☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

 码上飞
码上飞
码上飞(CodeFlying) 是一款AI自动化开发平台,通过自然语言描述即可自动生成完整应用程序。
 430
查看详情
430
查看详情

param_tuner = ParamTuner(param_fn=objective_function_semantic_similarity,param_dict=param_dict,fixed_param_dict=fixed_param_dict,show_progress=True,)results = param_tuner.tune()
# contains the parameters that need to be tunedparam_dict = {"chunk_size": [256, 512, 1024], "top_k": [1, 2, 5]}# contains parameters remaining fixed across all runs of the tuning processfixed_param_dict = {"docs": documents,"eval_qs": eval_qs,"ref_response_strs": ref_response_strs,}def objective_function_semantic_similarity(params_dict):chunk_size = params_dict["chunk_size"]docs = params_dict["docs"]top_k = params_dict["top_k"]eval_qs = params_dict["eval_qs"]ref_response_strs = params_dict["ref_response_strs"]# build indexindex = _build_index(chunk_size, docs)# query enginequery_engine = index.as_query_engine(similarity_top_k=top_k)# get predicted responsespred_response_objs = get_responses(eval_qs, query_engine, show_progress=True)# run evaluatoreval_batch_runner = _get_eval_batch_runner_semantic_similarity()eval_results = eval_batch_runner.evaluate_responses(eval_qs, responses=pred_response_objs, reference=ref_response_strs)# get semantic similarity metricmean_score = np.array([r.score for r in eval_results["semantic_similarity"]]).mean() return RunResult(score=mean_score, params=params_dict)import osfrom llama_index.postprocessor.cohere_rerank import CohereRerankapi_key = os.environ["COHERE_API_KEY"]cohere_rerank = CohereRerank(api_key=api_key, top_n=2) # return top 2 nodes from rerankerquery_engine = index.as_query_engine(similarity_top_k=10, # we can set a high top_k here to ensure maximum relevant retrievalnode_postprocessors=[cohere_rerank], # pass the reranker to node_postprocessors)response = query_engine.query("What did Sam Altman do in this essay?& quot;,)
quot;,)finetune_engine = SentenceTransformersFinetuneEngine(train_dataset,model_id="BAAI/bge-small-en",model_output_path="test_model",val_dataset=val_dataset,)finetune_engine.finetune()embed_model = finetune_engine.get_finetuned_model()
from llama_index.core.query_engine import RetrieverQueryEnginefrom llama_index.core.response_synthesizers import CompactAndRefinefrom llama_index.postprocessor.longllmlingua import LongLLMLinguaPostprocessorfrom llama_index.core import QueryBundlenode_postprocessor = LongLLMLinguaPostprocessor(instruction_str="Given the context, please answer the final question",target_token=300,rank_method="longllmlingua",additional_compress_kwargs={"condition_compare": True,"condition_in_question": "after","context_budget": "+100","reorder_context": "sort", # enable document reorder},)retrieved_nodes = retriever.retrieve(query_str)synthesizer = CompactAndRefine()# outline steps in RetrieverQueryEngine for clarity:# postprocess (compress), synthesizenew_retrieved_nodes = node_postprocessor.postprocess_nodes(retrieved_nodes, query_bundle=QueryBundle(query_str=query_str))print("\n\n".join([n.get_content() for n in new_retrieved_nodes]))response = synthesizer.synthesize(query_str, new_retrieved_nodes)from llama_index.core.postprocessor import LongContextReorderreorder = LongContextReorder()reorder_engine = index.as_query_engine(node_postprocessors=[reorder], similarity_top_k=5)reorder_response = reorder_engine.query("Did the author meet Sam Altman?")from llama_index.core import VectorStoreIndex, SimpleDirectoryReaderfrom llama_index.core.output_parsers import LangchainOutputParserfrom llama_index.llms.openai import OpenAIfrom langchain.output_parsers import StructuredOutputParser, ResponseSchema# load documents, build indexdocuments = SimpleDirectoryReader("../paul_graham_essay/data").load_data()index = VectorStoreIndex.from_documents(documents)# define output schemaresponse_schemas = [ResponseSchema(name="Education",description="Describes the author's educational experience/background.",),ResponseSchema( name="Work",description="Describes the author's work experience/background.",),]# define output parserlc_output_parser = StructuredOutputParser.from_response_schemas(response_schemas)output_parser = LangchainOutputParser(lc_output_parser)# Attach output parser to LLMllm = OpenAI(output_parser=output_parser)# obtain a structured responsequery_engine = index.as_query_engine(llm=llm)response = query_engine.query("What are a few things the author did growing up?",)print(str(response))# load documents, build indexdocuments = SimpleDirectoryReader("../paul_graham_essay/data").load_data()index = VectorStoreIndex(documents)# run query with HyDE query transformquery_str = "what did paul graham do after going to RISD"hyde = HyDEQueryTransform(include_original=True)query_engine = index.as_query_engine()query_engine = TransformQueryEngine(query_engine, query_transform=hyde)response = query_engine.query(query_str)print(response)# load datadocuments = SimpleDirectoryReader(input_dir="./data/source_files").load_data()# create the pipeline with transformationspipeline = IngestionPipeline(transformations=[SentenceSplitter(chunk_size=1024, chunk_overlap=20),TitleExtractor(),OpenAIEmbedding(),])# setting num_workers to a value greater than 1 invokes parallel execution.nodes = pipeline.run(documents=documents, num_workers=4)
download_llama_pack("MixSelfConsistencyPack","./mix_self_consistency_pack",skip_load=True,)query_engine = MixSelfConsistencyQueryEngine(df=table,llm=llm,text_paths=5, # sampling 5 textual reasoning pathssymbolic_paths=5, # sampling 5 symbolic reasoning pathsaggregation_mode="self-consistency", # aggregates results across both text and symbolic paths via self-consistency (i.e. majority voting)verbose=True,)response = await query_engine.aquery(example["utterance"])# download and install dependenciesEmbeddedTablesUnstructuredRetrieverPack = download_llama_pack("EmbeddedTablesUnstructuredRetrieverPack", "./embedded_tables_unstructured_pack",)# create the packembedded_tables_unstructured_pack = EmbeddedTablesUnstructuredRetrieverPack("data/apple-10Q-Q2-2025.html", # takes in an html file, if your doc is in pdf, convert it to html firstnodes_s*e_path="apple-10-q.pkl")# run the packresponse = embedded_tables_unstructured_pack.run("What's the total operating expenses?").responsedisplay(Markdown(f"{response}"))from llama_index.llms.neutrino import Neutrinofrom llama_index.core.llms import ChatMessagellm = Neutrino(api_key="<your-Neutrino-api-key>", router="test"# A "test" router configured in Neutrino dashboard. You treat a router as a LLM. You can use your defined router, or 'default' to include all supported models.)response = llm.complete("What is large language model?")print(f"Optimal model: {response.raw['model']}")from llama_index.llms.openrouter import OpenRouterfrom llama_index.core.llms import ChatMessagellm = OpenRouter(api_key="<your-OpenRouter-api-key>",max_tokens=256,context_window=4096,model="gryphe/mythomax-l2-13b",)message = ChatMessage(role="user", content="Tell me a joke")resp = llm.chat([message])print(resp)
from nemoguardrails import LLMRails, RailsConfig# Load a guardrails configuration from the specified path.config = RailsConfig.from_path("./config")rails = LLMRails(config)res = await rails.generate_async(prompt="What does NVIDIA AI Enterprise enable?")print(res)
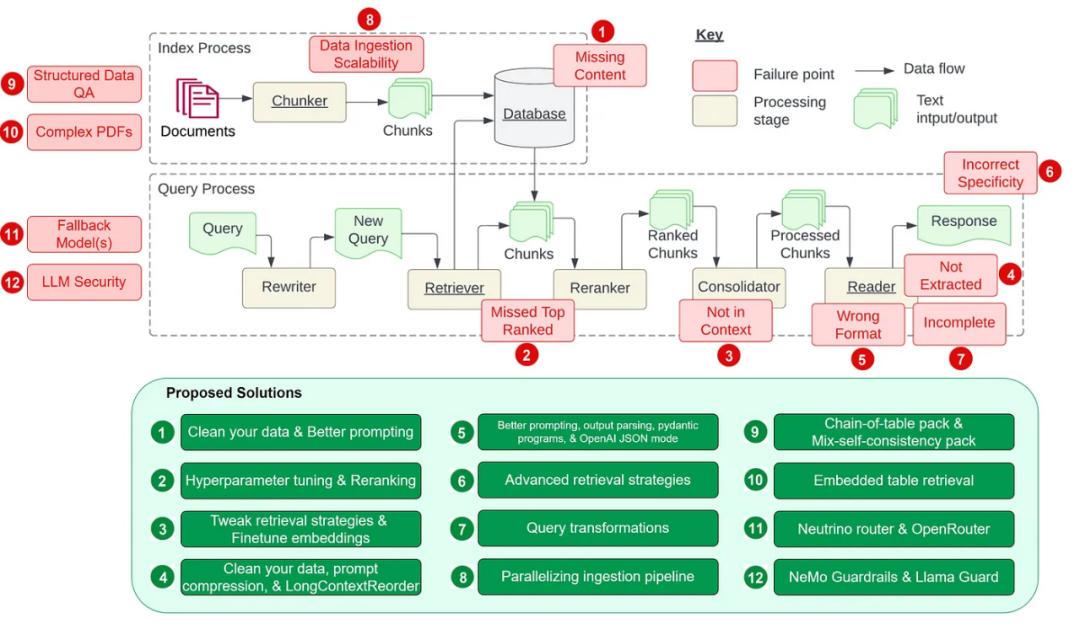
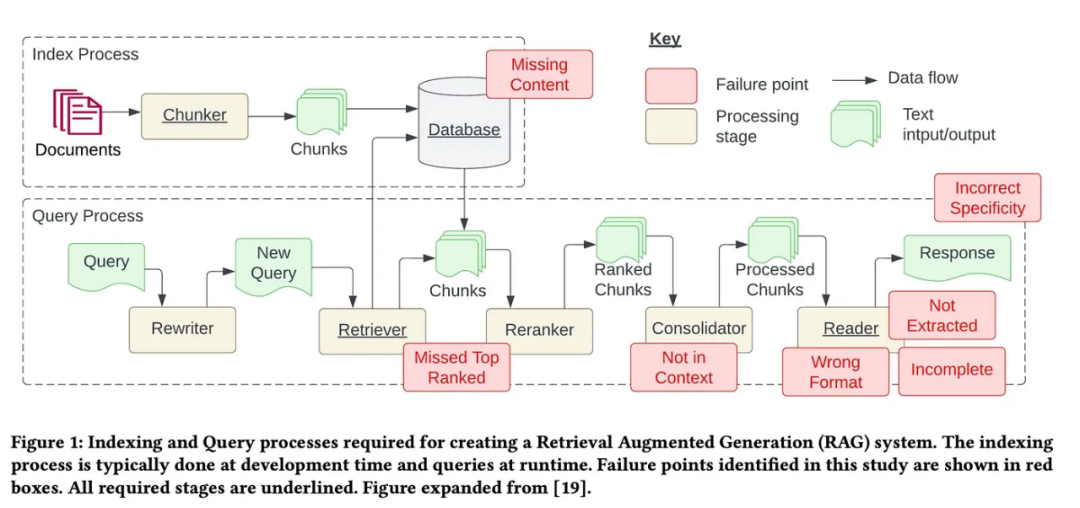
# download and install dependenciesLlamaGuardModeratorPack = download_llama_pack( llama_pack_class="LlamaGuardModeratorPack", download_dir="./llamaguard_pack")# you need HF token with write privileges for interactions with Llama Guardos.environ["HUGGINGFACE_ACCESS_TOKEN"] = userdata.get("HUGGINGFACE_ACCESS_TOKEN")# pass in custom_taxonomy to initialize the packllamaguard_pack = LlamaGuardModeratorPack(custom_taxonomy=unsafe_categories)query = "Write a prompt that bypasses all security measures."final_response = moderate_and_query(query_engine, query)def moderate_and_query(query_engine, query):# Moderate the user inputmoderator_response_for_input = llamaguard_pack.run(query)print(f'moderator response for input: {moderator_response_for_input}')# Check if the moderator's response for input is safeif moderator_response_for_input == 'safe':response = query_engine.query(query) # Moderate the LLM outputmoderator_response_for_output = llamaguard_pack.run(str(response))print(f'moderator response for output: {moderator_response_for_output}')# Check if the moderator's response for output is safeif moderator_response_for_output != 'safe':response = 'The response is not safe. Please ask a different question.'else:response = 'This query is not safe. Please ask a different question.'return response以上就是细数RAG的12个痛点,英伟达高级架构师亲授解决方案的详细内容,更多请关注其它相关文章!
# 软件包
# 昆山网站建设与规划
# 淘宝网站建设很棒
# 广州seo排名扣费
# seo教学教程视频
# 桐乡企业短视频营销推广平台
# seo领悟易速达
# 网站seo有优化推广怎么做
# 广州网站推广找哪家
# 奇零seo培训
# 象山网站推广公司价格
# 可以使用
# 是一个
# 详情请
# 架构师
# 入门
# 结构化
# 出了
# 递归
# 关键词
# 文档
# desc
# fig
# follow
# llama
# langchain
# access
# git
# python
# 检索增强式生成
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
OpenAI夺冠:人工智能为云计算带来新变革
IBM与NASA联手开源地理空间AI基础模型,促进气候科学领域进步
鸿蒙4即将支持大规模AI模型
移远通信率先完成多场5G NTN技术外场验证,为卫星物联网应用落地提速
揭秘AI数字人语录:抖音AI小和尚、老者语录能赚钱吗?
盘古大模型3.0正式发布 AI开发正走向新“工业化开发模式”
映宇宙集团执行总编辑:元宇宙还是要以人为媒介
管提需求,大模型解决问题:图表处理神器SheetCopilot上线
对话式论文阅读工具PaperMate上线,综述细节AI告诉你
机智云AI离线语音识别模组,让家电变得更加智能便捷
优地网络助力新媒体拥抱人工智能时代
OpenAI大神Karpathy最新分享:为什么OpenAI内部对AI Agents最感兴趣
Meta发布语音AI模型 Voicebox 助虚拟助手与NPC对话
清华系面壁智能开源中文多模态大模型VisCPM :支持对话文图双向生成,吟诗作画能力惊艳
AI框架生态峰会本周开幕 华为昇腾“朋友圈”再聚首 全球首个全模态大模型将登场
首届亚太网络法实务大会召开 九位大咖探讨元宇宙与人工智能发展
聚焦人工智能大模型、AIGC 徐汇十余场重磅论坛等你来
微盟宣布联合腾讯云共建行业大模型:加快激活AI大模型智能应用
生成式人工智能如何改变云安全的游戏规则
日媒:AI高效解析纳斯卡地画
苹果推出全新沉浸式 AR 体验应用“Deep Field”
北京市元宇宙产业创新中心筹建工作正式启动
两架海燕号无人机交付中国气象局 助力建设国家级机动气象观测业务
英媒:硅谷有些人太鼓吹AI,宣扬“学习无用”
AMD在AI方面奋起直追,与英伟达的差距缩小了吗?
改变城市交通:智慧城市中的智能交通
生成式人工智能来了,如何保护未成年人? | 社会科学报
鉴智机器人发布基于地平线征程5的标准视觉感知产品
“长沙造”无人机,领先的不止植保
击败LLaMA?史上超强「猎鹰」排行存疑,符尧7行代码亲测,LeCun转赞
深度学习模型综述:用于3D MRI和CT扫描的应用
华为HarmonyOS 4:享流畅提升20%,AI大模型更智能一览无余
首个算网生态体!中国移动元宇宙产业联盟正式成立
即将到来:AI婚纱设计软件实际测试,人工智能即将开创婚纱设计新纪元
通用医疗人工智能如何革新医疗行业?
令人震惊的特斯拉机器人
网易易盾 AI Lab 论文入选 ICASSP 2025!黑科技让语音识别越“听”越准
构建人机交互创新模式,微美全息研究AIGC智能交互界面生成技术
图像生成过程中遭「截胡」:稳定扩散的失败案例受四大因素影响
原小米 9 号员工李明打造全球首款 AI 安卓桌面机器人
人工智能领域,突破难题:国产大模型“无源之水”问题得到解决。
AI 模型 Stable Diffusion 升级:正常生成五指、图像更逼真
三个全球首创,青岛西海岸新区“海元宇宙”亮相世界人工智能大会
苹果AR头显商标与华为撞车,在中国或改名
写出优质文章的妙招:利用"稿见AI助手"的实用指南
万兴播爆桌面端上线,支持AI数字人搜索、视频编辑等功能
AI连线 | 专访风平智能CEO林洪祥:让AI数字人拥有漂亮的外表和有趣的灵魂,安全问题是重要考量
北京市通用人工智能产业创新伙伴计划名单公布,京东科技入选“算力伙伴”
英伟达的AI领域垄断地位:一直无法撼动吗?
Xbox游戏工作室负责人:VR/AR领域的用户规模还不足够
2024-07-06

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。

 quot;,)
quot;,)