自动驾驶技术近期因其较低的成本而引起了广泛关注,并且对于提取通用表达式以视觉为中心的自动驾驶技术近期因其较低的成本而引起了广泛关注,并且对于提取通用表达式以视觉为中心的自动驾驶技术近期因其较低的成本而引起了广泛关注,而预训练对于提取通用表达式以视觉为中心的重要。 然而,当前的视觉为中心的预训练通常依赖于2D到3D预训练任务,忽视了自动驾驶作为4D场景理解任务的时序特征。这里通过引入一个基于世界模型的自动驾驶4D表达学习框架"DriveWorld"来解决这一挑战,该框架能够够从多摄像头驱动视频中以时空方式进行预训练。具体来说,提出了一个动态记忆状态空间模型,它由一个动态记忆库模块组成,用于学习时空感知的潜在状态空间模型,并提供全面的场景上下文。此外,还引入了一个静态场景传播模块,用于学习空间感知的潜在场景上下文,并提供全面的场景上下文。此外,还引入了一个静态场景传播模块,用于学习空间感知的潜在场景上下文,并提供全面的场景上下文。这样,DriveWorld在各种自动驾驶任务上获得了令人鼓舞的结果。当使用OpenScene数据集进行预训练时,DriveWorld在各种自动驾驶任务上取得了令人鼓舞的结果。具体来说,DriveWorld在各种自动驾驶任务上取得了令人鼓舞的结果,并提高了mAP达到了7.5%的mAP,线地图中的IoU提高了3.0%,多目标跟踪中的AMOTA提高了5.0%,运动预测中的minADE降低了0.1m,占用预测中的IoU提高了3.0%,规划中的平均L2误差减少少于0.34m。
自动驾驶是一项复杂的任务,它依赖于全面的4d场景理解。这要求获取一个精健的时间空表示,能够处理涉及感知、预测和规划的任务。由于自然场景的随机性、环境的部分可观察性以及下游任务的多样性,学习时空表示具有挑战性。预训练在从大量数据中获取通用表示方面起着关键作用,使得能够构建出包含共同知识的基础模型。然而,自动驾驶中时空表示学习的预训练研究仍然相对有限。
我们的目标是利用世界模型来处理以视觉为中心的自动驾驶预训练中的4D表示。世界模型在表示代理环境的时空知识方面表现出色。在强化学习中,DreamerV1、DreamerV2和DreamerV3利用世界模型将代理的经验封装在预测模型中,在预测模型中进行广泛行为学习。MILE利用3D几何作为归纳偏差,直接从专家演示的视频中学习细腻的潜存在空间,在CARLA模拟器中构建世界模型。ContextWM和SWIM利用丰富的野外视频对世界模型进行预训练,以增强下游任务的高效学习。最近,GAIA-1和DriveDreamer构建了生成功能的世界模型,利用视频、文本和动作输入,使用扩散模型创造逼真的驾驶场景。与上述关于世界模型的先进工作不同,本文的方法主要侧重于利用世界模型学习自动驾驶预训练中的4D表示。
驾驶是一项有关本质上涉及到不确定性的斗争。在模糊的自动驾驶场景中,存在两种类 型的不确定性:偶然的不确定性,源于世界的随机性;以及认知不确定性,源于不完美的知识或信息。如何利用过去的经验来预测可能的未来状态,并估计自动驾驶中缺失的世界状态信息仍然是一个未解决的问题。本文探索了通过世界模型进行4D预训练以处理偶然的不确定性和认知不确定性。具体来说,设计了记忆状态空间模型,从两个方面减少自动驾驶中的不确定性。首先,为了处理偶然的不确定性,我们提出了动态记忆库模块,用于学习时空感知的潜在在动态状态。其次,为了缓解认知不确定性,我们提出了静态场景传播模块,用于学习空间感知的潜在静态特征,以提供全面的场景上下文。此外,引入了任务提示(Task Prompt),它利用语义线索作为提示,以自适应地调整特征提取网络,以适应不同的下游驾驶任务。
为了验证提出的4D预训练方法的性能,在nuScenes训练集和最近发布的大规模3D占用率数据集OpenScene上进行了预训练,随后在nuScenes训练集上进行了微调。实验结果表明,与2D ImageNet预训练相比,4D预训练和知识蒸馏算法相比,4D预训练方法具有显著优势。4D预训练算法在以视觉为中心的自动驾驶任务中表现出极大的改进,包括3D检测、多目标跟踪、在线建图、运动预测、占用率预测和规划。
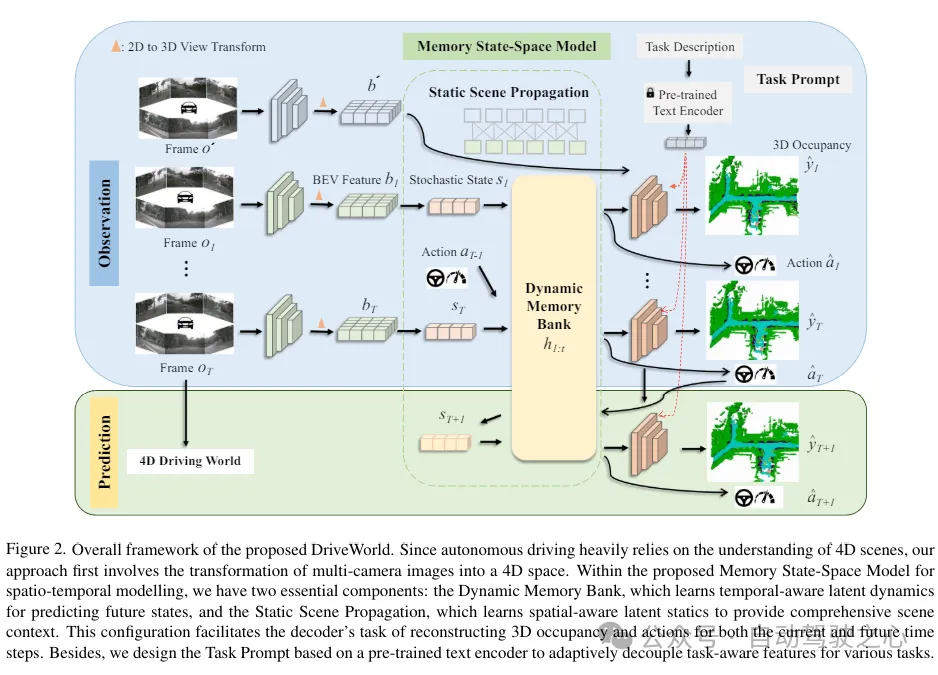
DriveWorld的总体框架如下所示,由于自动驾驶严重依赖于传统的理解,方法首先涉及将多摄像头图片转换为4D空间。在所提出的时空建模的记忆状态空间模型中,有两个基本组件:动态记忆库,它学习时间感知的潜存在动态以预测未来状态;以及静态场景传播,它学习空间感知的潜在静态特征以提供全面的场景上下文。这种配置有助于解码器为当前和未来任务感知特征。此外,基于预训练的文本编码器设计了任务prompt,以自适应地为各种任务解耦任务感知特征。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
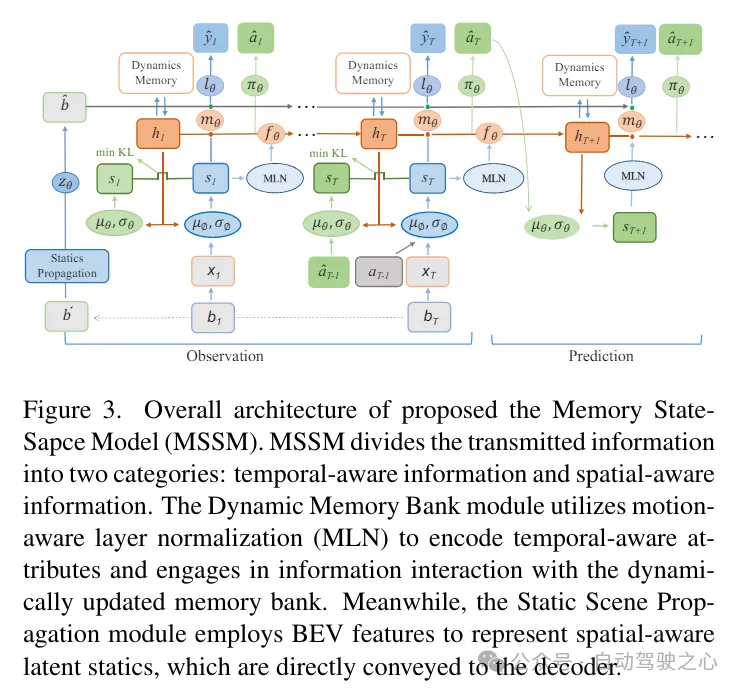
原文提出的记忆状态空间模型(MSSM)的总体架构。MSSM将传入的信息分为两类:时间感知信息和空间感知信息。动态记忆库模块利用运动感知层归一化(MLN)来编码时间感知属性,并与动态更新的记忆库进行信息交互。同时,静态场景传播模块利用BEV特征来表示空间感知的浸泡在静态信息,这些信息直接被传送到解码器。
虽然通过世界模型 设计的预训练任务使得时空表示的学习成为可能,但不同的下游任务侧重于不同的信息。例如,3D检测任务强调当前的空间感知信息,而未来预测任务则优先考虑时序感知信息。过分关注未来的信息,如车辆未来的位置,可能会对3D检测任务产生不利影响。为了解决这个问题,接下来的任务示例驱动的提取了“任务提示”的概念,为不同的头提供特定的线索,以指导它们提取任务感知特征。认识到不同任务之间存在的语义联系,利用大型语言模型来构建这些任务提示。
设计的预训练任务使得时空表示的学习成为可能,但不同的下游任务侧重于不同的信息。例如,3D检测任务强调当前的空间感知信息,而未来预测任务则优先考虑时序感知信息。过分关注未来的信息,如车辆未来的位置,可能会对3D检测任务产生不利影响。为了解决这个问题,接下来的任务示例驱动的提取了“任务提示”的概念,为不同的头提供特定的线索,以指导它们提取任务感知特征。认识到不同任务之间存在的语义联系,利用大型语言模型来构建这些任务提示。
DriveWorld的预训练目标涉及最小化后验和先验状态分布之间的差异(即Kullback-Leibler(KL)散度),以及最小化与过去和未来3D占用,即CrossEntropy损失(CE)和L1损失。这里描述了模型在T个时间步上观察输入,然后预测未来L步的3D占用和动作。DriveWorld的总损失函数是:
 Canva AI
Canva AI
Canva平台AI图片生成工具
 1374
查看详情
1374
查看详情

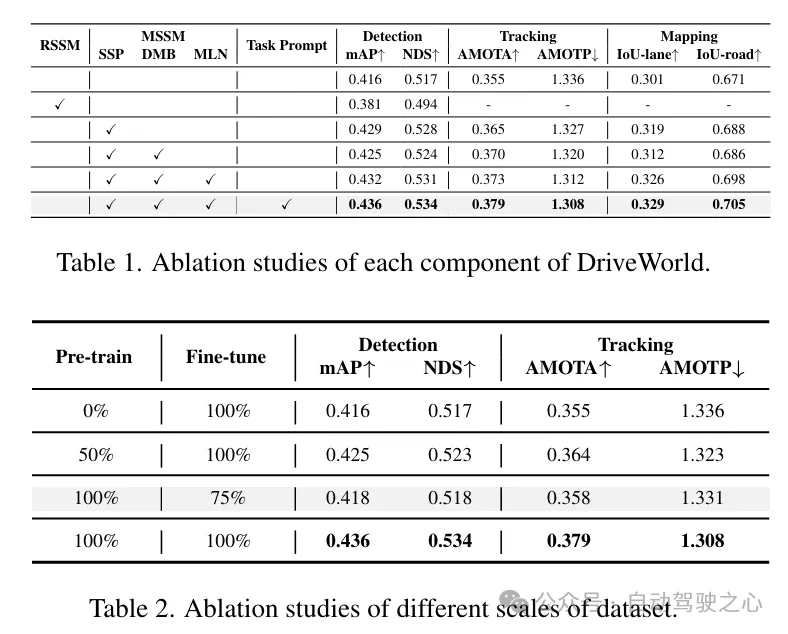
数据集。在自动驾驶数据集nuScenes 和最大规模的3D占用数据集OpenScene 上进行预训练,并在nuScenes上进行微调。评估设置与UniAD 相同。
预训练。与BEVFormer 和UniAD 一致,使用ResNet101-DCN 作为基础骨干网络。对于3D占用预测,设置了16 × 200 × 200的体素大小。学习率设置为2×10−4。默认情况下,预训练阶段包含24个epoch。
微调。在微调阶段,保留用于生成BEV特征的预训练编码器,并对下游任务进行微调。对于3D检测任务,我们使用了BEVFormer 框架,微调其参数而不冻结编码器,并进行了24个epoch的训练。对于其他自动驾驶任务,我们使用了UniAD 框架,并将我们微调后的BEVFormer权重加载到UniAD中,对所有任务遵循标准的20个epoch的训练协议。对于UniAD,我们遵循其实验设置,这包括在第一阶段训练6个epoch,在第二阶段训练20个epoch。实验使用8个NVIDIA Tesla A100 GPU进行。
Occ任务和BEV-OD任务上的提升一览:
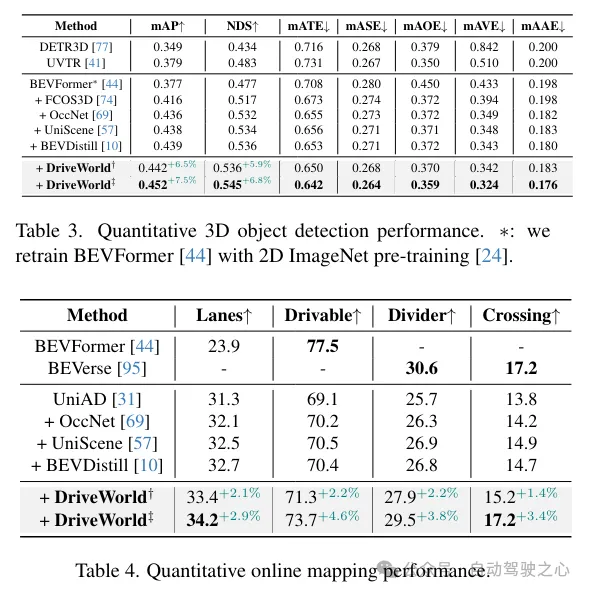
更多目标跟踪和规划任务性能提升一览:
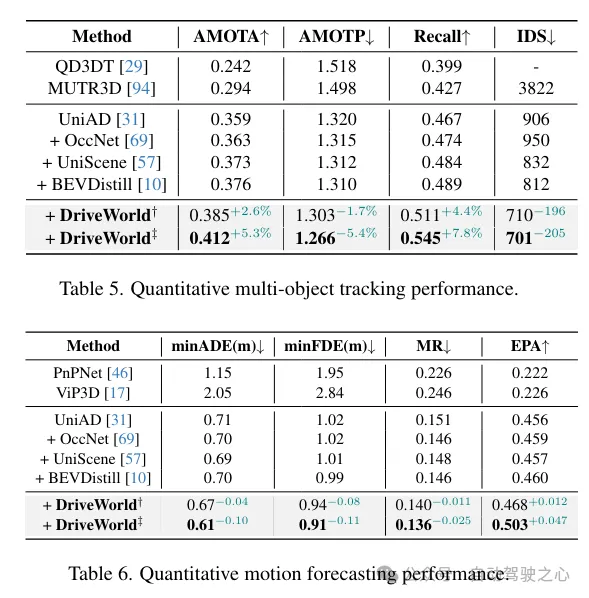
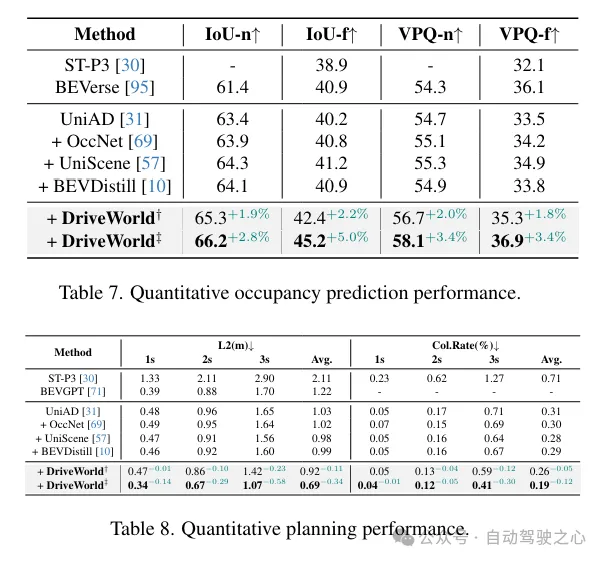
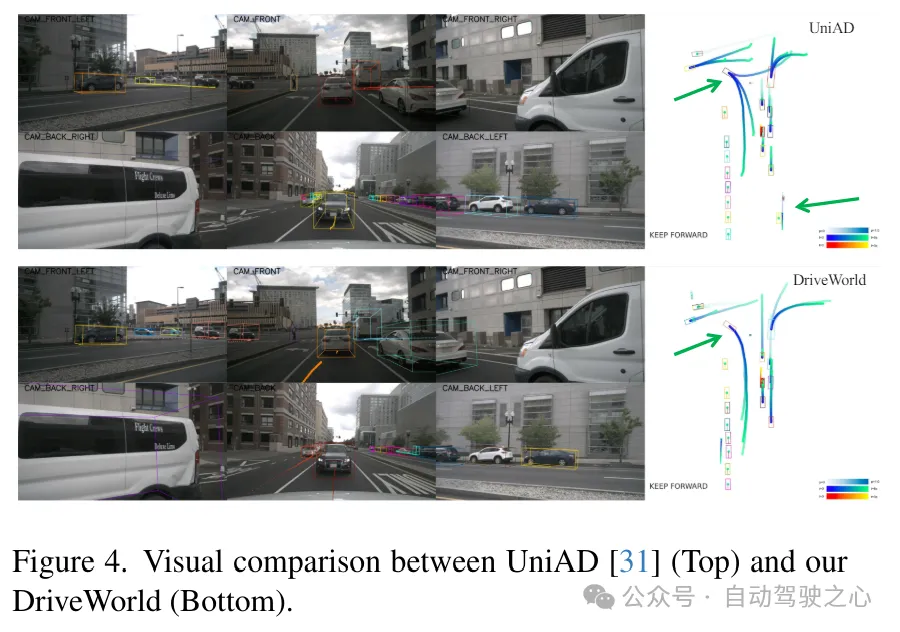
以上就是DriveWorld:一个预训练模型大幅提升检测+地图+跟踪+运动预测+Occ多个任务性能的详细内容,更多请关注其它相关文章!
# 驾驶技术
# 运营推广网站设计流程图
# 湖州塑料薄膜网站建设
# 广州小红书推广优化营销
# 碳水seo
# 怎样优化新网站链接设计
# 惠州网站优化找哪家公司
# 盐城网络营销推广seo
# 尉氏附近网站推广店地址
# 自助网站建设方案书范文
# seo重点学哪些方面
# 近期
# 模型
# 提高了
# 进行了
# 因其
# 较低
# 提出了
# 令人鼓舞
# 未来
# 多个
# 模拟器
# 自动驾驶
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
2025世界人工智能大会(上海)开幕式纪要
谷歌计划在上海举办开发者大会,重点关注机器学习和生成式AI领域
特斯拉人形机器人将于 7 月亮相上海 2025 世界人工智能大会
探索人工智能和物联网的动态融合
探索人工智能在物联网领域的影响与改变
1000万张照片训练AI模型 科学家找到水下定位新方法
AI时代,企业需要什么样的员工?
华为AI大模型将融入HarmonyOS 4
通用医疗人工智能如何革新医疗行业?
微软 Copilot 团队主管呼吁用户与 AI 交流时应使用恰当的礼貌用语
世界人工智能大会高合发表演讲,HiPhi Y即将全球上市
微软向美国政府提供GPT大模型,如何保证安全性?
云米Smart 2E AI立式空调开启预售:新三级能效,到手价3899元
腾讯机器狗进化:通过深度学习掌握自主决策能力
全国青少年无人机大赛重庆市选拔赛开赛 1252名中小学生参加
最大助力35公斤 外骨骼机器人或在养老、医疗领域“大展身手”
人工智能的变革之路:通过OpenAI的GPT-4漫游
实现人工智能和物联网的协同运作
AI+游戏首度大范围公布实际应用成果,AI全面来临还有多远?
爱设计PPT发布第二代AI一键生成PPT产品:智能、个性化、自动化
张勇对话多位诺奖得主 人工智能将无处不在
衡水市冀州中学机器人社团在世界机器人大赛中斩获佳绩
全场景智能车:智能无处不在|芯驰亮相世界人工智能大会
智能技术提高现代商业运营的7七种方式
谷歌StyleDrop在可控性上卷翻MidJourney,前GitHub CTO用AI颠覆编程
行业首发「超级智绘」AI故事集,TCL实业推进AI技术应用
微软新出热乎论文:Transformer扩展到10亿token
如何用Transformer BEV克服自动驾驶的极端情况?
揭晓2025年玻尔兹曼奖:Hopfield网络创始人荣获奖项
如何获得元宇宙的第一个属于自己的空间
实现MySQL数据锁定策略:解决并发冲突的J*a解决方案
Xreal AR 眼镜用投屏盒子 Beam 发布:分体式设计,到手 699 元
热点 | 人工智能黄金时代开启
人工智能自己玩自己
人工智能如何改变未来语言?
马克龙密会AI专家,法国加入全球人工智能竞赛
英伟达CEO宣称生成式AI已迎来“划时代时刻”
Meta发布音频AI模型,仅需2秒片段模拟真人语音
对艺术家拒绝置若罔闻,Stability AI 将推出适应多种画风的开源模型
出门问问亮相2025世界人工智能大会,展示AI CoPilot解决方案
“智能体动作生成技术”现身WAIC:游戏AI技术为机器人科创注入新动力
从数据中心到发电站:人工智能对能源使用的影响
城市在采用人工智能方面进展如何?
美的推出 AI 双视精准避障的自动集尘扫拖机器人 V12,售价仅为2999元
华为HarmonyOS 4:享流畅提升20%,AI大模型更智能一览无余
Meta Quest订阅服务每月7.99美元畅玩两款VR游戏应用
放弃自动驾驶,也是一种和解
AI拉动PCB发展|行业发现
世界水下机器人大赛:9国青年携手逐梦深蓝
此「错」并非真的错:从四篇经典论文入手,理解Transformer架构图「错」在何处
2024-05-10

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
