本文介绍基于Paddle的世界人工智能创新大赛AIWIN手写字体OCR识别竞赛任务一baseline方案。涵盖竞赛背景与任务,说明数据处理步骤:创建文件夹、上传解压数据,将标注转为PaddleOCR所需格式,生成字典;还涉及模型构建,包括识别算法选择、安装PaddleOCR、下载预训练模型及训练,最后提及模型预测及结果保存,鼓励进一步优化。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

2025世界人工智能创新大赛(AIWIN),由世界人工智能大会组委会主办,AI SPACE承办,是全球范围内初具影响力的人工智能赛事,是2025世界人工智能大会的重要组成部分。
秋季赛将继续围绕“人工智能助力城市数字化转型”的主题,以“开展算法创新、选拔数字人才”为目标,继续秉持“高端化、专业化、国际化、市场化“的原则开展赛事。
今年提供手写字体OCR识别竞赛和心电智能诊断算法竞赛两个赛题。
我们选取【手写字体OCR识别竞赛】任务一进行实验,接下来对赛题背景及任务进行简单介绍。
银行日常业务中涉及到各类凭证的识别录入,例如身份证录入、支票录入、对账单录入等。以往的录入方式主要是以人工录入为主,效率较低,人力成本较高。近几年来,OCR相关技术以其自动执行、人为干预较少等特点正逐步替代传统的人工录入方式。但OCR技术在实际应用中也存在一些问题,在各类凭证字段的识别中,手写体由于其字体差异性大、字数不固定、语义关联性较低、凭证背景干扰等原因,导致OCR识别率准确率不高,需要大量人工校正,对日常的银行录入业务造成了一定的影响。
本次赛题将提供手写体图像切片数据集,数据集从真实业务场景中,经过切片脱敏得到,参赛队伍通过识别技术,获得对应的识别结果。即:
输入:手写体图像切片数据集
输出:对应的识别结果
赛题在赛程中分设为两个独立任务,各自设定不同条件的训练集、测试集和建模环境,概述如下:
任务一(本项目选取):提供开放可下载的训练集及测试集,允许线下建模或线上提供 Notebook 环境及 Terminal 容器环境(脱网)建模,输出识别结果完成赛题。
任务二:提供不可下载的训练集,要求线上通过 Terminal 容器环境(脱网)建模后提交模型,由系统输入测试集(即对选手不可见),输出识别结果完成赛题
大赛使用数据要求如下"参赛人员不得对外以任何形式转载、发布赛题的训练集、验证集的全部或任意部分",因此需要大家自行去官网下载数据集。
注:数据量8000,且均是文字区域,下载速度很快。
In [ ]# 新建文件夹【dataset】!mkdir dataset
将下载的数据集上传到【dataset】文件夹内,操作流程如下图所示:
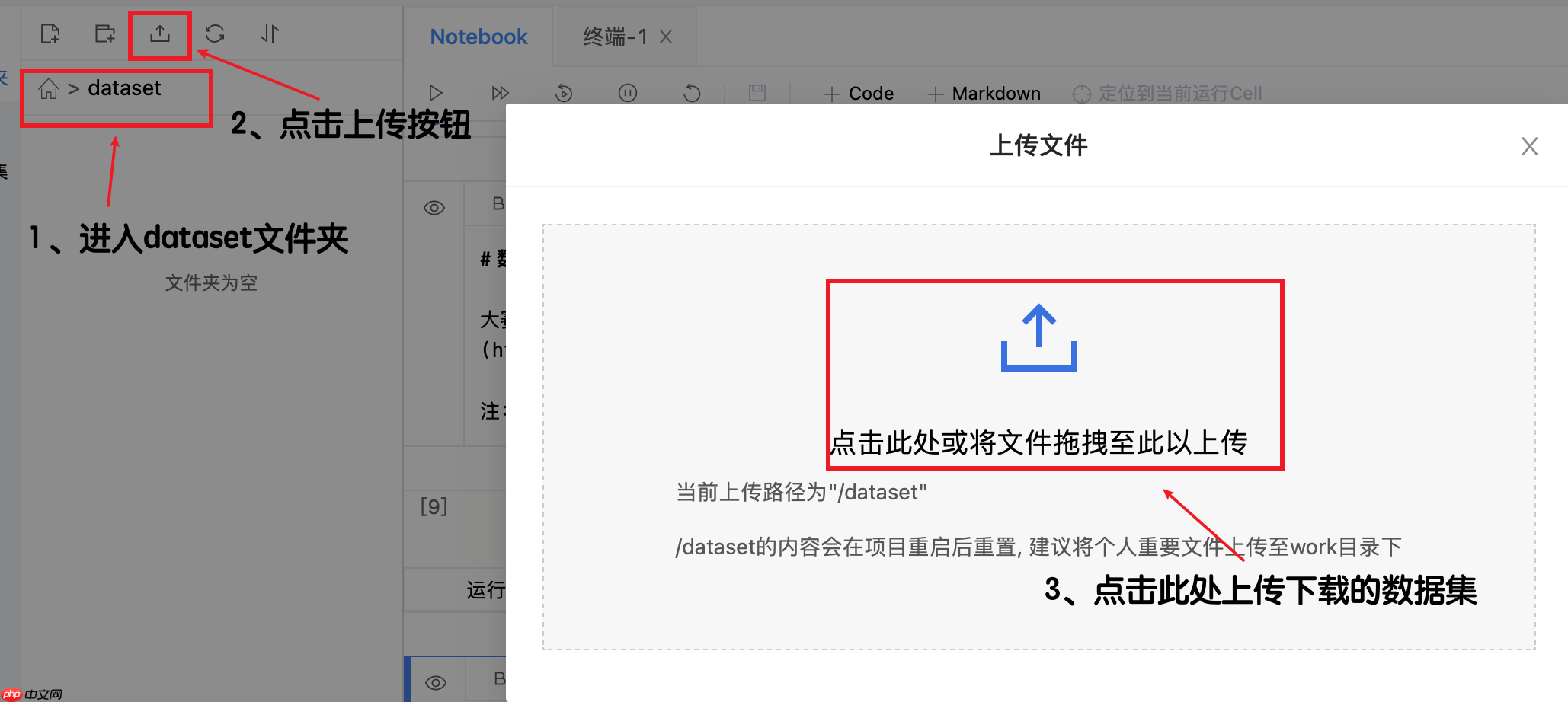
然后解压数据集:
In [ ]!unzip -q dataset/2025A_T1_Task1_Sample_V1106.zip -d ./dataset/ !unzip -q dataset/2025A_T1_Task1_数据集.zip -d ./dataset/
下载的数据标注为json格式且图片在两个文件夹内,我们需要处理为PaddleOCR训练所需要的格式:建议将训练图片放入同一个文件夹,并用一个txt文件(rec_gt_train.txt)记录图片路径和标签,txt文件里的内容如下:
注意: txt文件中默认请将图片路径和图片标签用 \t 分割,如用其他方式分割将造成训练报错。
 简小派
简小派
简小派是一款AI原生求职工具,通过简历优化、岗位匹配、项目生成、模拟面试与智能投递,全链路提升求职成功率,帮助普通人更快拿到更好的 offer。
 123
查看详情
123
查看详情

" 图像文件名 图像标注信息 "train_data/rec/train/word_001.jpg 简单可依赖 train_data/rec/train/word_002.jpg 用科技让复杂的世界更简单 ...
最终训练集应有如下文件结构:
|-train_data
|- rec_gt_train.txt
|- train
|- 8bb1941c760a2c1d017626c361da6c4d.jpg
|- 8bb1941c760a2c1d01762b943a624421.jpg
|- 8bb1941c760a2c1d0176415a9ec807fe.jpg
| ...接下来,我们一起看怎么用代码具体实现吧~
In [ ]import osimport os.path as ospimport jsonimport shutilimport yaml
定义write_file函数,处理训练集中date和amount中的数据:
In [ ]def write_file(file, json_file, s*e_pic):
# 读取json文件
data = yaml.load(open(json_file)) # all_str为了后面统计训练集的字典
all_str = ''
for pic_name, label_info in data.items(): # 修改成OCR需要的格式
line = os.path.join(s*e_pic, pic_name)+'\t'+label_info+'\n'
file.write(line)
all_str+=label_info # 将图片移动到s*e_pic目录下
ori_path = osp.join(osp.dirname(json_file), 'images', pic_name)
s*e_path = osp.join(s*e_pic, pic_name)
shutil.copy(ori_path, s*e_path) return set(all_str)
In [ ]
# 处理数据之后的保存路径!mkdir 'train_data'# 记录图片和标签的txts*e_txt = 'train_data/rec_gt_train.txt'# 所有图片放在一个文件夹内s*e_pic = 'train_data/train/'if not os.path.exists(s*e_pic):
os.mkdir(s*e_pic)# 读取date和amount的json文件date_json = 'dataset/训练集/date/gt.json'amount_json = 'dataset/训练集/amount/gt.json'file = open(s*e_txt, 'w')
date_set = write_file(file, date_json, s*e_pic)
amount_set = write_file(file, amount_json, s*e_pic)
file.close()
处理测试集,将所有图片放在一个文件夹内:
In [ ]!mkdir /home/aistudio/test_data/ !cp -r /home/aistudio/dataset/测试集/amount/images/* /home/aistudio/test_data/ !cp -r /home/aistudio/dataset/测试集/date/images/* /home/aistudio/test_data/
最后需要提供一个字典({rec_gt_label}.txt),使模型在训练时,可以将所有出现的字符映射为字典的索引。
因此字典需要包含所有希望被正确识别的字符,{rec_gt_label}.txt需要写成如下格式,并以 utf-8 编码格式保存:
l dad r nIn [ ]
character_dict_path = 'train_data/rec_gt_label.txt'with open(character_dict_path, 'w', encoding='utf-8') as out_file:
merge_set = date_set|amount_set
num_class = len(merge_set) print('num_class:',num_class) for label in merge_set:
line = label+'\n'
out_file.write(line)num_class: 21
PaddleOCR中提供了如下文本识别算法列表,以及每个算法在英文公开数据集上的模型和指标,主要用于算法简介和算法性能对比。
文本识别算法:
| 模型 | 骨干网络 | Avg Accuracy | 模型存储命名 | 下载链接 |
|---|---|---|---|---|
| Rosetta | Resnet34_vd | 80.24% | rec_r34_vd_none_none_ctc | 下载链接 |
| Rosetta | MobileNetV3 | 78.16% | rec_mv3_none_none_ctc | 下载链接 |
| CRNN | Resnet34_vd | 82.20% | rec_r34_vd_none_bilstm_ctc | 下载链接 |
| CRNN | MobileNetV3 | 79.37% | rec_mv3_none_bilstm_ctc | 下载链接 |
| STAR-Net | Resnet34_vd | 83.93% | rec_r34_vd_tps_bilstm_ctc | 下载链接 |
| STAR-Net | MobileNetV3 | 81.56% | rec_mv3_tps_bilstm_ctc | 下载链接 |
| RARE | Resnet34_vd | 84.90% | rec_r34_vd_tps_bilstm_attn | 下载链接 |
| RARE | MobileNetV3 | 83.32% | rec_mv3_tps_bilstm_attn | 下载链接 |
| SRN | Resnet50_vd_fpn | 88.33% | rec_r50fpn_vd_none_srn | 下载链接 |
本项目中已经帮大家安装好了最新版的PaddleOCR,且修改好配置文件、后处理代码,无需安装~
如仍需安装or安装更新,可以执行以下步骤(目前支持Clone GitHub【推荐】和Gitee两种方式):
注:码云托管代码可能无法实时同步本github项目更新,存在3~5天延时,请优先使用推荐方式。
In [ ]!git clone https://github.com/PaddlePaddle/PaddleOCR# 如果因为网络问题无法pull成功,也可选择使用码云上的托管:# !git clone https://gitee.com/paddlepaddle/PaddleOCRIn [ ]
# 安装依赖,每次启动项目都需要执行%cd PaddleOCR !pip install --upgrade pip !pip install -r requirements.txt
首先下载模型backbone的pretrain model,您可以根据需求使用PaddleClas中的模型更换backbone, 对应的backbone预训练模型可以从PaddleClas repo 主页中找到下载链接。
In [ ]# 下载MobileNetV3的预训练模型!wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/rec_mv3_none_bilstm_ctc_v2.0_train.tar# 解压模型参数%cd pretrain_models !tar -xf rec_mv3_none_bilstm_ctc_v2.0_train.tar && rm -rf rec_mv3_none_bilstm_ctc_v2.0_train.tar %cd ..
这里选择CRNN模型进行训练、MobileNetv3作为backbone,可以在configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml文件里修改训练配置:比如是否使用GPU、模型保存路径、数据集路径、学习率、优化等。
执行命令,启动训练:
In [ ]!python tools/train.py -c configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml
训练好模型之后,即可启动测试,Global.pretrained_model表示预测使用的模型,Global.infer_img表示测试的图片路径或着测试图片文件夹路径:
In [ ]# 预测中文结果!python3 tools/infer_rec.py -c configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml -o Global.pretrained_model=output/rec_chinese_lite_v2.0/latest Global.load_static_weights=false Global.infer_img=/home/aistudio/dataset/测试集/amount/images/8bb1941c760a2c1d017626c361da6c4d.jpg
同时修改infer_rec.py将结果保存为比赛要求的格式,保存结果的路径由configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml中s*e_res_path参数控制,结果answer.json效果如下图:
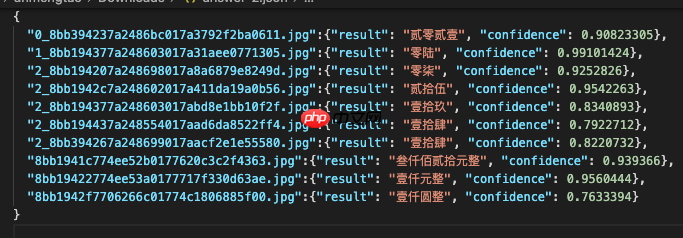
以上就是【Paddle打比赛】手写字体OCR识别竞赛baseline的详细内容,更多请关注其它相关文章!
# 数据处理
# 上海seo公司 外贸
# 济南建设网站与优化
# 好的seo加盟平台
# 网站建设优化推广售价
# 优化网站的方法认可e火17星
# 运城网站推广优势
# CPI数据网站建设工作
# 京东查关键词排名软件
# 河南律师网站推广公司
# 苏州网站如何推广产品呢
# 如下图
# 中分
# 较低
# python
# 线上
# 放在
# 官网
# 一言
# 中文网
# 下载链接
# fig
# udio
# igs
# 网络问题
# ai
# git
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
Meta 推出 Quest 超级分辨率技术,让 VR 画面更清晰
新华全媒+|AI:当心,我可能欺骗了你!
软通动力多项AI创新产品及应用亮相2025世界人工智能大会
小米创始人雷军将揭示小米AI在年度演讲中的最新进展
商业智能决策技术助力降本增效,世界人工智能大会举办商业AI高峰论坛
阿里云推出通义万相AI绘画大模型
以分布式网络串联闲置GPU,这家创企称可将AI模型训练成本降低90%
杭州举办第19届亚运会,主题为「亚运元宇宙」的发布仪式举行
基于信息论的校准技术,CML让多模态机器学习更可靠
500元一张的AI艺术二维码制作,详细教程来了!
世界人工智能大会上,科大讯飞宣布与华为联手
音乐制作元工具AudioCraft发布开源AI工具
国家发改委组织工业机器人产业高质量发展现场会
人形机器人概念集体爆发,能买吗?
普林斯顿Infinigen矩阵开启!AI造物主100%创造大自然,逼真到炸裂
PS AI修图免费平替来了!Stability AI又放大招,核弹级更新一键扩图
参考封面|人工智能“淘金热”
AI绘画,还需要懂数学?
全球首款AI裸眼3D平板 国产的售价破万
美图秀秀发布七款 AI 工具:修图一样修视频、打造电影级上镜脸
AI无法对传统文化符号进行解构和创新
消息称 ChatGPT 未来有望增加更多功能:上传文件分析信息,还能记住用户画像
两小时就能超过人类!DeepMind最新AI速通26款雅达利游戏
Meta 人工智能业务落后竞争对手,研究人员大量离职成重要原因
管提需求,大模型解决问题:图表处理神器SheetCopilot上线
小米9号员工李明宣布创业:打造首款安卓桌面机器人
工业机器人及非标自动化设备集成服务提供商
美图第二届影像节发布七款AI影像创作工具
全国体育人工智能大会举办,专家聚焦体育人工智能领域人才培养
“世界上最像人的机器人”接入 Stable Diffusion ,现场完成作画
原小米 9 号员工李明打造全球首款 AI 安卓桌面机器人
马斯克“揭秘”人工智能真面目
人工智能和你聊天 成本有多高
深圳人工智能企业超1900家
水路两栖艇、消防灭火机器人……这个展览“黑科技”抢眼
2025WRC世界机器人大赛锦标赛(烟台)收官!斯坦星球勇夺VEX赛项冠亚军!
CharacterAI - 也许会成为会话人工智能的未来
微软大牛加入ZOOM,AI人才大战打响
央视报道车载人机交互技术!MWC上海魅族表现亮眼,现场热火朝天
“黑科技”亮相大湾区轨交论坛 智慧交通迈向“强AI”
十个AI算法常用库J*a版
云南首例达芬奇机器人微创心脏手术成功开展
「社交达人」GPT-4!解读表情、揣测心理全都会
AI 助手 Copilot 上线,微软 Win11 Dev 预览版 Build 23493 发布
人工智能在重症监护室的未来
彭博社:苹果Vision Pro曾测试VR手柄追踪方案
出门问问亮相2025世界人工智能大会,展示AI CoPilot解决方案
苹果AR头显商标与华为撞车,在中国或改名
看了天美对AI的布局,我感觉它想得是真明白
家电行业观察:AI加持下,全屋智能将成为智能家电未来?
2025-07-18

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。

 et/测试集/amount/images/8bb1941c760a2c1d017626c361da6c4d.jpg
et/测试集/amount/images/8bb1941c760a2c1d017626c361da6c4d.jpg