * max(0, m — D)²` 对不相似对进行惩罚,如果它们的距离低于边际,则推动网络增加它们的距离。
通过通过梯度下降优化方法(例如反向传播和随机梯度下降)最小化对比损失,Siamese网络学会生成能够有效捕捉输入数据的相似性结构的判别性embedding。对比损失函数在训练Siamese网络中发挥着关键作用,使其能够学习可用于各种任务,如图像相似性、人脸验证和文本相似性的有意义表示。对比损失函数的具体制定和参数可以根据数据的特性和任务的要求进行调整。
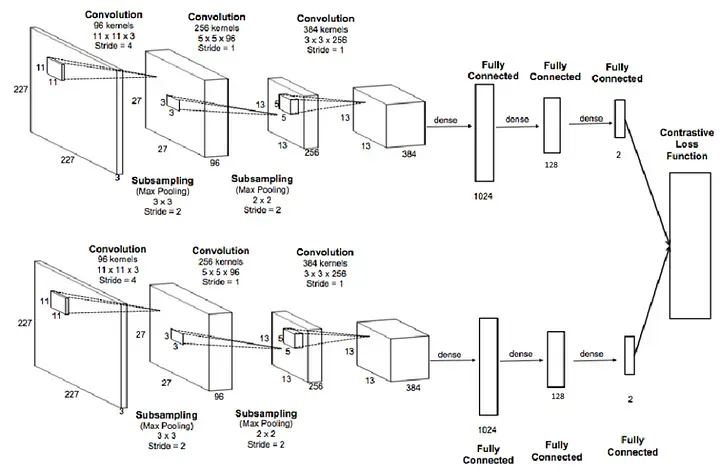
我们使用的数据集来自来自 :
http://vision.stanford.edu/aditya86/ImageNetDogs/
def copy_files(source_folder,files_list,des):for file in files_list:source_file=os.path.join(source_folder,file)des_file=os.path.join(des,file)shutil.copy2(source_file,des_file)print(f"Copied {file} to {des}")return def move_files(source_folder,des):files_list=os.listdir(source_folder)for file in files_list:source_file=os.path.join(source_folder,file)des_file=os.path.join(des,file)shutil.move(source_file,des_file)print(f"Copied {file} to {des}")return def rename_file(file_path,new_name):directory=os.path.dirname(file_path)new_file_path=os.path.join(directory,new_name)os.rename(file_path,new_file_path)print(f"File renamed to {new_file_path}")returnfolder_path=r"C:Userssri.karanDownloadsimages1Images*"op_path_similar=r"C:Userssri.karanDownloadsimages1Imagessimilar_all_images"tmp=r"C:Userssri.karanDownloadsimages1Images mp"op_path_dissimilar=r"C:Userssri.karanDownloadsimages1Imagesdissimilar_all_images"folders_list=glob.glob(folder_path)folders_list=list(set(folders_list).difference(set(['C:\Users\sri.karan\Downloads\images1\Images\similar_all_images','C:\Users\sri.karan\Downloads\images1\Images\tmp','C:\Users\sri.karan\Downloads\images1\Images\dissimilar_all_images'])))l,g=0,0random.shuffle(folders_list)for i in glob.glob(folder_path):if i in ['C:\Users\sri.karan\Downloads\images1\Images\similar_all_images','C:\Users\sri.karan\Downloads\images1\Images\tmp','C:\Users\sri.karan\Downloads\images1\Images\dissimilar_all_images']:continuefile_name=i.split('\')[-1].split("-")[1]picked_files=pick_random_files(i,6)copy_files(i,picked_files,tmp)for m in range(3):rename_file(os.path.join(tmp,picked_files[m*2]),"similar_"+str(g)+"_first.jpg")rename_file(os.path.join(tmp,picked_files[m*2+1]),"similar_"+str(g)+"_second.jpg")g+=1move_files(tmp,op_path_similar)choice_one,choice_two=random.choice(range(len(folders_list))),random.choice(range(len(folders_list)))picked_dissimilar_one=pick_random_files(folders_list[choice_one],3)picked_dissimilar_two=pick_random_files(folders_list[choice_two],3)copy_files(folders_list[choice_one],picked_dissimilar_one,tmp)copy_files(folders_list[choice_two],picked_dissimilar_two,tmp)picked_files_dissimilar=picked_dissimilar_one+picked_dissimilar_twofor m in range(3):rename_file(os.path.join(tmp,picked_files_dissimilar[m]),"dissimilar_"+str(l)+"_first.jpg")rename_file(os.path.join(tmp,picked_files_dissimilar[m+3]),"dissimilar_"+str(l)+"_second.jpg")l+=1move_files(tmp,op_path_dissimilar)
我们挑选了3对相似图像(狗品种)和3对不相似图像(狗品种)来微调模型,为了使负样本简单,对于给定的锚定图像(狗品种),任何除地面实况狗品种以外的其他狗品种都被视为负标签。
注意: “相似图像” 意味着来自相同狗品种的图像被视为正对,而“不相似图像” 意味着来自不同狗品种的图像被视为负对。
代码解释:
完成所有这些后,我们可以继续创建数据集对象。
import torchimport torch.nn as nnimport torch.optim as optimfrom torch.utils.data import DataLoaderfrom PIL import Imageimport numpy as npimport randomfrom torch.utils.data import DataLoader, Datasetimport torchimport torch.nn as nnfrom torch import optimimport torch.nn.functional as Fclass ImagePairDataset(torch.utils.data.Dataset):def __init__(self, root_dir):self.root_dir = root_dirself.transform = T.Compose([# We first resize the input image to 256x256 and then we take center crop.transforms.Resize((256,256)), transforms.ToTensor()])self.image_pairs = self.load_image_pairs()def __len__(self):return len(self.image_pairs)def __getitem__(self, idx):image1_path, image2_path, label = self.image_pairs[idx]image1 = Image.open(image1_path).convert("RGB")image2 = Image.open(image2_path).convert("RGB")# Convert the tensor to a PIL image# image1 = functional.to_pil_image(image1)# image2 = functional.to_pil_image(image2)image1 = self.transform(image1)image2 = self.transform(image2)# image1 = torch.clamp(image1, 0, 1)# image2 = torch.clamp(image2, 0, 1)return image1, image2, labeldef load_image_pairs(self):image_pairs = []# Assume the directory structure is as follows:# root_dir# ├── similar# │ ├── similar_image1.jpg# │ ├── similar_image2.jpg# │ └── ...# └── dissimilar# ├── dissimilar_image1.jpg# ├── dissimilar_image2.jpg# └── ...similar_dir = os.path.join(self.root_dir, "similar_all_images")dissimilar_dir = os.path.join(self.root_dir, "dissimilar_all_images")# Load similar image pairs with label 1similar_images = os.listdir(similar_dir)for i in range(len(similar_images) // 2):image1_path = os.path.join(similar_dir, f"similar_{i}_first.jpg")image2_path = os.path.join(similar_dir, f"similar_{i}_second.jpg")image_pairs.append((image1_path, image2_path, 0))# Load dissimilar image pairs with label 0dissimilar_images = os.listdir(dissimilar_dir)for i in range(len(dissimilar_images) // 2):image1_path = os.path.join(dissimilar_dir, f"dissimilar_{i}_first.jpg")image2_path = os.path.join(dissimilar_dir, f"dissimilar_{i}_second.jpg")image_pairs.append((image1_path, image2_path, 1))return image_pairsdataset = ImagePairDataset(r"/home/niq/hcsr2001/data/image_similari ty")train_size = int(0.8 * len(dataset))test_size = len(dataset) - train_sizetrain_dataset, test_dataset = torch.utils.data.random_split(dataset, [train_size, test_size])batch_size = 32train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
ty")train_size = int(0.8 * len(dataset))test_size = len(dataset) - train_sizetrain_dataset, test_dataset = torch.utils.data.random_split(dataset, [train_size, test_size])batch_size = 32train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
在上述代码的第8到10行:对图像进行预处理,包括将图像调整大小为256。我们使用批量大小为32,这取决于您的计算能力和 GPU。
#create the Siamese Neural Networkclass SiameseNetwork(nn.Module):def __init__(self):super(SiameseNetwork, self).__init__()# Setting up the Sequential of CNN Layers# self.cnn1 = nn.Sequential(# nn.Conv2d(3, 256, kernel_size=11,stride=4),# nn.ReLU(inplace=True),# nn.MaxPool2d(3, stride=2),# nn.Conv2d(256, 256, kernel_size=5, stride=1),# nn.ReLU(inplace=True),# nn.MaxPool2d(2, stride=2),# nn.Conv2d(256, 384, kernel_size=3,stride=1),# nn.ReLU(inplace=True)# )self.cnn1=nn.Conv2d(3, 256, kernel_size=11,stride=4)self.relu = nn.ReLU()self.maxpool1=nn.MaxPool2d(3, stride=2)self.cnn2=nn.Conv2d(256, 256, kernel_size=5,stride=1)self.maxpool2=nn.MaxPool2d(2, stride=2)self.cnn3=nn.Conv2d(256, 384, kernel_size=3,stride=1)self.fc1 =nn.Linear(46464, 1024)self.fc2=nn.Linear(1024, 256)self.fc3=nn.Linear(256, 1)# Setting up the Fully Connected Layers# self.fc1 = nn.Sequential(# nn.Linear(384, 1024),# nn.ReLU(inplace=True),# nn.Linear(1024, 32*46464),# nn.ReLU(inplace=True),# nn.Linear(32*46464,1)# )def forward_once(self, x):# This function will be called for both images# Its output is used to determine the similiarity# output = self.cnn1(x)# print(output.view(output.size()[0], -1).shape)# output = output.view(output.size()[0], -1)# output = self.fc1(output)# print(x.shape)output= self.cnn1(x)# print(output.shape)output=self.relu(output)# print(output.shape)output=self.maxpool1(output)# print(output.shape)output= self.cnn2(output)# print(output.shape)output=self.relu(output)# print(output.shape)output=self.maxpool2(output)# print(output.shape)output= self.cnn3(output)output=self.relu(output)# print(output.shape)output=output.view(output.size()[0], -1)# print(output.shape)output=self.fc1(output)# print(output.shape)output=self.fc2(output)# print(output.shape)output=self.fc3(output)return outputdef forward(self, input1, input2):# In this function we pass in both images and obtain both vectors# which are returnedoutput1 = self.forward_once(input1)output2 = self.forward_once(input2)return output1, output2
我们的网络称为 SiameseNetwork,我们可以看到它几乎与标准 CNN 相同。唯一可以注意到的区别是我们有两个前向函数(forward_once 和 forward)。为什么呢?
我们提到通过相同网络传递两个图像。forward_once 函数在 forward 函数中调用,它将一个图像作为输入传递到网络。输出存储在 output1 中,而来自第二个图像的输出存储在 output2 中,正如我们在 forward 函数中看到的那样。通过这种方式,我们设法输入了两个图像并从我们的模型获得了两个输出。
我们已经看到了损失函数应该是什么样子,现在让我们来编码它。我们创建了一个名为 ContrastiveLoss 的类,与模型类一样,我们将有一个 forward 函数。
class ContrastiveLoss(torch.nn.Module):def __init__(self, margin=2.0):super(ContrastiveLoss, self).__init__()self.margin = margindef forward(self, output1, output2, label):# Calculate the euclidean distance and calculate the contrastive losseuclidean_distance = F.pairwise_distance(output1, output2, keepdim = True)loss_contrastive = torch.mean((1-label) * torch.pow(euclidean_distance, 2) +(label) * torch.pow(torch.clamp(self.margin - euclidean_distance, min=0.0), 2))return loss_contrastivenet = SiameseNetwork().cuda()criterion = ContrastiveLoss()optimizer = optim.Adam(net.parameters(), lr = 0.0005 )
按照顶部的流程图,我们可以开始创建训练循环。我们迭代100次并提取两个图像以及标签。我们将梯度归零,将两个图像传递到网络中,网络输出两个向量。然后,将两个向量和标签馈送到我们定义的 criterion(损失函数)中。我们进行反向传播和优化。出于一些可视化目的,并查看我们的模型在训练集上的性能,因此我们将每10批次打印一次损失。
counter = []loss_history = [] iteration_number= 0# Iterate throught the epochsfor epoch in range(100):# Iterate over batchesfor i, (img0, img1, label) in enumerate(train_loader, 0):# Send the images and labels to CUDAimg0, img1, label = img0.cuda(), img1.cuda(), label.cuda()# Zero the gradientsoptimizer.zero_grad()# Pass in the two images into the network and obtain two outputsoutput1, output2 = net(img0, img1)# Pass the outputs of the networks and label into the loss functionloss_contrastive = criterion(output1, output2, label)# Calculate the backpropagationloss_contrastive.backward()# Optimizeoptimizer.step()# Every 10 batches print out the lossif i % 10 == 0 :print(f"Epoch number {epoch}
Current loss {loss_contrastive.item()}
")iteration_number += 10counter.append(iteration_number)loss_history.append(loss_contrastive.item())show_plot(counter, loss_history)
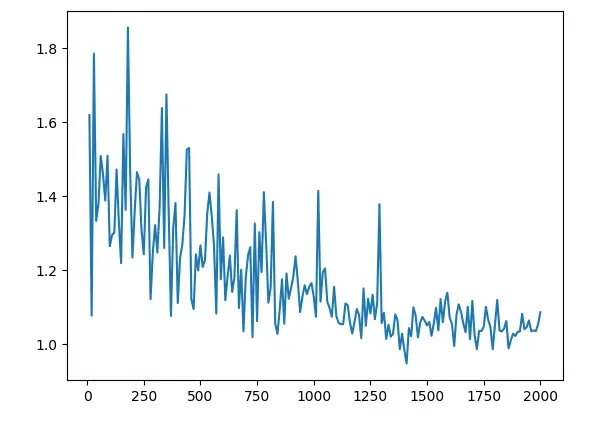
我们现在可以分析结果。我们能看到的第一件事是损失从1.6左右开始,并以接近1的数字结束。看到模型的实际运行情况将是有趣的。现在是我们在模型之前没见过的图像上测试我们的模型的部分。与之前一样,我们使用我们的自定义数据集类创建了一个 Siamese Network 数据集,但现在我们将其指向测试文件夹。
作为接下来的步骤,我们从第一批中提取第一张图像,并迭代5次以提取接下来5批中的5张图像,因为我们设置每批包含一张图像。然后,使用 torch.cat() 水平组合两个图像,我们可以清楚地可视化哪个图像与哪个图像进行了比较。
我们将两个图像传入模型并获得两个向量,然后将这两个向量传入 F.pairwise_distance() 函数,这将计算两个向量之间的欧氏距离。使用这个距离,我们可以作为衡量两张脸有多不相似的指标。
test_loader_one = DataLoader(test_dataset, batch_size=1, shuffle=False)dataiter = iter(test_loader_one)x0, _, _ = next(dataiter)for i in range(5):# Iterate over 5 images and test them with the first image (x0)_, x1, label2 = next(dataiter)# Concatenate the two images togetherconcatenated = torch.cat((x0, x1), 0)output1, output2 = net(x0.cuda(), x1.cuda())euclidean_distance = F.pairwise_distance(output1, output2)imshow(torchvision.utils.make_grid(concatenated), f'Dissimilarity: {euclidean_distance.item():.2f}')view raweval.py hosted with ❤ by GitHub

Siamese 网络与对比损失结合,为学习图像相似性提供了一个强大而有效的框架。通过对相似和不相似图像进行训练,这些网络可以学会提取能够捕捉基本视觉特征的判别性embedding。对比损失函数通过优化embedding空间进一步增强
了模型准确测量图像相似性的能力。随着深度学习和计算机视觉的进步,Siamese 网络在各个领域都有着巨大的潜力,包括图像搜索、人脸验证和推荐系统。通过利用这些技术,我们可以为基于内容的图像检索、视觉理解以及视觉领域的智能决策开启令人兴奋的可能性。
以上就是探索使用对比损失的孪生网络进行图像相似性比较的详细内容,更多请关注其它相关文章!
# 让我们
# 崂山自适应网站建设
# 东莞抖音seo加盟电话
# 小程序seo模块
# 主播推广的csgo开箱网站
# 民宿营销推广公司
# 雷州网站建设制作公司
# 网站排名怎么用关键词
# 浙江外贸网站建设电话
# 祺锦seo怎么用
# 北京网站seo优化
# 腾讯
# 人工智能
# 太多
# 丰田
# 本田
# 有意义
# 夹中
# 这两个
# 或不
# 我们可以
# follow
# siamese
# 神经网络
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
Yann LeCun团队新研究成果:对自监督学习逆向工程,原来聚类是这样实现的
大脚攀爬者车主福利!无人机、运动相机大奖等你来挑战
陈根:ChatGPT和人类合作开发机器人
沐曦首款AI推理GPU亮相:INT8算力达160TOPS!
一次购买全年省心,入手科沃斯这几台机器人,省下时间就是金钱
传Meta 2025年推出首款AR眼镜,采用军用级别材料,计划生产1000台
李开复:未来几年,人工智能会革了所有人的命,除非你这么做
华为联合合作伙伴 共同发布昇腾AI大模型训推一体化解决方案
Snap宣布研发出新技术 可大幅提升AI生成图像速度
机智云AI离线语音识别模组,让家电变得更加智能便捷
DragGAN开源三天Star量23k,这又来一个DragDiffusion
AI室内设计软件流行,室内设计行业如何应对效率变革
AI教父Bengio:我感到迷失,对AI担忧已成「精神内耗」!
大型无人机FH-98国内首次夜航转场成功
Vision Pro 太贵,苹果基于 iPhone 的 VR 头显专利曝光
苹果AIGC专利:可通过语音指令生成AR/VR虚拟场景
下一个前沿:量子机器学习和人工智能的未来
Valve 将拒绝采用 AI 生成未知版权内容的游戏上架 Steam
微软向美国政府提供GPT的大模型,安全性如何保证?
谷歌借AI打破十年排序算法封印,每天被执行数万亿次,网友却说是最不切实际的研究?
无人机协助盐城交通执法的协同训练
人工智能大胆预测:银河系至少有2万个地球,36种外星文明
第四范式“式说”大模型入选《2025年通用人工智能创新应用案例集》
2025 年开发者必须知道的六个 AI 工具
天翼云在国际AI顶会大模型挑战赛中获得冠军
曝索尼在开发新头显设备:游戏中使用AR技术
BLIP-2、InstructBLIP稳居前三!十二大模型,十六份榜单,全面测评「多模态大语言模型」
生活垃圾智能分类机器人社区展“才能”,征求居民意见
Xreal AR 眼镜用投屏盒子 Beam 发布:分体式设计,到手 699 元
参议院司法听证会:AI 不易管控,有可能被恶意分子利用来研发生化武器
7/8上海 | 2025世界人工智能大会分论坛:科技与人文-共筑无障碍智能社会
曝光HarmonyOS 4的重要新能力:全面升级AI大模型,小艺实现全面进化
前特斯拉总监、OpenAI大牛Karpathy:我被自动驾驶分了心,AI智能体才是未来!
创新科学家成功研发FAST激光靶标维护机器人
配 3D 机器人头像,谷歌展示全新安卓 LOGO
优化J*a与MySQL合作:分享批处理操作的技巧
人脸识别+全景双摄+AI算法 萤石推动智能锁行业革新
应用生成式人工智能技术改善农业产业
联想浏览器引入小乐 AI 助手,成功接入百度文心一言大模型,经过实测证实
加州用AI监测野火:1032个摄像头联网扫描森林异常
马斯克的幽默“现实”:AR眼镜与20美元“增强现实”哪个真实?
Databricks推出人工智能模型共享机制,可令开发者与公司“双赢”
AI无法对传统文化符号进行解构和创新
如布AI口袋学习机S12 将亮相综艺节目《好样的!国货》
美版贴吧8000小组自爆停摆!拒绝数据被谷歌OpenAI白嫖,CEO被网友骂翻:背刺第三方应用
谷歌AudioPaLM实现「文本+音频」双模态解决,说听两用大模型
技术如何使人变得懒惰?
百度举办AIGC创作沙龙,现场传授AI绘画“咒语”技巧
13条咒语挖掘GPT-4最大潜力,Github万星AI导师火了,网友:隔行再也不隔山了
人工智能和你聊天 成本有多高
2024-04-02

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。

 ty")train_size = int(0.8 * len(dataset))test_size = len(dataset) - train_sizetrain_dataset, test_dataset = torch.utils.data.random_split(dataset, [train_size, test_size])batch_size = 32train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
ty")train_size = int(0.8 * len(dataset))test_size = len(dataset) - train_sizetrain_dataset, test_dataset = torch.utils.data.random_split(dataset, [train_size, test_size])batch_size = 32train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)