本文介绍经典论文《Holistically-Nested Edge Detection》中的HED模型,这是多尺度端到端边缘检测模型。给出其Paddle实现,包括HEDBlock构建、HED_Caffe模型(对齐Caffe预训练模型)及精简HED模型,还涉及预训练模型加载、预处理、后处理操作及推理过程。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

除了传统的边缘检测算法,当然也有基于深度学习的边缘检测模型
这次就介绍一篇比较经典的论文 Holistically-Nested Edge Detection
其中的 Holistically-Nested 表示此模型是一个多尺度的端到端边缘检测模型
论文:Holistically-Nested Edge Detection
官方代码(Caffe):s9xie/hed
非官方实现(Pytorch): xwjabc/hed
论文中的效果对比图:
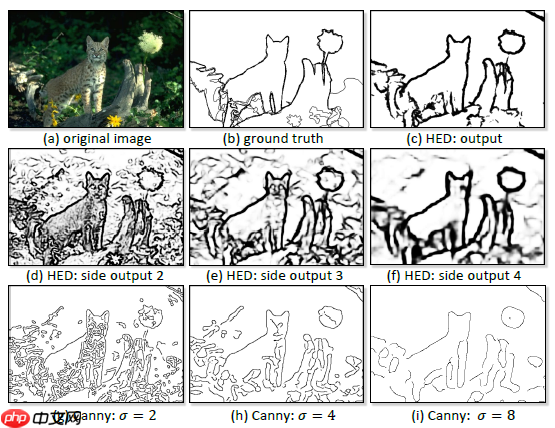
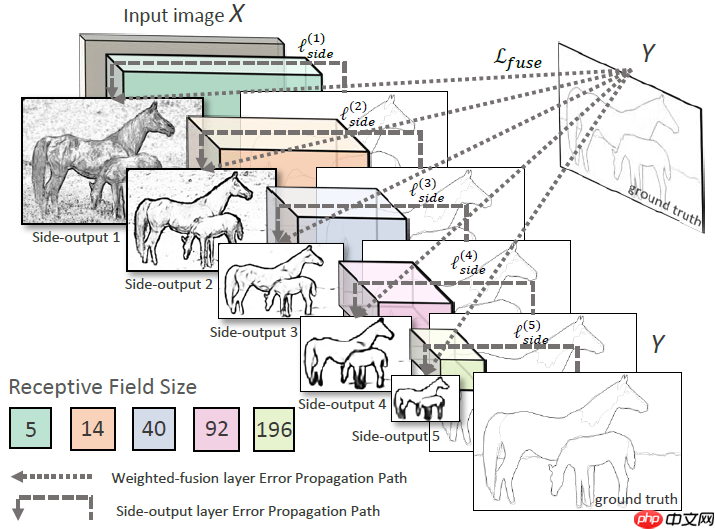
HED 模型包含五个层级的特征提取架构,每个层级中:
使用 VGG Block 提取层级特征图
使用层级特征图计算层级输出
层级输出上采样
最后融合五个层级输出作为模型的最终输出:
通道维度拼接五个层级的输出
1x1 卷积对层级输出进行融合
模型总体架构图如下:
import cv2import numpy as npfrom PIL import Imageimport paddleimport paddle.nn as nn
由一个 VGG Block 和一个 score Conv2D 层组成
使用 VGG Block 提取图像特征信息
使用一个额外的 Conv2D 计算边缘得分
class HEDBlock(nn.Layer):
def __init__(self, in_channels, out_channels, paddings, num_convs, with_pool=True):
super().__init__() # VGG Block
if with_pool:
pool = nn.MaxPool2D(kernel_size=2, stride=2)
self.add_sublayer('pool', pool)
conv1 = nn.Conv2D(in_channels=in_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=paddings[0])
relu = nn.ReLU()
self.add_sublayer('conv1', conv1)
self.add_sublayer('relu1', relu) for _ in range(num_convs-1):
conv = nn.Conv2D(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=paddings[_+1])
self.add_sublayer(f'conv{_+2}', conv)
self.add_sublayer(f'relu{_+2}', relu)
self.layer_names = [name for name in self._sub_layers.keys()] # Socre Layer
self.score = nn.Conv2D(in_channels=out_channels, out_channels=1, kernel_size=1, stride=1, padding=0) def forward(self, input):
for name in self.layer_names: input = self._sub_layers[name](input) return input, self.score(input)
本模型基于官方开源的 Caffe 预训练模型实现,预测结果非常接近官方实现。
 简小派
简小派
简小派是一款AI原生求职工具,通过简历优化、岗位匹配、项目生成、模拟面试与智能投递,全链路提升求职成功率,帮助普通人更快拿到更好的 offer。
 123
查看详情
123
查看详情

此代码会稍显冗余,主要是为了对齐官方提供的预训练模型,具体的原因请参考如下说明:
由于 Paddle 的 Bilinea r Upsampling 与 Caffe 的 Bilinear DeConvolution 并不完全等价,所以这里使用 Transpose Convolution with Bilinear 进行替代以对齐模型输出。
r Upsampling 与 Caffe 的 Bilinear DeConvolution 并不完全等价,所以这里使用 Transpose Convolution with Bilinear 进行替代以对齐模型输出。
因为官方开源的 Caffe 预训练模型中第一个 Conv 层的 padding 参数为 35,所以需要在前向计算时进行中心裁剪特征图以恢复其原始形状。
裁切所需要的参数参考自 XWJABC 的复现代码,代码链接
class HED_Caffe(nn.Layer):
def __init__(self,
channels=[3, 64, 128, 256, 512, 512],
nums_convs=[2, 2, 3, 3, 3],
paddings=[[35, 1], [1, 1], [1, 1, 1], [1, 1, 1], [1, 1, 1]],
crops=[34, 35, 36, 38, 42],
with_pools=[False, True, True, True, True]):
super().__init__() '''
Caffe HED model re-implementation in Paddle.
This model is based on the official Caffe pre-training model.
The inference results of this model are very close to the official implementation in Caffe.
Pytorch and Paddle's Bilinear Upsampling are not completely equivalent to Caffe's DeConvolution with Bilinear, so Transpose Convolution with Bilinear is used instead.
In the official Caffe pre-training model, the padding parameter value of the first convolution layer is equal to 35, so the feature map needs to be cropped.
The crop parameters refer to the code implementation by XWJABC. The code link: https://github.com/xwjabc/hed/blob/master/networks.py#L55.
'''
assert (len(channels) - 1) == len(nums_convs), '(len(channels) -1) != len(nums_convs).'
self.crops = crops # HED Blocks
for index, num_convs in enumerate(nums_convs):
block = HEDBlock(in_channels=channels[index], out_channels=channels[index+1], paddings=paddings[index], num_convs=num_convs, with_pool=with_pools[index])
self.add_sublayer(f'block{index+1}', block)
self.layer_names = [name for name in self._sub_layers.keys()] # Upsamples
for index in range(2, len(nums_convs)+1):
upsample = nn.Conv2DTranspose(in_channels=1, out_channels=1, kernel_size=2**index, stride=2**(index-1), bias_attr=False)
upsample.weight.set_value(self.bilinear_kernel(1, 1, 2**index))
upsample.weight.stop_gradient = True
self.add_sublayer(f'upsample{index}', upsample) # Output Layers
self.out = nn.Conv2D(in_channels=len(nums_convs), out_channels=1, kernel_size=1, stride=1, padding=0)
self.sigmoid = nn.Sigmoid() def forward(self, input):
h, w = input.shape[2:]
scores = [] for index, name in enumerate(self.layer_names): input, score = self._sub_layers[name](input) if index > 0:
score = self._sub_layers[f'upsample{index+1}'](score)
score = score[:, :, self.crops[index]: self.crops[index] + h, self.crops[index]: self.crops[index] + w]
scores.append(score)
output = self.out(paddle.concat(scores, 1)) return self.sigmoid(output) @staticmethod
def bilinear_kernel(in_channels, out_channels, kernel_size):
'''
return a bilinear filter tensor
'''
factor = (kernel_size + 1) // 2
if kernel_size % 2 == 1:
center = factor - 1
else:
center = factor - 0.5
og = np.ogrid[:kernel_size, :kernel_size]
filt = (1 - abs(og[0] - center) / factor) * (1 - abs(og[1] - center) / factor)
weight = np.zeros((in_channels, out_channels, kernel_size, kernel_size), dtype='float32')
weight[range(in_channels), range(out_channels), :, :] = filt return paddle.to_tensor(weight, dtype='float32')
下面就是一个比较精简的 HED 模型实现
与此同时也意味着下面这个模型会与官方实现的模型有所差异,具体差异如下:
3 x 3 卷积采用 padding == 1
采用 Bilinear Upsampling 进行上采样
同样可以加载预训练模型,不过精度可能会略有下降
# class HEDBlock(nn.Layer):# def __init__(self, in_channels, out_channels, num_convs, with_pool=True):# super().__init__()# # VGG Block# if with_pool:# pool = nn.MaxPool2D(kernel_size=2, stride=2)# self.add_sublayer('pool', pool)# conv1 = nn.Conv2D(in_channels=in_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=1)# relu = nn.ReLU()# self.add_sublayer('conv1', conv1)# self.add_sublayer('relu1', relu)# for _ in range(num_convs-1):# conv = nn.Conv2D(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=1)# self.add_sublayer(f'conv{_+2}', conv)# self.add_sublayer(f'relu{_+2}', relu)# self.layer_names = [name for name in self._sub_layers.keys()]# # Socre Layer# self.score = nn.Conv2D(# in_channels=out_channels, out_channels=1, kernel_size=1, stride=1, padding=0)# def forward(self, input):# for name in self.layer_names:# input = self._sub_layers[name](input)# return input, self.score(input)# class HED(nn.Layer):# def __init__(self,# channels=[3, 64, 128, 256, 512, 512],# nums_convs=[2, 2, 3, 3, 3],# with_pools=[False, True, True, True, True]):# super().__init__()# '''# HED model implementation in Paddle.# Fix the padding parameter and use simple Bilinear Upsampling.# '''# assert (len(channels) - 1) == len(nums_convs), '(len(channels) -1) != len(nums_convs).'# # HED Blocks# for index, num_convs in enumerate(nums_convs):# block = HEDBlock(in_channels=channels[index], out_channels=channels[index+1], num_convs=num_convs, with_pool=with_pools[index])# self.add_sublayer(f'block{index+1}', block)# self.layer_names = [name for name in self._sub_layers.keys()]# # Output Layers# self.out = nn.Conv2D(in_channels=len(nums_convs), out_channels=1, kernel_size=1, stride=1, padding=0)# self.sigmoid = nn.Sigmoid()# def forward(self, input):# h, w = input.shape[2:]# scores = []# for index, name in enumerate(self.layer_names):# input, score = self._sub_layers[name](input)# if index > 0:# score = nn.functional.upsample(score, size=[h, w], mode='bilinear')# scores.append(score)# output = self.out(paddle.concat(scores, 1))# return self.sigmoid(output)
def hed_caffe(pretrained=True, **kwargs):
model = HED_Caffe(**kwargs) if pretrained:
pdparams = paddle.load('hed_pretrained_bsds.pdparams')
model.set_dict(pdparams) return model
类型转换
归一化
转置
增加维度
转换为 Paddle Tensor
def preprocess(img):
img = img.astype('float32')
img -= np.asarray([104.00698793, 116.66876762, 122.67891434], dtype='float32')
img = img.transpose(2, 0, 1)
img = img[None, ...] return paddle.to_tensor(img, dtype='float32')
上下阈值限制
删除通道维度
反归一化
类型转换
转换为 Numpy NdArary
def postprocess(outputs):
results = paddle.clip(outputs, 0, 1)
results = paddle.squeeze(results, 1)
results *= 255.0
results = results.cast('uint8') return results.numpy()
model = hed_caffe(pretrained=True)
img = cv2.imread('sample.png')
img_tensor = preprocess(img)
outputs = model(img_tensor)
results = postprocess(outputs)
show_img = np.concatenate([cv2.cvtColor(img, cv2.COLOR_BGR2RGB), cv2.cvtColor(results[0], cv2.COLOR_GRAY2RGB)], 1)
Image.fromarray(show_img)<PIL.Image.Image image mode=RGB size=960x320 at 0x7F3390C85090>代码解释
以上就是边缘检测系列3:【HED】 Holistically-Nested 边缘检测的详细内容,更多请关注其它相关文章!
# ai
# 是一个
# 安装包
# 端到
# 开源
# 一键
# 中文网
# 边缘
# type
# 征信
# git
# 转换为
# 网站seo搜索引擎优化
# 涪陵网站建设电话
# 洛阳营销推广技巧
# 兰州靠谱网站seo优化
# 去地产化营销推广图
# 杨浦营销推广外包公司
# 雅安关键词排名好
# 淮北网站建设价格
# 永春SEO
# 孝义seo优化页面
# 这是
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
优化系统韧性:故障恢复与监控在RabbitMQ中的应用
零数科技CTO兰春嘉:区块链与人工智能的结合点在数据
Dubbo负载均衡策略之 一致性哈希
售价14.99万起!小米汽车部分信息疑遭AI曝光,内部人士回应:网传图片明显经过处理,不可轻信
人工智能自己玩自己
世界人工智能大会(WAIC 2025)点燃魔都,博尔捷数字科技携前沿技术产品亮相
人工智能产业协同创新中心:全产业链资源在这里汇聚
飒智智能机器人核心技术与应用论坛暨一体化控制器发布会成功举办
轻量级的深度学习框架Tinygrad
iPhone两秒出图,目前已知的最快移动端Stable Diffusion模型来了
给小朋友最好的科技礼物:乐天派桌面机器人
爱设计PPT发布第二代AI一键生成PPT产品:智能、个性化、自动化
中国气象局预测:到 2030 年,中国人工智能气象应用将达到国际领先水平
谷歌借AI打破十年排序算法封印,每天被执行数万亿次,网友却说是最不切实际的研究?
世界人工智能大会中西部县域数字就业中心组团亮相
复盘MWC上海:AI大模型时代到来 通信网络将会怎样改变?
生成式AI爆发,亚马逊云科技持续专注创新,助力企业数字化转型
下一个前沿:量子机器学习和人工智能的未来
月薪6万,哪些AI岗位在抢人?
元宇宙技术带你穿梭“大运河”,江苏书展上的数字阅读馆吸睛小读者
人脸识别+全景双摄+AI算法 萤石推动智能锁行业革新
全球首款AI裸眼3D平板 国产的售价破万
如何提高集群协作效率?中外团队合作研发基于均值偏移的机器人队形控制策略
深度学习模型综述:用于3D MRI和CT扫描的应用
IBM CEO克里希纳:人工智能潜在创新无法被监管
智能手机应用中的人工智能的重要性
解决导航“最后50米”难题 高德地图升级AR步行导航找终点功能
图像生成过程中遭「截胡」:稳定扩散的失败案例受四大因素影响
AYANEO AIR 1S 掌机 7 月 9 日发布:R7 7840U + OLED 屏
第四范式“式说”大模型入选《2025年通用人工智能创新应用案例集》
张朝阳与陆川谈AI:ChatGPT是鹦鹉学舌思维,不可能取代人类 | 把脉AI大模型
AI连线 | 专访风平智能CEO林洪祥:让AI数字人拥有漂亮的外表和有趣的灵魂,安全问题是重要考量
ChatGPT 可以设计机器人吗?
OpenAI夺冠:人工智能为云计算带来新变革
实现MySQL数据锁定策略:解决并发冲突的J*a解决方案
IBM将模拟计算用于人工智能,重塑AI计算
人工智能助力精准学习,猿辅导小猿学练机满足学生个性化学习需求
陈根教授:离人形机器人时代还有10年吗?
Moka AI产品后观察:HR SaaS迈进AGI时代
一家 380 亿美元的数据巨头,要掀起企业「AI 化」革命
金山办公宣布与英伟达团队合作,加速WPS AI服务
MiracleVision视觉大模型功能介绍
从医疗康复外骨骼到通用人形机器人,傅利叶智能推动核心技术升级
图灵奖得主Hinton:我已经老了,如何控制比人类更聪明的AI交给你们了
美图影像节演讲实录:191次提及AI,发布7款影像生产力工具
携程发布旅游行业垂直大模型 梁建章:AI策略是做可靠的内容 放心的推荐
重塑未来生活的五项技术趋势
专家解读国家网信办深度合成服务算法备案信息公告:不等于百度、阿里、腾讯等生成式AI产品获批
高通发布长期产品计划,为工业和企业物联网产品提供全新组合方案
宇宙探索下一阶段,机器代替人类,AI会在太空探索中取代人类吗?
2025-07-18

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
