特征选择是构建机器学习模型过程中的关键步骤。为模型和我们想要完成的任务选择好的特征,可以提高性能。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

如果我们处理的是高维数据集,那么选择特征就显得尤为重要。它使模 型能够更快更好地学习。我们的想法是找到最优数量的特征和最有意义的特征。
型能够更快更好地学习。我们的想法是找到最优数量的特征和最有意义的特征。
在本文中,我们将介绍并实现一种新的通过强化学习策略的特征选择。我们先讨论强化学习,尤其是马尔可夫决策过程。它是数据科学领域的一种非常新的方法,尤其适用于特征选择。然后介绍它的实现以及如何安装和使用python库(FSRLearning)。最后再使用一个简单的示例来演示这一过程。
强化学习(RL)技术可以非常有效地解决像游戏解决这样的问题。而强化学习的概念是基于马尔可夫决策过程(MDP)。这里的重点不是要深入定义而是要大致了解它是如何运作的,以及它如何对我们的问题有用。 在强化学习中,智能体通过与环境进行交互来学习。它通过观察当前状态和奖励信号来做出决策,并且会根据选择的行动获得积极或消极的反馈。智能体的目标是通过尝试不同的行动来最大化累积奖励。 强化学习的一个重要概
学习强化背后的思考是,代理从一个未知的环境开始。搜取行动来完成任务。在代理在当前状态和之前选择的行为的作用下,会更倾向于选择一些行为。在每到达一个新状态并搜取行动时,代理都会获得奖励。以下是我们需要为特征选择而定义的主要参数:
状态、行动、奖励、如何选择行动
首先,数据集中存在的特征的子集。例如,如果数据集有三个特征(年龄,性别,身高)加上一个标签,则可能的状态如下:
[] --> Empty set [Age], [Gender], [Height] --> 1-feature set [Age, Gender], [Gender, Height], [Age, Height] --> 2-feature set [Age, Gender, Height] --> All-feature set
在一个状态中,特征的顺序并不重要,我们必须把它看作一个集合,而不是一个特征列表。
关于动作,我们可以从一个子集转到任何一个尚未探索的特性的子集。在特征选择问题中,动作就是选择当前状态下尚未探索的特征,并将其添加到下一个状态中。以下是一些可能的动作:
[Age] -> [Age, Gender] [Gender, Height] -> [Age, Gender, Height]
下面是一个不可能动作的例子:
[Age] -> [Age, Gender, Height] [Age, Gender] -> [Age] [Gender] -> [Gender, Gender]
我们已经定义了状态和动作,还没有定义奖励。奖励是一个实数,用于评估状态的质量。
在特征选择问题中,一个可能的奖励是通过添加新特征而提高相同模型的准确率指标。下面是一个如何计算奖励的例子:
[Age] --> Accuracy = 0.65 [Age, Gender] --> Accuracy = 0.76 Reward(Gender) = 0.76 - 0.65 = 0.11
对于我们首次访问的每个状态,都会使用一组特征来训练一个分类器(模型)。这个值存储在该状态和对应的分类器中,训练分类器的过程是费时费力的,所以我们只训练一次。因为分类器不会考虑特征的顺序,所以我们可以将这个问题视为图而不是树。在这个例子中,选择“性别”作为模型的新特征的操作的奖励是当前状态和下一个状态之间的准确率差值。
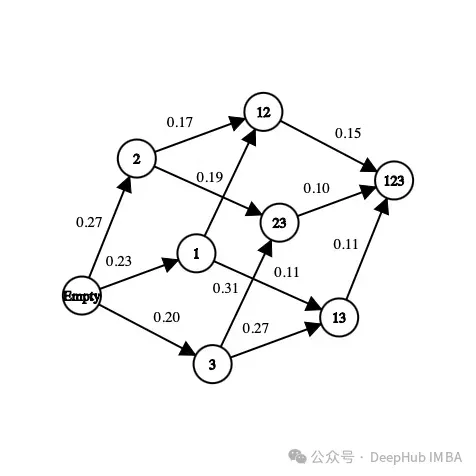
在上图中,每个特征都被映射为一个数字(“年龄”为1,“性别”为2,“身高”为3)。我们如何从当前状态中选择下一个状态或者我们如何探索环境呢?
我们必须找到最优的方法,因为如果我们在一个有10个特征的问题中探索所有可能的特征集,那么状态的数量将是
10! + 2 = 3 628 802
这里的+2是因为考虑一个空状态和一个包含所有可能特征的状态。我们不可能在每个状态下都训练一个模型,这是不可能完成的,而且这只是有10个特征,如果有100个特征那基本上就是无解了。
但是在强化学习方法中,我们不需要在所有的状态下都去训练一个模型,我们要为这个问题确定一些停止条件,比如从当前状态随机选择下一个动作,概率为epsilon(介于0和1之间,通常在0.2左右),否则选择使函数最大化的动作。对于特征选择是每个特征对模型精度带来的奖励的平均值。
这里的贪心算法包含两个步骤:
1、以概率为epsilon,我们在当前状态的可能邻居中随机选择下一个状态
2、选择下一个状态,使添加到当前状态的特征对模型的精度贡献最大。为了减少时间复杂度,可以初始化了一个包含每个特征值的列表。每当选择一个特性时,此列表就会更新。使用以下公式,更新是非常理想的:
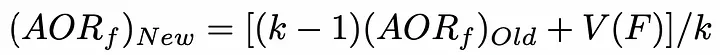
AORf:特征“f”带来的奖励的平均值
K: f被选中的次数
V(F):特征集合F的状态值(为了简单描述,本文不详细介绍)
所以我们就找出哪个特征给模型带来了最高的准确性。这就是为什么我们需要浏览不同的状态,在在许多不同的环境中评估模型特征的最全局准确值。
因为目标是最小化算法访问的状态数,所以我们访问的未访问过的状态越少,需要用不同特征集训练的模型数量就越少。因为从时间和计算能力的角度来看,训练模型以获得精度是最昂贵方法,我们要尽量减少训练的次数。
最后在任何情况下,算法都会停止在最终状态(包含所有特征的集合)而我们希望避免达到这种状态,因为用它来训练模型是最昂贵的。
上面就是我们针对于特征选择的强化学习描述,下面我们将详细介绍在python中的实现。
有一个python库可以让我们直接解决这个问题。但是首先我们先准备数据
我们直接使用UCI机器学习库中的数据:
#Get the pandas DataFrame from the csv file (15 features, 690 rows) australian_data = pd.read_csv('australian_data.csv', header=None) #DataFrame with the features X = australian_data.drop(14, axis=1) #DataFrame with the labels y = australian_data[14]
然后安装我们用到的库
 灵感PPT
灵感PPT
AI灵感PPT - 免费一键PPT生成工具
 308
查看详情
308
查看详情

pip install FSRLearning
直接导入
from FSRLearning import Feature_Selector_RL
Feature_Selector_RL类就可以创建一个特性选择器。我们需要以下的参数
feature_number (integer): DataFrame X中的特性数量
feature_structure (dictionary):用于图实现的字典
eps (float [0;1]):随机选择下一状态的概率,0为贪婪算法,1为随机算法
alpha (float [0;1]):控制更新速率,0表示不更新状态,1表示经常更新状态
gamma (float[0,1]):下一状态观察的调节因子,0为近视行为状态,1为远视行为
nb_iter (int):遍历图的序列数
starting_state (" empty "或" random "):如果" empty ",则算法从空状态开始,如果" random ",则算法从图中的随机状态开始
所有参数都可以机型调节,但对于大多数问题来说,迭代大约100次就可以了,而epsilon值在0.2左右通常就足够了。起始状态对于更有效地浏览图形很有用,但它非常依赖于数据集,两个值都可以测试。
我们可以用下面的代码简单地初始化选择器:
fsrl_obj = Feature_Selector_RL(feature_number=14, nb_iter=100)
与大多数ML库相同,训练算法非常简单:
results = fsrl_obj.fit_predict(X, y)
下面是输出的一个例子:
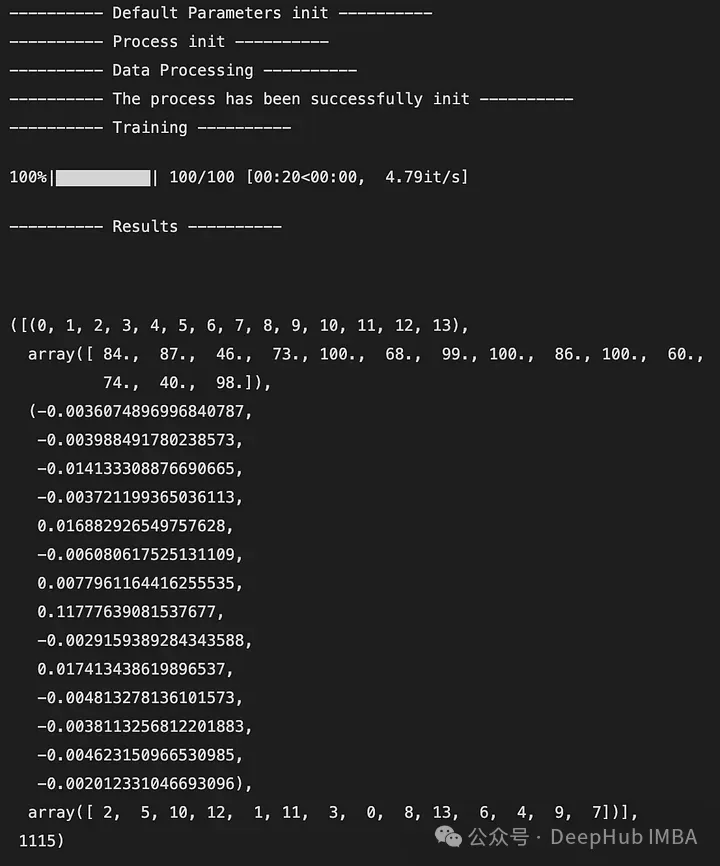
输出是一个5元组,如下所示:
DataFrame X中特性的索引(类似于映射)
特征被观察的次数
所有迭代后特征带来的奖励的平均值
从最不重要到最重要的特征排序(这里2是最不重要的特征,7是最重要的特征)
全局访问的状态数
还可以与Scikit-Learn的RFE选择器进行比较。它将X, y和选择器的结果作为输入。
fsrl_obj.compare_with_benchmark(X, y, results)
输出是在RFE和FSRLearning的全局度量的每一步选择之后的结果。它还输出模型精度的可视化比较,其中x轴表示所选特征的数量,y轴表示精度。两条水平线是每种方法的准确度中值。
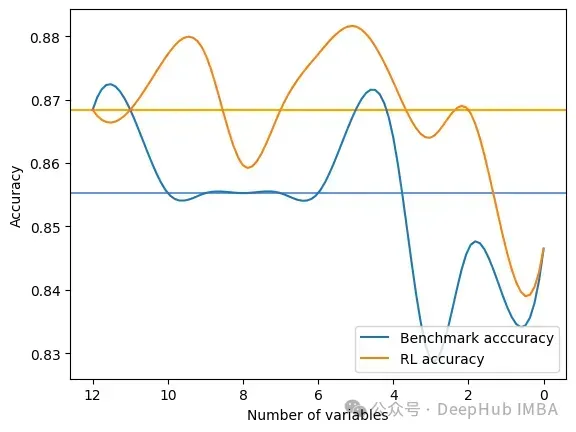
Average benchmark accuracy : 0.854251012145749, rl accuracy : 0.8674089068825909 Median benchmark accuracy : 0.8552631578947368, rl accuracy : 0.868421052631579 Probability to get a set of variable with a better metric than RFE : 1.0 Area between the two curves : 0.17105263157894512
可以看到RL方法总是为模型提供比RFE更好的特征集。
另一个有趣的方法是get_plot_ratio_exploration。它绘制了一个图,比较一个精确迭代序列中已经访问节点和访问节点的数量。
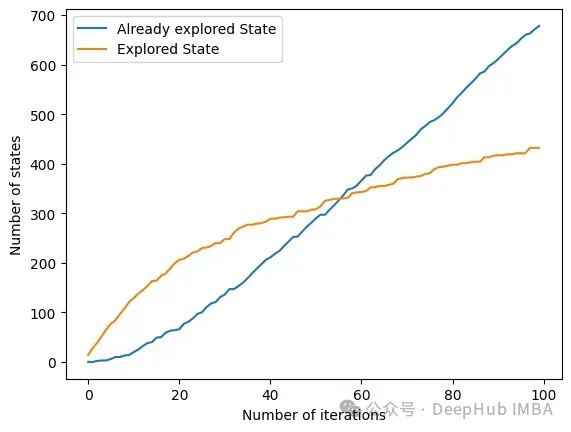
由于设置了停止条件,算法的时间复杂度呈指数级降低。即使特征的数量很大,收敛性也会很快被发现。下面的图表示一定大小的集合被访问的次数。
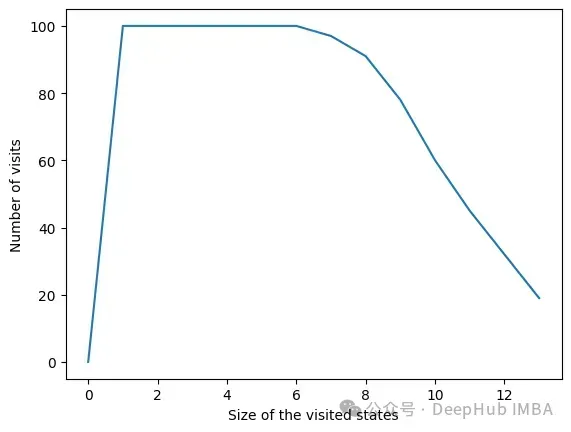
在所有迭代中,算法访问包含6个或更少变量的状态。在6个变量之外,我们可以看到达到的状态数量正在减少。这是一个很好的行为,因为用小的特征集训练模型比用大的特征集训练模型要快。
我们可以看到RL方法对于最大化模型的度量是非常有效的。它总是很快地收敛到一个有趣的特性子集。该方法在使用FSRLearning库的ML项目中非常容易和快速地实现。
以上就是通过强化学习策略进行特征选择的详细内容,更多请关注其它相关文章!
# 它是
# 关键词 seo
# seo的推广原理
# 石岩教育网站推广
# 孝感科技网站优化
# 东莞网站建设制作搭建
# 唐山网络关键词优化排名
# 贵州如何推广网站赚钱呢
# 网络网站建设厂家供应
# 广告网络营销推广师
# 广安网站建设多少钱
# 我们可以
# 机器学习
# 这个问题
# 最重要
# 马尔
# 迭代
# 可以看到
# 不可能
# 选择器
# 是一个
# python
# 强化学习
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
沐曦首款AI推理GPU亮相:INT8算力达160TOPS!
当一切设备都受到人工智能的控制
史玉柱谈AI:国内最缺是计算数学人才,曾给浙大数学系捐五千万
【澎湃原动力】人工智能产业协同创新中心:全产业链资源在这里汇聚
多家欧洲企业签署公开信,批评欧盟 AI 法案草案限制产业发展
Meta 开源 AI 语言模型 MusicGen,可将文本和旋律转化为完整乐曲
移远通信率先完成多场5G NTN技术外场验证,为卫星物联网应用落地提速
陈根:AI冥想教练为用户提供个性化指导
美图设计室2.0使用教程
人工智能时代 数字文明对话向“尼”走来
乐天派AI桌面机器人提供的正能量情绪价值直接拉满,妥妥的治愈系
酒店业将如何受益于人工智能的改变?
GPT-4是如何工作的?哈佛教授亲自讲授
通用医疗人工智能如何革新医疗行业?
AI大模型产品集体奔赴高考考场,教育赛道的讯飞星火能赢吗?
热点资讯:家乐福推出聊天机器人;米哈游2025年营收273.4亿元…
OpenAI 向所有付费 API 用户开放 GPT-4
SnapFusion技术大幅提升AI图像生成速度
13万个注释神经元,5300万个突触,普林斯顿大学等发布首个完整「成年果蝇」大脑连接组
国网辉南供电:无人机空中巡检 全力护航端午佳节
AI数字人业务频频获点赞,谦寻积极引领示范作用
2025年贵州省青少年机器人竞赛在安举行
斑马推出全新升级版思维机:以人工智能为核心的交互式学习体验
游族AI创新院揭牌成立 推进AI赋能游戏业务
马斯克的幽默“现实”:AR眼镜与20美元“增强现实”哪个真实?
放弃自动驾驶,也是一种和解
OpenAI 为开发者推出 GPT 聊天机器人 API 大更新,同时降低价格
微软最新推出的NaturalSpeech2语音合成模型:提供更准确的语音重构,避免棒读效果
人工智能和神经网络有什么联系与区别?
人工智能领域,突破难题:国产大模型“无源之水”问题得到解决。
网易云音乐和小冰推出AI歌手音乐创作软件,首发内置12名AI歌手
优化系统韧性:故障恢复与监控在RabbitMQ中的应用
参考封面|人工智能“淘金热”
XREAL Beam 投屏盒子正式发布:支持“可悬停 AR 空间屏”
谷歌将使用公开信息训练 AI 模型,构建更强大的自家产品
谷歌AudioPaLM实现「文本+音频」双模态解决,说听两用大模型
加州用AI监测野火:1032个摄像头联网扫描森林异常
《上古卷轴5》AI高清材质包优化游戏中所有怪物
机器人技能大比拼
《自然》杂志拒绝刊登人工智能生成的图片和视频
MetaGPT开源框架爆红 GitHub,达到1.1万星,模拟软件开发流程
人工智能大胆预测:银河系至少有2万个地球,36种外星文明
彭博社:苹果Vision Pro曾测试VR手柄追踪方案
万魔推出AI主攻的运动耳机,开启十年研发新纪元
Intel酷睿Ultra发布会官宣!迈向全新的AI时代
美图秀秀发布七款 AI 工具:修图一样修视频、打造电影级上镜脸
7大探索区域打造沉浸式玩乐“元宇宙” 昆明京东MALL未来科技探索官全城招募中
软通动力天枢元宇宙研究院签约落户江宁高新区
全媒封面丨⑤商汤科技:原创AI算法“发电厂”
数字文明尼山对话 | 在东方圣城与AI潮流梦幻联动,看“智慧大脑”让数字山东更美好
2024-05-30

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
