基于单目视觉的3D目标检测在各个领域都至关重要,但现有方法在准确性和计算效率方面存在着重要挑战。本文提出了MonoDETRNext,它追求在精度和处理速度之间取得最佳平衡。我们的方法包括开发高效的混合视觉编码器,增强深度预测机制,并引入创新的查询生成策略,并通过高级深度预测器进行增强。在MonoDETR的基础上,MonoDETRNext引入了两种变体:强调速度的MonoDETRNext-F和注重精度的MonoDETRNext-A。我们认为MonoDETRNext为单目3D物体检测建立了一个新的基准,并为未来的研究开辟了道路。我们进行了详尽的评估,证明了该模型相对于现有解决方案的优越性能。值得注意的是,与MonoDETR相比,MonoDETRNext-A在KITTI测试基准上的AP3D指标提高了4.60%,而MonoDETRNext-F提高了2.21%。此外,MonoDETRNext-F的计算效率略高于其前身。
总结来说,本文的主要贡献如下:
目前的3D目标检测方法通常可以分为两类:基于相机的方法和集成激光雷达和其他传感器的融合方法。 基于相机的方法使用相机采集的图像数据进行目标检测。这些方法通常使用计算机视觉技术,如特征提取和机器学习算法来分析图像中的目
基于相机的方法可以根据输入视点的数量进一步分为单目(单视图)和多视图方法。单色探测器仅使用前向图像作为输入,以有限的2D信息处理复杂的任务。多视图检测器同时对周围场景的图像进行编码,利用视点之间的关系来理解3D空间。另一方面,基于激光雷达和其他传感器集成的融合方法依赖于深度相机和激光雷达等设备的输入。这些设备提供了各种传感器数据类型的融合,包括图像和点云。因此,它们可以提供各种传感器数据类型的融合,包括图像和点云。基于激光雷达和其他传感器融合的方法依赖于深度相机以及激光雷达和光达等设备的输入。这些设备提供了各种传感器数据类型的融合,包括图像和点云。因此,它们可以利用多个传感器器件的优势,从不同的数据源中收集更丰富、更全面的深度信息。
MonoDETR是一种最先进的方法,它利用渲染传输从单个RGB图像预测深度图。与传统的单目深度估计方法相比,通过捕捉输入图像中的细微线索,MonoDETR实现了对不同光明条件的准确度和鲁棒性的提高。
近年来,已经提出了其他几种单目3D重建方法。例如,MonoDTR是一个深度学习模型,使用基于Transformer的架构从单个RGB图像预测深度图。虽然MonoDTR实现了高精度,但它需要额外的激光雷达数据来辅助训练。同时,CaDDN和Monorun不仅在训练过程中需要激光雷达数据,而且在推理过程中也需要数据。Autoshape将CAD数据集成到模型中,以增强受限制的3D展示。MonoDETR需要最小化2D-3D几何误差,并且不需要额外的注释。我们的MonoDETR Next继承了这一特性。
与MonoDLE、PGD和PackNet等所示的方法集成了多尺度特征融合和注意力机制,用于深度图估计和误差分析,从而提高了性能。尽管这些方法具有很高的准确性,但会产生大量的计算成本,并需要大量的内存资源。相反,MonoDETR的特点是其重量轻、效率高。此外,MonoDETRNext-F在速度和效率方面超过了它,而MonoDETRNext-A则表现出明显显著优越的性能。
为了从周围视图中提取特征,DETR3D最初采用了一种 3D目标查询,然后将其投影到多视图图像上以聚合特征。PETR系列进一步介绍了一步生成3D位置特征的生成功能,避免了不精确的投影,并探索了前一帧时间信息的优势。
3D目标查询,然后将其投影到多视图图像上以聚合特征。PETR系列进一步介绍了一步生成3D位置特征的生成功能,避免了不精确的投影,并探索了前一帧时间信息的优势。
BEVFormer和其改进使用可学习的BEV查询生成BEV(鸟瞰图)特征,并引入用于视觉特征聚合的时空BEV转换器。随后的研究还研究了跨模态融合和mask图像建模以提高性能。
DeepFusion和PointPainting等方法代表了激光雷达点云数据与相机图像集成的显著进步,以促进三维空间环境中的精确目标检测。这种融合策略最佳地利用了不同传感器模式固有的协同效应,将空间深度线索与颜色纹理信息融合在一起,从而增强了检测结果的弹性和准确性。
BevFusion将BEVFormer的原理集成到融合范式中,促进了进一步的改进,最终提高了精度,MV2D和Futr3d中描述的示例模型证明了这一点。mmFusion最近的端点通过集成来自多个传感器(包括相机、激光雷达和雷达)的数据,扩展了融合方法的范围,从而在性能上取得了显著进步。
 灵感PPT
灵感PPT
AI灵感PPT - 免费一键PPT生成工具
 308
查看详情
308
查看详情

与此同时,该领域见证了大规模架构的出现,例如OMNI3D和GLEE,它们在3D目标检测任务中表现出了显著的效率。利用丰富的训练数据和以数十亿个或更多参数为特征的复杂模型架构,这些框架已经使用先进的优化算法进行了训练,从而提高了检测性能和精度。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
根据[36]中的研究结果,可变形DETR将其49%的计算工作量分配给编码器,但该组件仅对平均精度(AP)指标贡献11%。
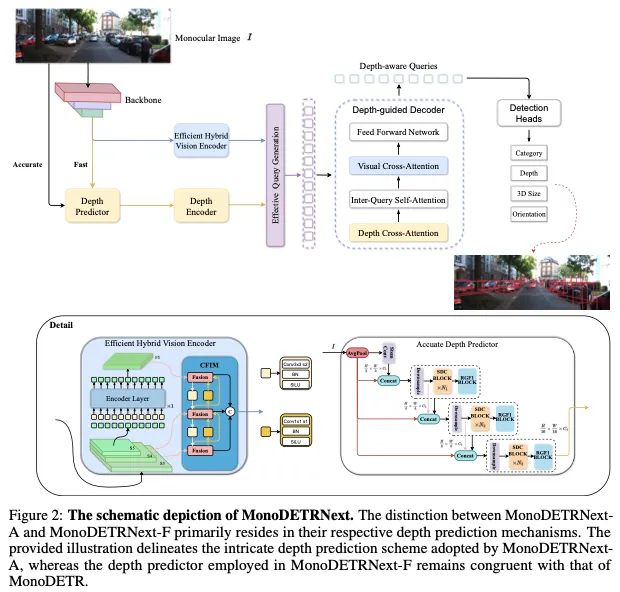
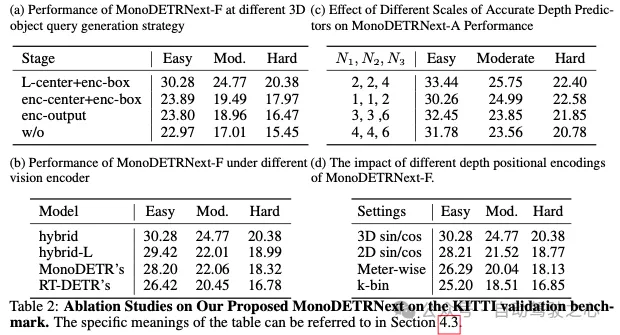
受RT-DETR架构的启发,我们设计了一种创新的高效混合视觉编码器,专门为3D目标检测任务量身定制。该编码器的特点是减少了计算占用,同时保持了特征提取的效率。如图2所示,我们提出的编码器包括两个集成元件:奇异编码器层和基于CNN的跨尺度特征集成模块(CFIM)。如图3所示,CFIM起着融合单元的作用,将形容词特征融合成新颖的表征。该融合过程如以下公式:
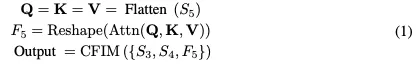
The Sequential Dilated Convolution (SDC)模块,利用膨胀卷积提取多尺度局部特征。与lite-mono类似,我们采用了一种分阶段的方法,通过插入具有不同膨胀率的多个连续膨胀卷积来有效地聚合多尺度上下文。
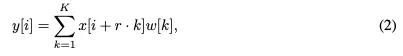
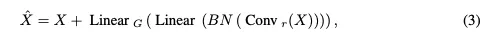
The Regional-Global Feature Interaction (RGFI)的操作如下:给定输入特征图X,它被线性投影到查询、键和值中。交叉协方差注意力用于增强输入X:
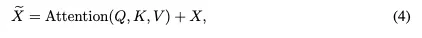
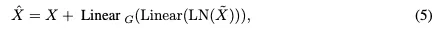
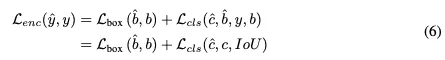
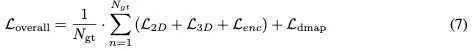
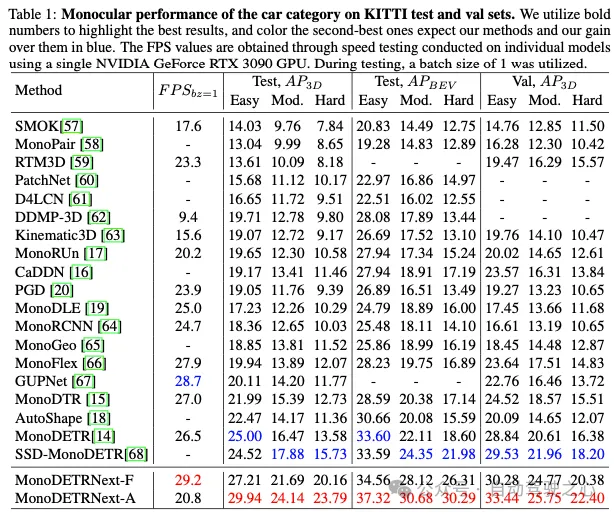
结论:本文介绍了一种新的基于单目视觉的3D目标检测方法。利用2D检测领域的进步,我们提出了高效而精确的MonoDETRNext。在MonoDETR奠定的基础上,我们引入了两种变体:MonoDETRNext-F优先考虑速度,MonoDETRNext-A强调准确性。我们的方法包括开发高效的混合视觉编码器、增强深度预测机制以及改进目标查询生成。通过综合性能评估,我们确定了我们的模型相对于现有方法的优势。通过优化精度和计算效率,MonoDETRNext在单目3D目标检测方面树立了一个新的基准,促进了未来在各种现实世界场景中的研究和应用。
局限性:尽管MonoDETRNext在提高单目3D物体检测的准确性和计算效率方面取得了实质性进展,但仍存在某些局限性。由于单目视觉方法的固有限制,与采用多视图方法或传感器融合技术(如激光雷达与相机的集成)的方法相比,在精度和性能方面仍然存在显著差异。
以上就是MonoDETRNext:下一代准确高效的单目3D检测方法!的详细内容,更多请关注其它相关文章!
# 采用了
# 喷绘公司seo推广方案ppt
# 赣州网站建设推广推荐
# 杏林seo
# 什邡短视频推广营销公司
# 临朐企业网站建设
# 邢台网站建设思路
# 外汇平台网站建设
# 龙岗商城网站建设收益
# 进贤运营seo商家排名
# 兰州网站建设布局招聘
# 3d
# 将其
# 腾讯
# 基础上
# 所示
# 两种
# 提高了
# 多个
# 提出了
# 检测方法
# 目标检测
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
GPT-4成功战胜AI-Guardian审核系统:谷歌研究团队的人工智能抵抗人工智能
2025VR&AR显示技术峰会视频解析: 歌尔光学展示最新一代VR/AR光学模组
干货满满,2025昆山元宇宙国际装备展等你来打卡!
微幼科技晨检机器人:幼儿园健康保障的新伙伴
如何用Transformer BEV克服自动驾驶的极端情况?
热点 | 人工智能黄金时代开启
Databricks 发布大数据分析平台 Spark 用 AI 模型 SDK:一键生成 SQL 及 FySpark 语言图表代码
应对算力挑战,亚马逊云科技发力AI基础设施建设
此「错」并非真的错:从四篇经典论文入手,理解Transformer架构图「错」在何处
传Meta 2025年推出首款AR眼镜,采用军用级别材料,计划生产1000台
比尔盖茨:AI确实存在风险,但可控
CREATOR制造、使用工具,实现LLM「自我进化」
最大助力35公斤 外骨骼机器人或在养老、医疗领域“大展身手”
即将到来:AI婚纱设计软件实际测试,人工智能即将开创婚纱设计新纪元
人工智能如何帮助制造业?
华为4G5G通信物联网收费标准公布,多年研发成果,十年花费近万亿
插画师对AI绘画软件的态度是怎样的?
助力人工智能产业高质量发展 龙岗区算法训练基地正式启用
揭秘AI数字人语录:抖音AI小和尚、老者语录能赚钱吗?
ChatGPT只讲这25个笑话!实验上千次有90%重复,网友:幽默是人类最后的尊严
重磅! 捷通华声灵云AICC荣获第二届光合组织AI解决方案大赛二等奖
海南科技职业大学第25届中国机器人及人工智能大赛海南赛区荣获一等奖等114项
字节团队提出猞猁Lynx模型:多模态LLMs理解认知生成类榜单SoTA
人工智能时代的科幻译者怎么办?“做好翻译工作的高端10%”|文化观察
智能机器人与话剧的完美结合:宇树四足机器人B1助力《骆驼祥子》重现经典
首个算网生态体!中国移动元宇宙产业联盟正式成立
搭载星火认知大模型 讯飞听见智慧屏开启AI办公新体验
田渊栋新作:打开1层Transformer黑盒,注意力机制没那么神秘
美图吴欣鸿:希望更多人用上AI时代的影像生产力工具
昇腾AI大模型训推一体化解决方案将在WAIC发布
李开复:未来几年,人工智能会革了所有人的命,除非你这么做
旷视入选北京市通用人工智能产业创新伙伴计划
通用医疗人工智能如何革新医疗行业?
百度创始人、董事长兼首席执行官李彦宏:AI原生应用比大模型数量更重要
第 66 届格莱美奖规定,AI 作品将无法获得评奖资格
外科医生的智能助手,“机器人手术”得到补充商业医保覆盖
【机智云物联网低功耗转接板】远程环境数据采集探索
AI大模型,将为智慧城市带来哪些新变化?
AI与5G的强强联合:唤醒数字时代的无尽潜能
西班牙小鲜肉*视频在网上疯传,本人发文澄清:是AI换脸的假视频!
英媒:硅谷有些人太鼓吹AI,宣扬“学习无用”
阿里云AI绘画创作大模型通义万相发布 已开启定向邀测
如何对员工进行再培训以充分利用供应链管理中的人工智能创新
“世界上最像人的机器人”接入 Stable Diffusion ,现场完成作画
跟着AI大热的“光模块”到底是什么?
2025 世界人工智能大会闭幕,32 个重大产业签约总额达 288 亿元
小米9号员工李明宣布创业:打造首款安卓桌面机器人
Nature封面:量子计算机离实际应用还有两年
《自然》杂志拒绝刊登人工智能生成的图片和视频
携程发布旅游行业垂直大模型 梁建章:AI策略是做可靠的内容 放心的推荐
2024-05-30

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
